
基于时态差分法的强化学习:Sarsa和Q-learning
时态差分法(Temporal Difference, TD)是一类在强化学习中广泛应用的算法,用于学习价值函数或策略。Sarsa和Q-learning都是基于时态差分法的重要算法,用于解决马尔可夫决策过程(Markov Decision Process, MDP)中的强化学习问题。
下面是最简单的TD方法更新:
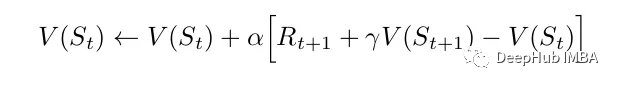
它只使用当前行动之后的奖励值和下一个状态的值作为目标。Sarsa(State-Action-Reward-State-Action)和Q-learning是都是基于时态差分法的强化学习方法。
Sarsa和Q-learning的区别
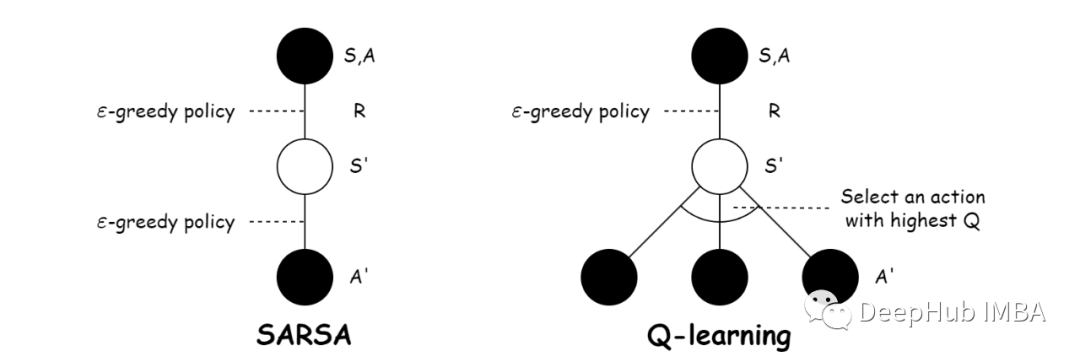
Sarsa代表State-Action-Reward-State-Action。是一种基于策略的方法,即使用正在学习的策略来生成训练数据。Q-learning是一种非策略方法它使用不同的策略为正在学习的值函数的策略生成训练数据。
https://avoid.overfit.cn/post/b7ecfa32ef354a4e9e0c9e2e5da7376d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号