MaskFormer:将语义分割和实例分割作为同一任务进行训练
目标检测和实例分割是计算机视觉的基本任务,在从自动驾驶到医学成像的无数应用中发挥着关键作用。目标检测的传统方法中通常利用边界框技术进行对象定位,然后利用逐像素分类为这些本地化实例分配类。但是当处理同一类的重叠对象时,或者在每个图像的对象数量不同的情况下,这些方法通常会出现问题。
诸如Faster R-CNN、Mask R-CNN等经典方法虽然非常有效,但由于其固有的固定大小输出空间,它们通常预测每个图像的边界框和类的固定数量,这可能与图像中实例的实际数量不匹配,特别是当不同图像的实例数量不同时。并且它们可能无法充分处理相同类的对象重叠的情况,从而导致分类不一致。
本文中将介绍Facebook AI Research在21年发布的一种超越这些限制的实例分割方法MaskFormer。可以看到从那时候开始,FB就对Mask和Transformer进行整合研究了。
1、逐像素分类和掩码分类的区别
逐像素分类
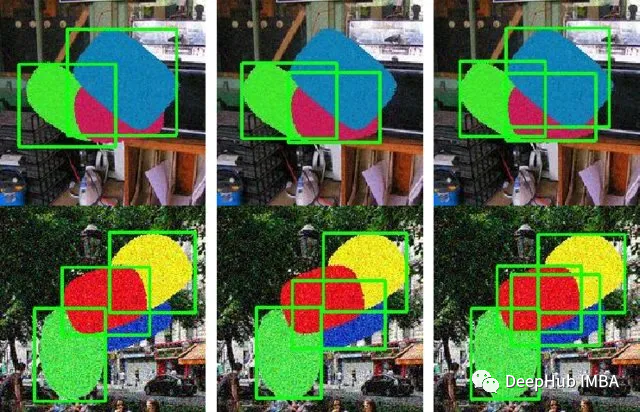
该方法指的是为图像中的每个像素分配一个类标签。在这种情况下,每个像素都被独立处理,模型根据该像素位置的输入特征预测该像素属于哪个类。对于边界清晰、定义明确的对象,逐像素分类可以非常准确。但是当感兴趣的对象具有复杂的形状,相互重叠或位于杂乱的背景中时,它可能会遇到困难,这可以解释为这些模型倾向于首先根据其空间边界来查看对象。
考虑一幅描绘多辆重叠汽车的图像。传统的实例分割模型(如逐像素模型)可能难以应对如下所示的情况。如果汽车重叠,这些模型可能会为整个重叠的汽车创建一个单一的并且是合并后的掩码。可能会把这个场景误认为是一辆形状奇怪的大型汽车,而不是多辆不同的汽车。

https://avoid.overfit.cn/post/3f38050c2a794e33ac9ee66642740fd3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号