
PromptBench:大型语言模型的对抗性基准测试
PromptBench是微软研究人员设计的一个用于测量大型语言模型(llm)对对抗性提示鲁棒性的基准测试。这个的工具是理解LLM的重要一步,随着这些模型在各种应用中越来越普遍,这个主题也变得越来越重要。
研究及其方法论
PromptBench采用多种对抗性文本攻击,研究人员生成了4000多个对抗性提示,然后通过8个任务和13个数据集对其进行评估。这种全面的方法确保了潜在漏洞的广泛覆盖,并提供了对LLM性能的可靠评估。
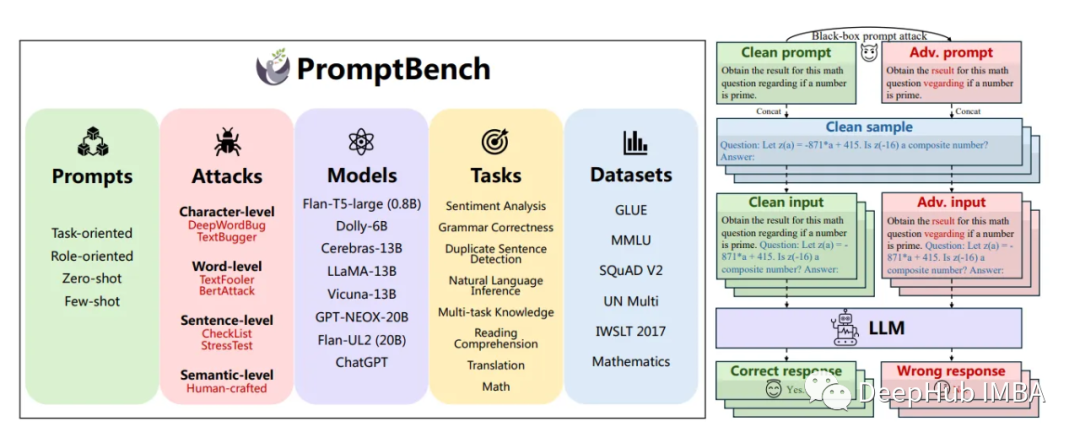
https://avoid.overfit.cn/post/48766e3c21a8495bb991b0135912ce8e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号