
LoRA:大模型的低秩自适应微调模型
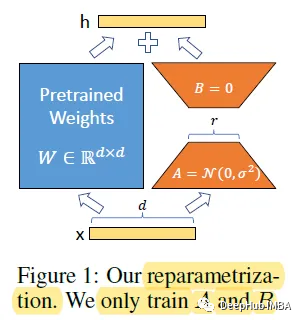
对于大型模型来说,重新训练所有模型参数的全微调变得不可行。比如GPT-3 175B,模型包含175B个参数吗,无论是微调训练和模型部署,都是不可能的事。所以Microsoft 提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预先训练好的模型权重,并将可训练的秩的分解矩阵注入到Transformer体系结构的每一层,从而大大减少了下游任务的可训练参数数量。
LoRA
完整文章:
https://avoid.overfit.cn/post/407a85d672384969848f8bc5cb9bc5fe

 浙公网安备 33010602011771号
浙公网安备 33010602011771号