
KNN中不同距离度量对比和介绍
k近邻算法KNN是一种简单而强大的算法,可用于分类和回归任务。他实现简单,主要依赖不同的距离度量来判断向量间的区别,但是有很多距离度量可以使用,所以本文演示了KNN与三种不同距离度量(Euclidean、Minkowski和Manhattan)的使用。
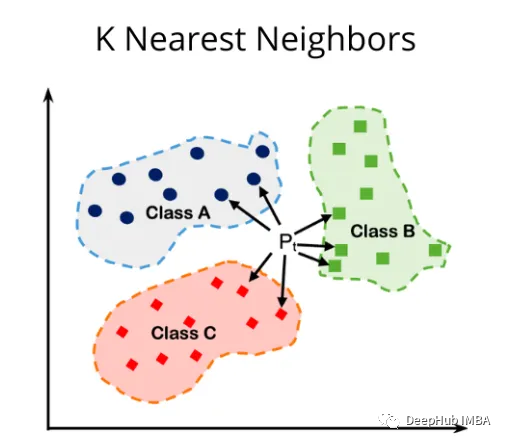
KNN算法概述
KNN是一种惰性、基于实例的算法。它的工作原理是将新样本的特征与数据集中现有样本的特征进行比较。然后算法选择最接近的k个样本,其中k是用户定义的参数。新样本的输出是基于“k”最近样本的多数类(用于分类)或平均值(用于回归)确定的。
有很多距离度量的算法,我们这里选取3个最常用度量的算法来进行演示:
https://avoid.overfit.cn/post/19200b7f741f4686a9b6ada15552d1ba

 浙公网安备 33010602011771号
浙公网安备 33010602011771号