使用Pytorch实现对比学习SimCLR 进行自监督预训练
SimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。
SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记数据集上进行最少的微调。
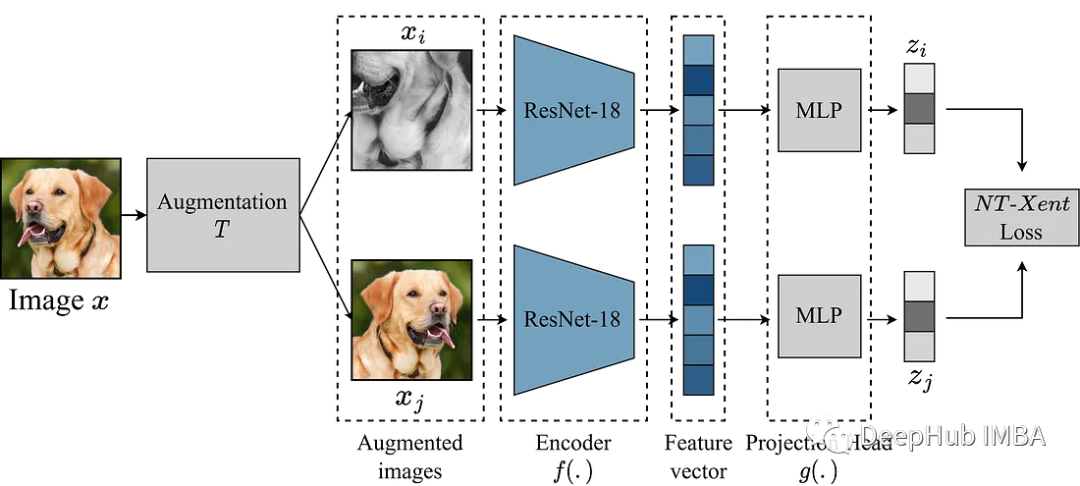
SimCLR 主要思想是通过增强模块 T 将图像与同一图像的其他增强版本进行对比,从而学习图像的良好表示。这是通过通过编码器网络 f(.) 映射图像,然后进行投影来完成的。 head g(.) 将学习到的特征映射到低维空间。 然后在同一图像的两个增强版本的表示之间计算对比损失,以鼓励对同一图像的相似表示和对不同图像的不同表示。
本文我们将深入研究 SimCLR 框架并探索该算法的关键组件,包括数据增强、对比损失函数以及编码器和投影的head 架构。
我们这里使用来自 Kaggle 的垃圾分类数据集来进行实验
完整文章:
https://avoid.overfit.cn/post/e105b37642c241b080ae514778b86a6e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号