
少样本学习综述:技术、算法和模型
机器学习最近取得了很大的进展,但仍然有一个主要的挑战:需要大量的标记数据来训练模型。
有时这种数据在现实世界中是无法获得的。以医疗保健为例,我们可能没有足够的x光扫描来检查一种新的疾病。但是通过少样本学习可以让模型只从几个例子中学习到知识!
所以少样本学习(FSL)是机器学习的一个子领域,它解决了只用少量标记示例学习新任务的问题。FSL的全部意义在于让机器学习模型能够用一点点数据学习新东西,这在收集一堆标记数据太昂贵、花费太长时间或不实用的情况下非常有用。
少样本学习方法
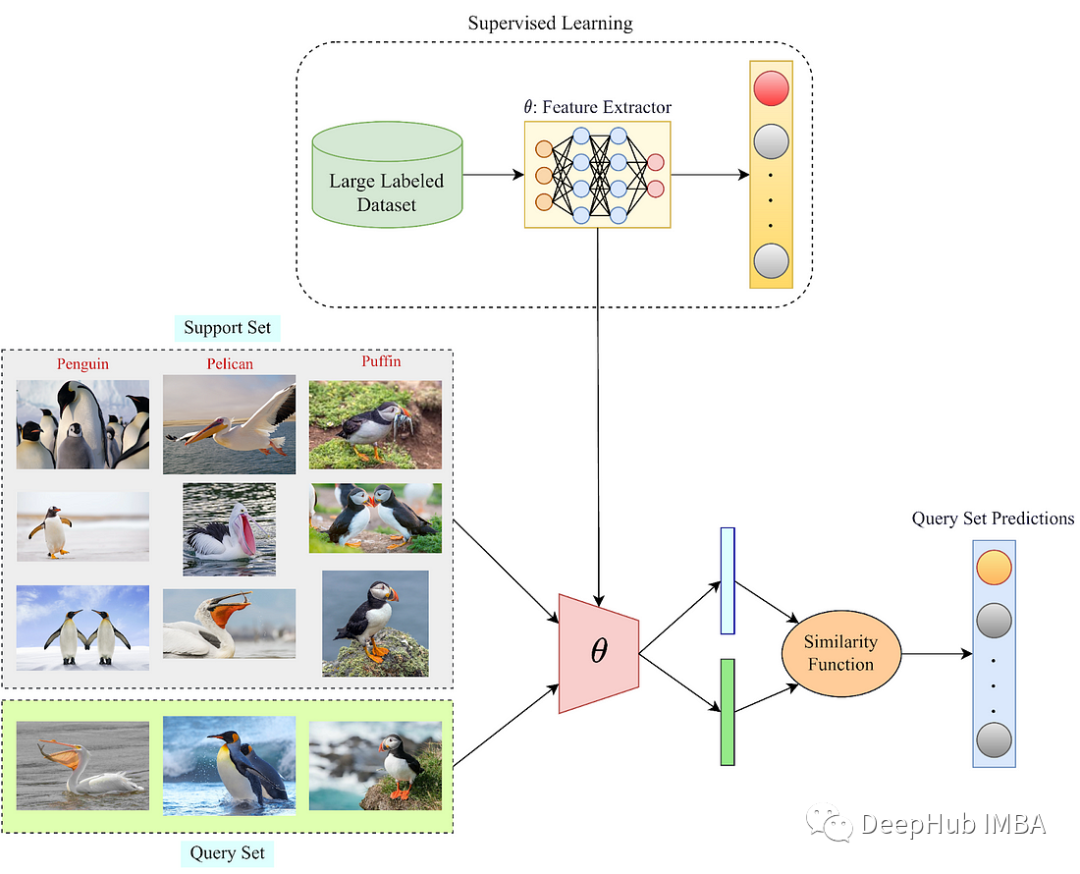
支持样本/查询集:使用少量图片对查询集进行分类。
少样本学习中有三种主要方法需要了解:元学习、数据级和参数级。
- 元学习:元学习包括训练一个模型,学习如何有效地学习新任务;
- 数据级:数据级方法侧重于增加可用数据,以提高模型的泛化性能;
- 参数级:参数级方法旨在学习更健壮的特征表示,以便更好地泛化到新任务中
完整文章:
https://avoid.overfit.cn/post/8dd0bcbeec7243f5a7da1e445d66b57f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号