
使用JAX实现完整的Vision Transformer
本文将展示如何使用JAX/Flax实现Vision Transformer (ViT),以及如何使用JAX/Flax训练ViT。
Vision Transformer
在实现Vision Transformer时,首先要记住这张图。
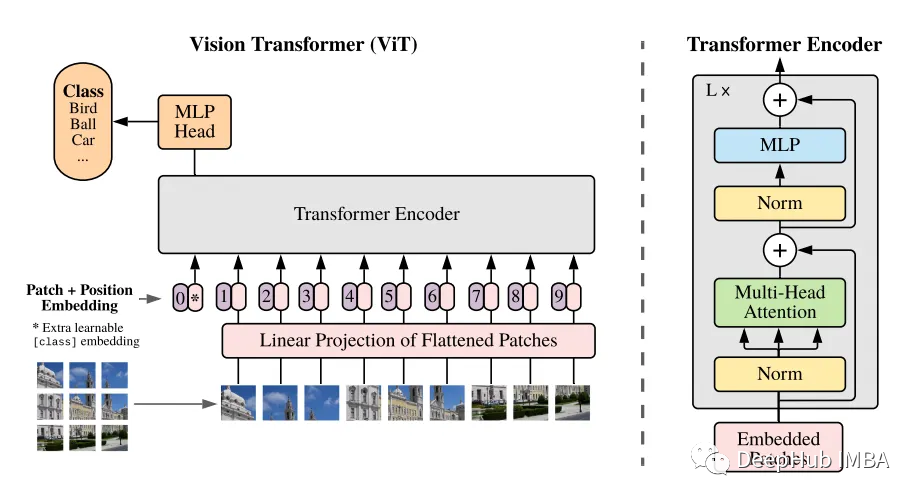
以下是论文描述的ViT执行过程。
从输入图像中提取补丁图像,并将其转换为平面向量。
投影到 Transformer Encoder 来处理的维度
预先添加一个可学习的嵌入([class]标记),并添加一个位置嵌入。
由 Transformer Encoder 进行编码处理
使用[class]令牌作为输出,输入到MLP进行分类。
完整文章:
https://avoid.overfit.cn/post/926b7965ba56464ba151cbbfb6a98a93

 浙公网安备 33010602011771号
浙公网安备 33010602011771号