不平衡数据集的建模的技巧和策略
不平衡数据集是指一个类中的示例数量与另一类中的示例数量显著不同的情况。 例如在一个二元分类问题中,一个类只占总样本的一小部分,这被称为不平衡数据集。类不平衡会在构建机器学习模型时导致很多问题。
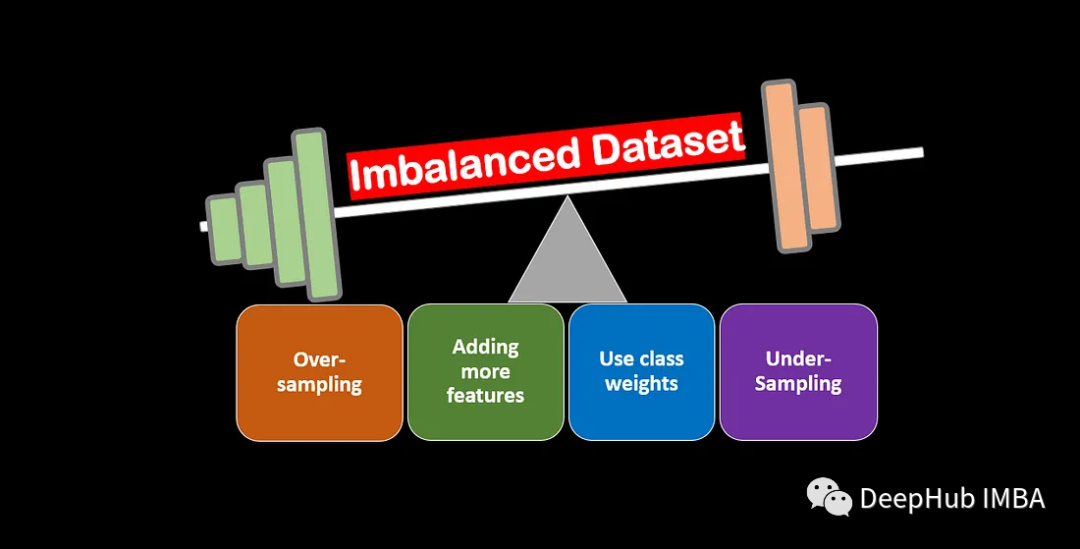
不平衡数据集的主要问题之一是模型可能会偏向多数类,从而导致预测少数类的性能不佳。 这是因为模型经过训练以最小化错误率,并且当多数类被过度代表时,模型倾向于更频繁地预测多数类。 这会导致更高的准确率得分,但少数类别得分较低。
另一个问题是,当模型暴露于新的、看不见的数据时,它可能无法很好地泛化。 这是因为该模型是在倾斜的数据集上训练的,可能无法处理测试数据中的不平衡。
在本文中,我们将讨论处理不平衡数据集和提高机器学习模型性能的各种技巧和策略。 将涵盖的一些技术包括重采样技术、代价敏感学习、使用适当的性能指标、集成方法和其他策略。 通过这些技巧,可以为不平衡的数据集构建有效的模型。
完整文章:
https://avoid.overfit.cn/post/774ca6891f26470093970c074afceede

 浙公网安备 33010602011771号
浙公网安备 33010602011771号