YOLO家族系列模型的演变:从v1到v8(上)
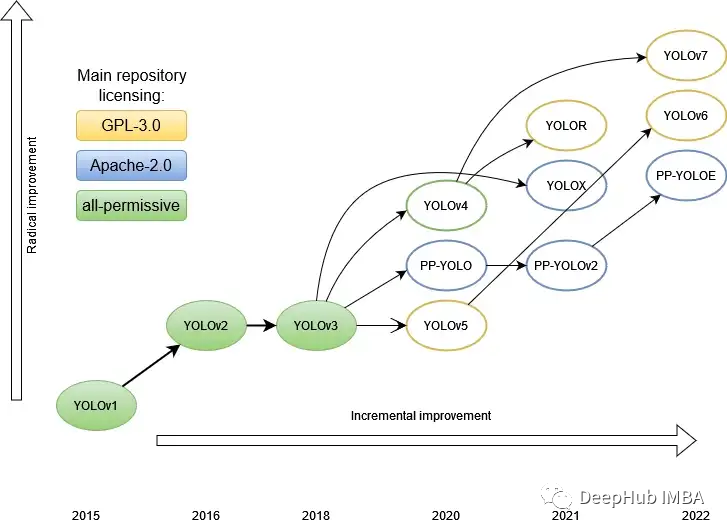
YOLO V8已经在本月发布了,我们这篇文章的目的是对整个YOLO家族进行比较分析。了解架构的演变可以更好地知道哪些改进提高了性能,并且明确哪些版本是基于那些版本的改进,因为YOLO的版本和变体的命名是目前来说最乱的,希望看完这篇文章之后你能对整个家族有所了解。
在YOLO出现之前,检测图像中对象的主要方法是使用不同大小的滑动窗口依次通过原始图像的各个部分,以便分类器显示图像的哪个部分包含哪个对象。这种方法是合乎逻辑的,但非常迟缓。
经过了一段时间的发展,一个特殊的模型出现了:它可以暴露感兴趣的区域,但即便是这样还是太多了。速度最快的算法Faster R-CNN平均在0.2秒内处理一张图片,也就是每秒5帧。
在以前的方法中,原始图像的每个像素都需要被神经网络处理几百次甚至几千次。每次这些像素都通过同一个神经网络进行相同的计算。有没有可能做些什么来避免重复同样的计算?
事实证明这是可能的。但是为了这个,我们必须稍微重新定义这个问题。如果早些时候它是一个分类任务,那么现在它已经变成了一个回归任务。
完整文章:
https://avoid.overfit.cn/post/2a446d31ab824cde8f35b2aef7104984

 浙公网安备 33010602011771号
浙公网安备 33010602011771号