
论文推荐:Rethinking Attention with Performers
重新思考的注意力机制,Performers是由谷歌,剑桥大学,DeepMind,和艾伦图灵研究所发布在2021 ICLR的论文已经超过500次引用
传统的Transformer的使用softmax 注意力,具有二次空间和时间复杂度。Performers是Transformer的一个变体,它利用一种新颖的通过正交随机特征方法 (FAVOR+) 快速注意力来有效地模拟 softmax 之外的可核化注意力机制来近似 softmax 注意力。
背景知识
传统Transformer由于softmax attention的存在,具有二次的空间和时间复杂度:
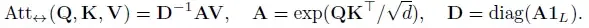
为解决上述问题,Performers提出了一些研究建议。
标准稀疏化技术
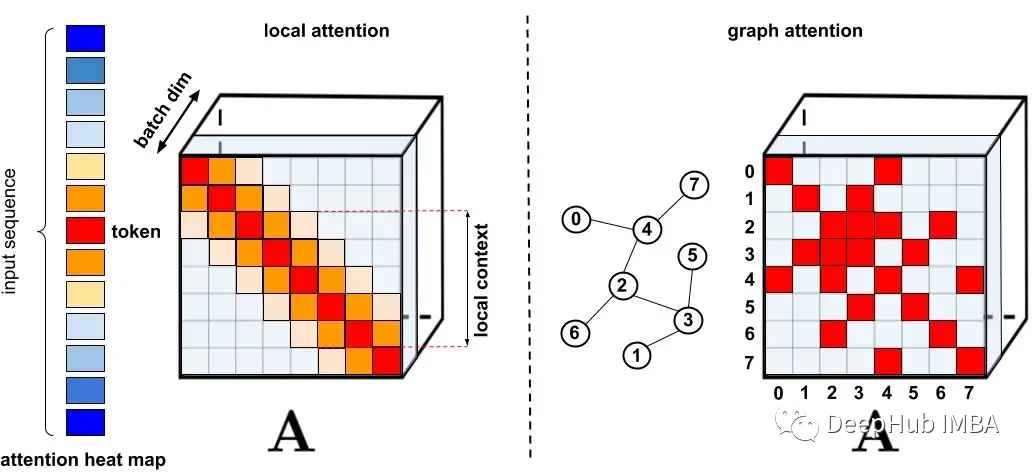
标准稀疏化技术。
左图:稀疏模式示例,其中令牌仅关注附近的其他令牌。
右图:在图注意力网络中,令牌仅关注图中的邻居,这些节点应该比其他节点具有更高的相关性。
完整文章
https://avoid.overfit.cn/post/4e5c93d291d94bd9ba1d06e0d8c0f4c9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号