
5个时间序列预测的深度学习模型对比总结:从模拟统计模型到可以预训练的无监督模型
时间序列预测在最近两年内发生了巨大的变化,尤其是在kaiming的MAE出现以后,现在时间序列的模型也可以用类似MAE的方法进行无监督的预训练
Makridakis M-Competitions系列(分别称为M4和M5)分别在2018年和2020年举办(M6也在今年举办了)。对于那些不了解的人来说,m系列得比赛可以被认为是时间序列生态系统的一种现有状态的总结,为当前得预测的理论和实践提供了经验和客观的证据。
2018年M4的结果表明,纯粹的“ ML”方法在很大程度上胜过传统的统计方法,这在当时是出乎意料的。在两年后的M5[1]中,最的高分是仅具有“ ML”方法。并且所有前50名基本上都是基于ML的(大部分是树型模型)。这场比赛看到了LightGBM(用于时间序列预测)以及Amazon's Deepar [2]和N-Beats [3]的首次亮相。N-Beats模型于2020年发布,并且优于M4比赛的获胜者3%!
最近的 Ventilator Pressure Prediction比赛展示了使用深度学习方法来应对实时时间序列挑战的重要性。比赛的目的是预测机械肺内压力的时间顺序。每个训练实例都是自己的时间序列,因此任务是一个多个时间序列的问题。获胜团队提交了多层深度架构,其中包括LSTM网络和Transformer 块。
在过去的几年中,许多著名的架构已经发布,如MQRNN和DSSM。所有这些模型都利用深度学习为时间序列预测领域贡献了许多新东西。除了赢得Kaggle比赛,还给我们带来了更多的进步比如:
- 多功能性:将模型用于不同任务的能力。
- MLOP:在生产中使用模型的能力。
- 解释性和解释性:黑盒模型并不那么受欢迎。
本文讨论了5种专门研究时间序列预测的深度学习体系结构,论文是:
- N-BEATS (ElementAI)
- DeepAR (Amazon)
- Spacetimeformer [4]
- Temporal Fusion Transformer or TFT (Google) [5]
- TSFormer(时间序列中的MAE)[7]
N-BEATS
这种模式直接来自于(不幸的)短命的ElementAI公司,该公司是由Yoshua Bengio联合创立的。顶层架构及其主要组件如图1所示:
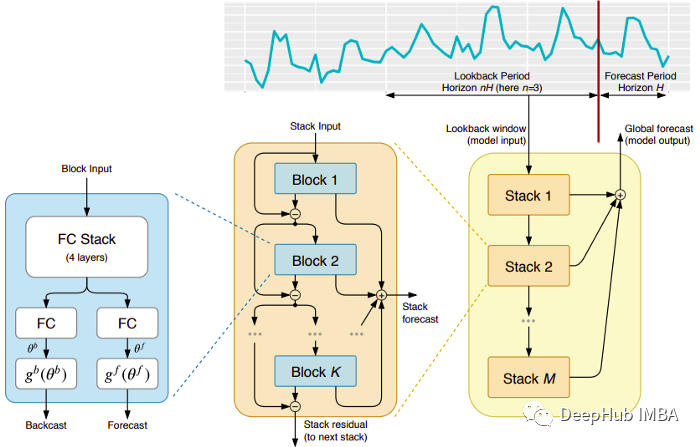
N-BEATS是一个纯粹的深度学习架构,它基于集成前馈网络的深度堆栈,这些网络也通过正向和反向的相互连接进行堆叠。
每一个块只对由前一个的backcast产生的残差进行建模,然后基于该误差更新预测。该过程模拟了拟合ARIMA模型时的Box-Jenkins方法。
以下是该模型的主要优势:
表达性强且易于使用:该模型易于理解,具有模块化结构,它被设计为需要最小的时间序列特征工程并且不需要对输入进行缩放。
该模型具有对多个时间序列进行概括的能力。换句话说,分布略有不同的不同时间序列可以用作输入。在N-BEATS中是通过元学习实现的。元学习过程包括两个过程:内部学习过程和外部学习过程。内部学习过程发生在块内部,并帮助模型捕获局部时间特征。外部学习过程发生在堆叠层,帮助模型学习所有时间序列的全局特征。
双重残差叠加:残差连接和叠加的想法是非常巧妙的,它几乎被用于每一种类型的深度神经网络。在N-BEATS的实现中应用了相同的原理,但有一些额外的修改:每个块有两个残差分支,一个运行在回看窗口(称为backcast),另一个运行在预测窗口(称为forecast)。
每一个连续的块只对由前一个块重建的backcast产生的残差进行建模,然后基于该误差更新预测。这有助于模型更好地逼近有用的后推信号,同时最终的堆栈预测预测被建模为所有部分预测的分层和。就是这个过程模拟了ARIMA模型的Box-Jenkins方法。
可解释性:模型有两种变体,通用的和可解释性的。在通用变体中,网络任意学习每个块的全连接层的最终权值。在可解释的变体中,每个块的最后一层被删除。然后将后推backcast和预测forecast分支乘以模拟趋势(单调函数)和季节性(周期性循环函数)的特定矩阵。
注意:原始的N-BEATS实现只适用于单变量时间序列。
DeepAR
结合深度学习和自回归特性的新颖时间序列模型。图2显示了DeepAR的顶层架构:
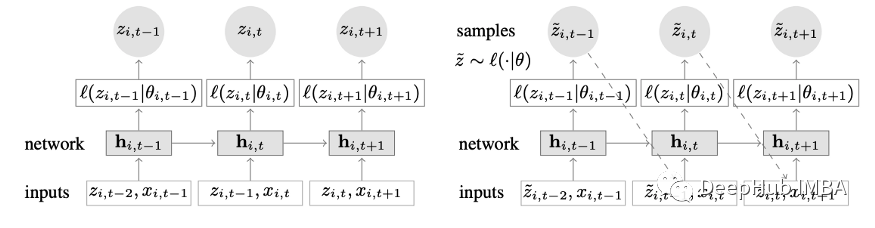
以下是该模型的主要优势:
完整文章:
https://avoid.overfit.cn/post/1213c27fc4174754bdbc2cec515c1732

 浙公网安备 33010602011771号
浙公网安备 33010602011771号