机器学习中训练和验证指标曲线图能告诉我们什么?
我们在训练和验证模型时都会将训练指标保存成起来制作成图表,这样可以在结束后进行查看和分析,但是你真的了解这些指标的图表的含义吗?
在本文中将对训练和验证可能产生的情况进行总结并介绍这些图表到底能为我们提供什么样的信息。
让我们从一些简单的代码开始,以下代码建立了一个基本的训练流程框架。
场景 1 - 模型似乎可以学习,但在验证或准确性方面表现不佳
无论超参数如何,模型 Train loss 都会缓慢下降,但 Val loss 不会下降,并且其 Accuracy 并不表明它正在学习任何东西。
比如在这种情况下,二进制分类的准确率徘徊在 50% 左右。
class Scenario_1_Model_1(nn.Module):def __init__(self, in_features=30, out_features=2):super().__init__()self.lin1 = nn.Linear(in_features, out_features)def forward(self, x):x = self.lin1(x)return xget_data_train_and_show(Scenario_1_Model_1(), lr=0.001, break_it=True)
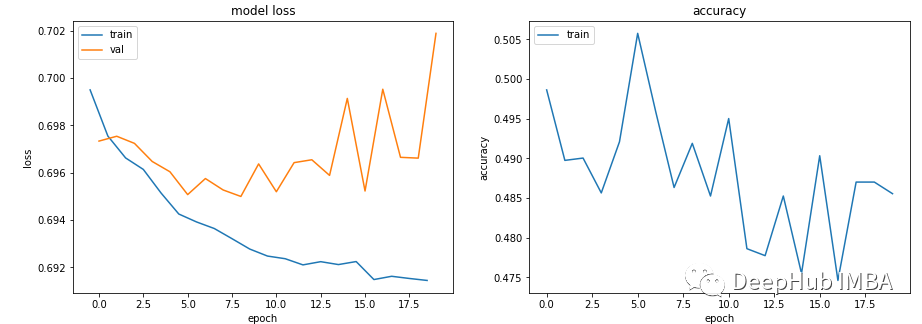
数据中没有足够的信息来允许‘学习’,训练数据可能没有包含足够的信息来让模型“学习”。
在这种情况下(代码中训练数据是随机数据),这意味着它无法学习任何实质内容。
数据必须有足够的信息可以从中学习。EDA 和特征工程是关键!模型学习可以学到的东西,而不是不是编造不存在的东西。
场景 2 — 训练、验证和准确度曲线都非常不稳
完整文章:
https://avoid.overfit.cn/post/5f52eb0868ce41a3a847783d5e87a04f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号