深入了解 TabNet :架构详解和分类代码实现
Google发布的TabNet是一种针对于表格数据的神经网络,它通过类似于加性模型的顺序注意力机制(sequential attention mechanism)实现了instance-wise的特征选择,还通过encoder-decoder框架实现了自监督学习。
表格数据是日常中用到的最多的数据类型。例如信用卡的欺诈检测:我们提取交易、身份、产品和网络属性(并将它们放入一个大的特征表中,不同的机器学习模型可以轻松地使用这些特征进行训练和推理。基于决策树的模型(例如随机森林或 XGBoost)是处理表格数据的首选算法,因为它们的性能、可解释性、训练速度和鲁棒性都是目前最好的。

但是神经网络在许多领域被认为是最先进的,并且在具有最少特征工程的大型数据集上表现特别好。我们的许多客户都有大量交易量,深度学习是提高模型在欺诈检测方面性能的潜在途径。
在这篇文章中,我们将深入研究称为 TabNet (Arik & Pfister (2019)) 的神经网络架构,该架构旨在可解释并与表格数据很好地配合使用。在解释了它背后的关键构建块和想法之后,您将了解如何在 TensorFlow 中实现它以及如何将其应用于欺诈检测数据集,如果你使用Pytorch也不用担心,TabNet有各种深度学习框架的实现。
TabNet
TabNet 使用 Sequential Attention 的思想模仿决策树的行为。简单地说,可以将其视为一个多步神经网络,在每一步应用两个关键操作:
- Attentive Transformer 选择最重要的特征在下一步处理
- 通过Feature Transformer 将特征处理成更有用的表示
模型最后使用Feature Transformer 的输出稍后用于预测。TabNet 同时使用 Attentive 和 Feature Transformers,能够模拟基于树的模型的决策过程。例如以下的成人人口普查收入数据集的预测,模型能够选择和处理对手头任务最有用的特征,从而提高可解释性和学习能力。
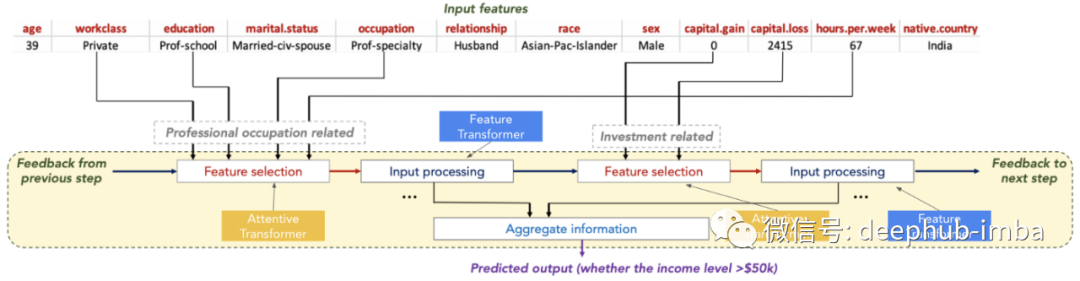
Attentive 和 Feature Transformer 的关键构建块是所谓的 Feature Blocks,所以让我们先来探索一下。
Feature Block 特征块
Feature Block由顺序应用的全连接(FC)或密集层和批量归一化(BN)组成。此外,对于Feature Transformer ,输出通过 GLU 激活层传递。
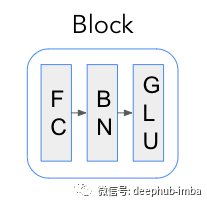
GLU(与 sigmoid 门相反)的主要功能是允许隐藏单元更深入地传播到模型中并防止梯度爆炸或消失。
def glu(x, n_units=None):
"""Generalized linear unit nonlinear activation."""
return x[:, :n_units] * tf.nn.sigmoid(x[:, n_units:])
完整文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号