开启深度强化学习之路:Deep Q-Networks简介和代码示例
强化学习是机器学习领域的热门子项。由于 OpenAI 和 AlphaGo 等公司的最新突破,强化学习引起了游戏行业许多人的注意。我们今天以Hill Climb Racing这款经典的游戏来介绍DQN的整个概念,Hill Climb Racing需要玩家在不同的地形上驾驶不同的车辆,驾驶距离越长得分越高。
在本篇文章中将通过这个游戏的示例来介绍 Deep Q-Networks 的整个概念,但是因为没有环境所以我们会将其分解成2个独立目标分别实现。如果曾经接触过此类游戏,你可能已经观察到游戏的两个主要目标:1、不要碰撞,2、保持前进。
我们将这两个目标分解成我们的需要的做动作:1、保持平衡,2、爬坡,当然还有一些附加项,例如吃分获取奖励,但是这个并不是我们的主要目标。
在我们深入解决这些问题之前,首先介绍一下解强化学习和DQN的基础知识。
我们先快速介绍一下什么是强化学习,在这种学习中行为主体对环境所做的行动会根据其结果得到奖励。奖励会影响主体(代理、智能体)未来的行为。
- 有利的行动,更多的奖励(积极的)。
- 不利的行动,较少的奖励或者惩罚(在某些情况下是负面的)。
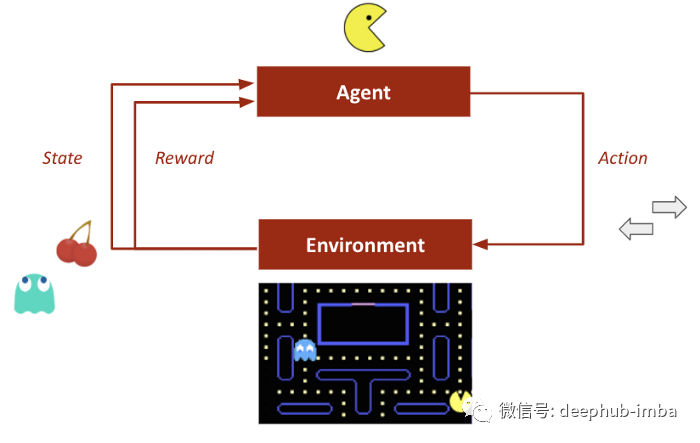
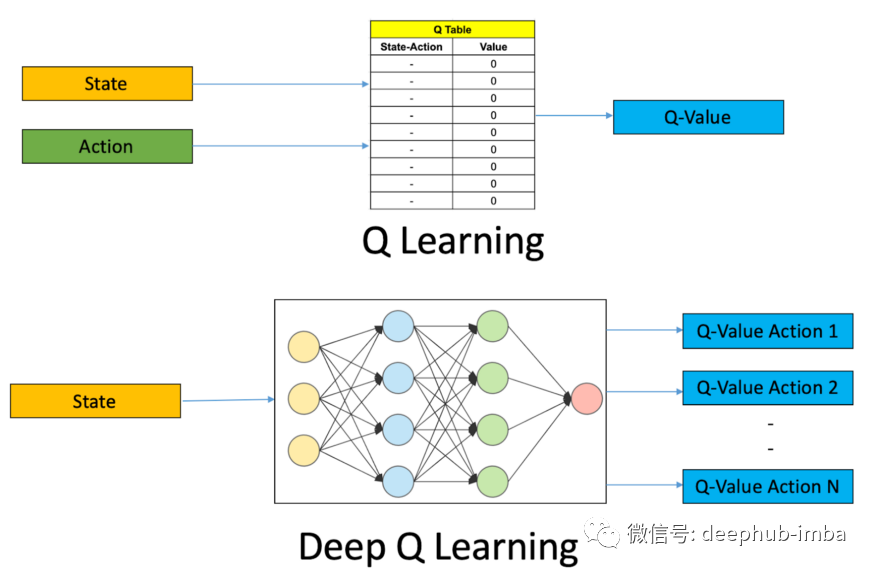
Deep Q-Learning 算法是深度强化学习的核心概念之一。神经网络将输入状态映射到(动作,Q 值)对。
- 动作Action:代理执行的对环境进行后续更改的活动。
- 环境Environment:模型工作的整个状态空间。
- 奖励Rewards:为模型提供的每个动作的反馈。
- Q 值Q-value:估计的最优未来值。
Q-Learning 和 Deep Q-Networks 是无模型算法,因为它们不创建环境转换函数的模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号