BERT 模型的知识蒸馏: DistilBERT 方法的理论和机制研究
如果你曾经训练过像 BERT 或 RoBERTa 这样的大型 NLP 模型,你就会知道这个过程是极其漫长的。由于其庞大的规模,训练此类模型可能会持续数天。当需要在小型设备上运行它们时,就会发现正在以巨大的内存和时间成本为日益增长的性能付出代价。
有一些方法可以减轻这些痛苦并且对模型的性能影响很小,这种技术称为蒸馏。在本文中,我们将探讨 DistilBERT [1] 方法背后的机制,该方法可用于提取任何类似 BERT 的模型。
首先,我们将讨论一般的蒸馏以及我们为什么选择 DistilBERT 的方法,然后如何初始化这个过程,以及在蒸馏过程中使用的特殊损失,最后是一些需要注意的细节。
简单介绍DistilBERT
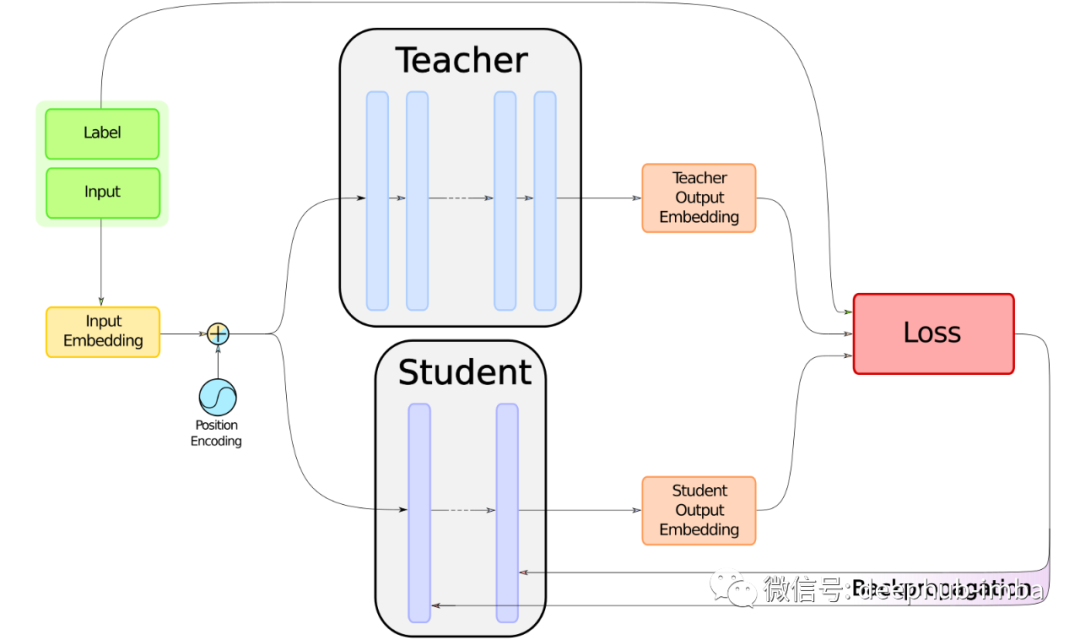
什么是知识蒸馏?
蒸馏的概念是相当直观的:它是训练一个小的学生模型,模仿一个更大的教师模型并尽可能接近的过程。如果我们只将他用在集群上进行机器学习模型的微调时,那么知识蒸馏的作用并不大。但是当我们想要将一个模型移植到更小的硬件上时,比如一台有限的笔记本电脑或手机,知识蒸馏的好处是显而易见的,因为蒸馏的模型在保证性能的情况下,参数更少、运行得更快、占用的空间更少。
BERT蒸馏的必要性
基于bert的模型在NLP中非常流行,因为它们最初是在[2]中引入的。随着性能的提高,出现了很多很多的参数。准确地说,BERT的参数超过了1.1亿,这里还没有讨论BERT-large。对知识蒸馏的需要是明显的,因为 BERT 非常通用且性能良好,还有就是后来的模型基本上以相同的方式构建,类似于 RoBERTa [3],所以能够正确的提取和使用BERT里面包含的内容可以让我们达到一举两得的目的。
DistilBERT 方法
第一篇关于 BERT 提炼的论文是给我们灵感的论文,即 [1]。但是其他方法也会陆续介绍,例如 [4] 或 [5],所以我们很自然地想知道为什么将自己限制在 DistilBERT 上。答案有三点:第一,它非常简单,是对蒸馏的一个很好的介绍;其次,它带来了良好的结果;第三,它还允许提炼其他基于 BERT 的模型。
DistilBERT 的蒸馏有两个步骤,我们将在下面详细介绍。
完整文章请访问 : BERT 模型的知识蒸馏: DistilBERT 方法的理论和机制研究

 浙公网安备 33010602011771号
浙公网安备 33010602011771号