在Python中使用K-Means聚类和PCA主成分分析进行图像压缩
各位读者好,在这片文章中我们尝试使用sklearn库比较k-means聚类算法和主成分分析(PCA)在图像压缩上的实现和结果。 压缩图像的效果通过占用的减少比例以及和原始图像的差异大小来评估。 图像压缩的目的是在保持与原始图像的相似性的同时,使图像占用的空间尽可能地减小,这由图像的差异百分比表示。 图像压缩需要几个Python库,如下所示:
# image processing
from PIL import Image
from io import BytesIO
import webcolors
# data analysis
import math
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
from importlib import reload
from mpl_toolkits import mplot3d
import seaborn as sns
# modeling
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.preprocessing import MinMaxScaler探索图像

每个颜色通道的图像
图像中的每个像素都可以表示为三个0到255之间的8位无符号(正)整数,或缩放为三个0到1之间的无符号(正)浮点数。这三个值分别指定红色,绿色,蓝色的强度值,这通常称为RGB编码。 在此文章中,我们使用了220 x 220像素的lena.png,这是在图像处理领域广泛使用的标准测试图像。
ori_img = Image.open("images/lena.png")
ori_img
原始图像
X = np.array(ori_img.getdata())
ori_pixels = X.reshape(*ori_img.size, -1)
ori_pixels.shape图像储存方式是形状为(220、220、3)的3D矩阵。 前两个值指定图像的宽度和高度,最后一个值指定RBG编码。 让我们确定图像的其他属性,即图像大小(以千字节(KB)为单位)和原色的数量。
def imageByteSize(img):
img_file = BytesIO()
image = Image.fromarray(np.uint8(img))
image.save(img_file, 'png')
return img_file.tell()/1024
ori_img_size = imageByteSize(ori_img)
ori_img_n_colors = len(set(ori_img.getdata()))
lena.png的原始图像大小为86 KB,并具有37270种独特的颜色。 因此,我们可以说lena.png中的两个像素具有相同的精确RGB值的可能性很小。
接下来,让我们计算图像的差异作为压缩结果的基准。
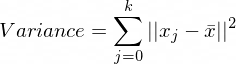
ori_img_total_variance = sum(np.linalg.norm(X - np.mean(X, axis = 0), axis = 1)**2)我们得到方差为302426700.6427498。 但是我们无法解释方差本身的价值。 我们稍后将在K-Means聚类中使用它。
完整内容请访问:https://imba.deephub.ai/p/3e37ea307a2211ea90cd05de3860c663


 浙公网安备 33010602011771号
浙公网安备 33010602011771号