神奇的Batch Normalization 仅训练BN层会发生什么
您可能会感到惊讶,但这是有效的。
最近,我阅读了arXiv平台上的Jonathan Frankle,David J. Schwab和Ari S. Morcos撰写的论文“Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs”。 这个主意立刻引起了我的注意。 到目前为止,我从未将批标准化(BN)层视为学习过程本身的一部分,仅是为了帮助深度网络实现优化和提高稳定性。 经过几次实验,我发现我错了。 在下文中,我将展示我复制的论文的结果以及从中学到的东西。
更详细地讲,我使用Tensorflow 2 Keras API成功复现了论文的主要实验,得出了相似的结论。 也就是说,ResNets可以通过仅训练批标准化层的gamma(γ)和beta(β)参数在CIFAR-10数据集中获得不错的结果。 从数字上讲,我使用ResNet-50、101和152架构获得了45%,52%和50%的Top-1精度,这远非完美,但也并非无效。
在下文中,我概述了批标准化概念以及其常见解释。 然后,我分享我使用的代码以及从中获得的结果。 最后,我对实验结果进行评论,并对其进行分析。
批标准化 Batch Normalization
简而言之,批标准化层估计其输入的平均值(μ)和方差(σ²),并产生标准化的输出,即平均值和单位方差为零的输出。 在实验中,此技术可显着提高深度网络的收敛性和稳定性。 此外,它使用两个参数(γ和β)来调整和缩放其输出。
x作为输入,z作为输出,z由以下公式给出:
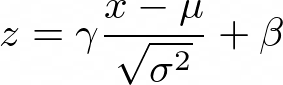
图1:批标准化表达式
根据输入数据估算μ和σ²参数,而γ和β是可训练的。 因此,反向传播算法可以利用它们来优化网络。
综上所述,已经发现此操作可以显着改善网络训练的速度以及其保留数据的性能。 而且,它没有与其他网络层不兼容的地方。 因此,大多数模型经常在所有Conv-ReLU操作之间频繁使用它,形成“ Conv-BN-ReLU”三重奏(及其变体)。 然而,尽管这是最常出现的层之一,但其优势背后的原因在文献中却有很多争议。 下面三个主要的说法:
内部方差平移:简单地说,如果输出的均值和单位方差为零,则下一层会在稳定的输入上训练。 换句话说,它可以防止输出变化太大。 这是最初的解释,但后来的工作发现了相互矛盾的证据,否定了这一假设。 简而言之,如果训练VGG网络(1)不使用BN,(2)使用BN和(3)使用BN加上人工协方差平移。尽管进行了人工协方差平移,方法(2)和(3)仍然优于(1) 。
输出平滑化:BN被认为可以平滑化优化范围,减少损失函数的变化量并限制其梯度。 较平滑的目标在训练时预测效果会更好,并且不易出现问题。
长度方向解耦合:一些作者认为BN是针对优化问题的改进公式,因此可以扩展到更传统的优化设置。 更详细地说,BN框架允许独立优化参数的长度和方向,从而改善收敛性。
总之,所有这三种解释都集中在批标准化的标准化方面。 下面,我们将看一下由γ和β参数实现的BN的平移和缩放点。
完整文章请访问 :https://imba.deephub.ai/p/af8e0630755211ea90cd05de3860c663
或关注公众号查看


 浙公网安备 33010602011771号
浙公网安备 33010602011771号