
解决过拟合:如何在PyTorch中使用标签平滑正则化
什么是标签平滑?在PyTorch中如何去使用它?
在训练深度学习模型的过程中,过拟合和概率校准(probability calibration)是两个常见的问题。一方面,正则化技术可以解决过拟合问题,其中较为常见的方法有将权重调小,迭代提前停止以及丢弃一些权重等。另一方面,Platt标度法和isotonic regression法能够对模型进行校准。但是有没有一种方法可以同时解决过拟合和模型过度自信呢?
标签平滑也许可以。它是一种去改变目标变量的正则化技术,能使模型的预测结果不再仅为一个确定值。标签平滑之所以被看作是一种正则化技术,是因为它可以防止输入到softmax函数的最大logits值变得特别大,从而使得分类模型变得更加准确。
在这篇文章中,我们定义了标签平滑化,在测试过程中我们将它应用到交叉熵损失函数中。
标签平滑?
假设这里有一个多分类问题,在这个问题中,目标变量通常是一个one-hot向量,即当处于正确分类时结果为1,否则结果是0。
标签平滑改变了目标向量的最小值,使它为ε。因此,当模型进行分类时,其结果不再仅是1或0,而是我们所要求的1-ε和ε,从而带标签平滑的交叉熵损失函数为如下公式。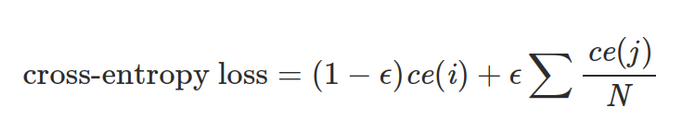
在这个公式中,ce(x)表示x的标准交叉熵损失函数,例如:-log(p(x)),ε是一个非常小的正数,i表示对应的正确分类,N为所有分类的数量。
直观上看,标记平滑限制了正确类的logit值,并使得它更接近于其他类的logit值。从而在一定程度上,它被当作为一种正则化技术和一种对抗模型过度自信的方法。
PyTorch中的使用
在PyTorch中,带标签平滑的交叉熵损失函数实现起来非常简单。首先,让我们使用一个辅助函数来计算两个值之间的线性组合。
deflinear_combination(x, y, epsilon):return epsilon*x + (1-epsilon)*y下一步,我们使用PyTorch中一个全新的损失函数:nn.Module.
查看全部文章请访问 https://imba.deephub.ai/p/456cf010747e11ea90cd05de3860c663
或关注公众号 deephub-imba


 浙公网安备 33010602011771号
浙公网安备 33010602011771号