
深度学习中的激活函数完全指南:在数据科学的诸多曲线上进行现代之旅
原文:Towards Data Science
deephub翻译组:zhangzc
自2012年以来,神经网络研逐渐成为了人工智能研究的主流,深度模型迅速取代了之前的各种benchmarks。在这些创新中,激活函数对神经网络的性能和稳定性起着至关重要的作用。这篇文章将尽可能简要地概述激活函数研究的最新进展,介绍它们的起源以及何时应该被使用。
内容提要
- 激活函数有什么作用?
- 增强函数的非线性能力
- 增强函数特定的数值性质
- ReLU 类激活函数
- 整流器: ReLU,LeakyReLU,和 PReLU
- 指数类: ELU和SELU
- 非单调类: Swish和SERLU
- 特殊的激活函数
- 线性函数:输出原始数据或进行融合操作
- Tanh:回归 +L1/L2正则项
- Sigmoid:二分类 + 二元交叉熵。
- Softmax:多分类+ 多元交叉熵
- 结语
为什么要使用激活函数?
简而言之,激活函数解决了神经网络中的两个关键问题:
- 确保函数是非线性映射
- 确保某些输出具有我们需要的数值性质,例如,输出值在 [-1, 1] 范围内,或保证输出服从某个概率分布。
非线性
要了解为什么需要非线性激活函数,请考虑以下两个函数:f(x)=ax+b和g(x) = (c+d)x + (e + f)。前者只有两个参数a,b,而第二个函数有四个参数c,d,e,f。那么:它们是两个不同的函数吗?
答案是否定的,因为"(c +d)"和"a"实际上是一回事,它们的表达能力相同。例如,如果您选择c = 10和d = 2,我可以选择 a= 12,我们得到相同的结果。"(e + f)"和"b"也是如此。为了使g(x)拥有更强的表示能力,它的四个参数不能那样组合在一起。在数学中,这意味着这些参数之间的关系必须是非线性的。例如,h(x) = sin(cx + d) + fx + e是具有四个参数的非线性模型。
在神经网络中,如果网络的每层都是线性映射,那么这些层组合起来依然是线性的。因此,多层的线性映射复合后实际上只是起到了一层的效果。为了使网络的映射不是线性的,所有层的输出都要传递到非线性函数中,如 ReLU 函数和 Tanh 函数,这样作用之后就成为了非线性函数。
数值性质
当回答"图像中是否有存在人脸"时,false 被建模为0,true被为1。给定一张图像,如果网络输出为 0.88,则表示网络回答为true,因为 0.88 更接近于 1 而不是0。但是,当网络的输出是 2 或 -7时。我们如何保证其答案在 [0, 1] 范围内?
为此,我们可以设计激活函数来保证输出满足这些数值性质。对于二分类,sigmoid函数σ(x)将[-∞,-∞]内的值映射到 [0, 1] 范围内。同样,双曲切线函数 (tanh(x))将[-∞,-∞]内的值映射到 [-1, 1]。对于使用独热编码的分类数据,softmax函数将所有值压缩到 [0, 1] 内,并确保它们都加起来为 1。
通常只有网络的最后一层(输出层)中需要用到这些数值性质,因为它是唯一需要特殊处理的图层。对于其他的网络层,可以使用更简单的非线性函数,例如 ReLU 。虽然在某些情况下,网络中间层需要特殊激活函数,例如目标检测模型和attention层,但这些并不常见,因此不在本文讨论范围之内。
ReLU类
在上一节中,我们说明了为什么需要激活函数,以及它们可以解决哪些问题。此外,我们注意到所有层都需要独立的激活函数,但这些激活函数只有很少有特殊的功能。对于大部分中间层,通常使用 ReLU类函数作为激活函数。
在讨论细节之前,我想强调的是,选择ReLU类中哪一个函数作为激活函数并没有很充分的理由。在实践中,人们需要在十几个epochs中尝试,看看哪些函数在任务上表现最好。
也就是说,根据经验法则,在建立模型的时候中尽可能先选择原始 ReLU 作为激活激活。如果模型性能不佳,遵循Tensorflow 2 文档(对于 PyTorch 用户也适用)中给出的建议,再选择 SELU 作为激活函数,并去掉所有的batch normalization。我知道这听起来有点不可思议,但这很有效,通常可以给网路带来5%到10%的提升效果。
下图总结了 ReLU 类中最常用的激活函数图(左)及其在 CIFAR-10 数据集上的表现(右图)。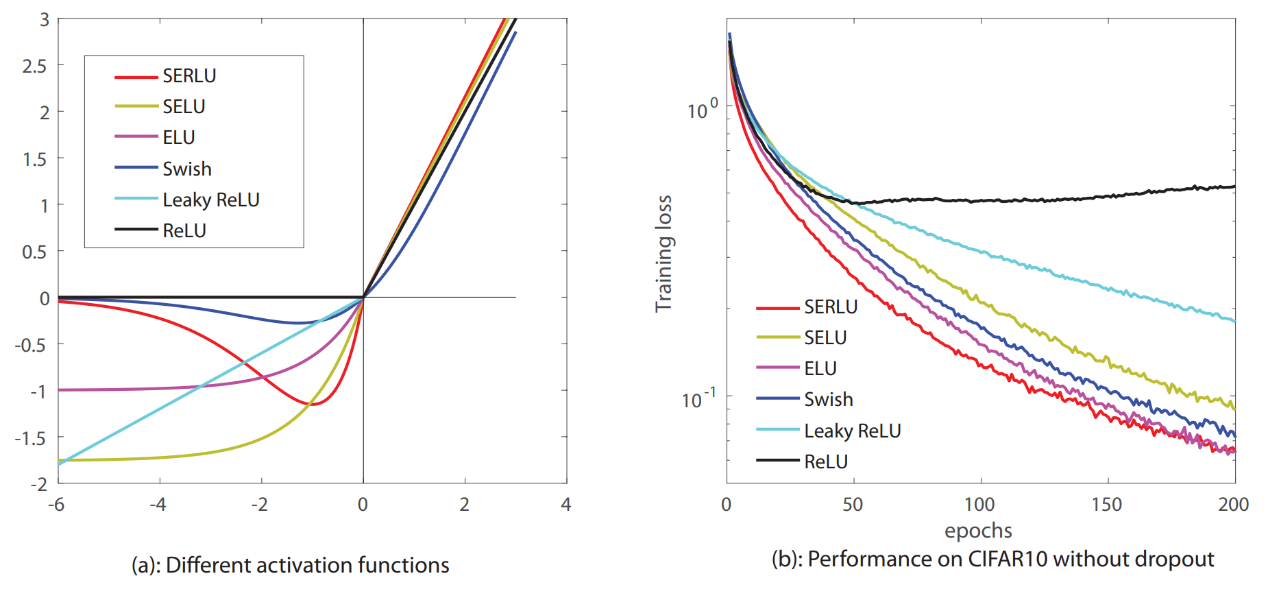
Figure 1:ReLU类中最常用的函数图(左)及其各自在CIFAR10数据集上的性能,共训练了200epochs,没有用Dropout。图像来源: Effectiveness of Scaled Exponentially-Regularized Linear Units (SERLUs)
线性整流单元 (The Rectifier Linear Unit ,ReLU)
ReLU的数学定义是:
ReLU(x) = max(0,x)
用文字来表述,如果x为正,则返回x,如果x为负,则返回 0。
这是最简单的非线性激活函数之一,因为计算最大函数值非常简单。ReLU 函数最早在AlexNet 体系结构中使用,该网络使用此激活函数训练速度几乎是传统 Tanh 函数的八倍。直到今天,大多数网络还是会选择ReLU,因为它们在计算上简单有效,这是“双赢”的选择。
此外,早期的神经网络受到梯度爆炸/消失问题的困扰。总的来说,在反向传播期间,不同层的梯度在网络反向传播中时会相乘,因此具有较大数值的梯度会越传越大(爆炸),接近零的梯度使得后面的梯度会变的更小(消失)。而使用 ReLU 激活,只有两个可能的情况:正部分的梯度是1,负部分的梯度是0。ReLU有效地解决了梯度爆炸这一问题,但是却也导致了梯度死亡或者神经元坏死现象。
Leaky单元
大多数人第一次看到ReLU时会提出这样的问题:负部分真的需要被舍弃掉吗?对此,研究人员提出了Leaky ReLU,它会弱化负部分的影响,而不是直接扔掉。Leaky ReLU在数学上的表达式如下:
LeakyReLU(x) = max(0, x) + min(0.01⋅ x, 0)
这样,一个负值信号不会被完全丢弃,在“Leaky因子”的作用下会保留一部分负值信号的特征。实践证明了在某些情况下“Leaky因子”是有效的。此外,它缓解了梯度死亡的问题,允许部分负值信号通过。在下面要介绍的激活函数中,一个反复出现的话题就是如何修正ReLU的负部分。
接下来要介绍的是参数化 ReLU,简称 PReLU。通过理性的思考我们会问:为什么Leaky单元的系数是0.01?所以我们引入一个变量 ,这样,我们不需要自己定义Leaky因子,而是让网络自己学习最合适的变量值。PReLU的表达式如下:
PReLU(x) = max(0,x) = min( x,0)
请记住 变量不是全局变量。每个整流单元都有可训练的 。这种激活函数展示了数据科学的思维方式:如果能够让模型决定什么是最佳,为什么自己要设置?
指数单位
寻找性能更好的激活函数的研究还在继续,使用指数函数作为ReLU负部分的想法出现在2015年末。指数函数对负数是饱和的,这意味着它平滑地趋向于一个常数。使用指数函数我们可以更好地模拟原始的ReLU函数,同时在一定程度上保留负部分。下面是ELU的数学公式:
ELU(x) = max(0, x) + min(eˣ — 1, 0)
在许多情况下,ELU函数比原始 ReLU 函数有更好的表现。相比之下,Leaky单元的加入并不一定使ReLU有更好的表现。
缩放指数线性单元(Scaled Exponential Linear Unit,SELU)是该领域的最新进展之一,其主要创新是self-normalizing。当训练时,它的输出均值是0,方差是1。实际上,这种self-normalizing会使batch normalization变得冗余。因此,使用 SELU 的模型会更简单,需要的操作更少。self-normalizing是用常数缩放正负部分来实现的,其数学表达式:
SELU(x) ≈ 1.0507 ⋅ max(0, x) + 1.7580 ⋅ min(eˣ — 1, 0)
有关这个激活函数的使用和系数推导的更多细节,请参阅论文和Tensorflow文档。上述常数是通过将最初的SELU简化为更紧凑的形式得到的。
非单调激活函数
到目前为止,ReLU类的所有激活函数都是单调递增的。用文字来表述,这意味着函数值只会增长。标志性的非单调函数如,抛物线(x²)先下降后增长,正弦函数(sin (x))周期性的上升和下降。第一个成功提出非单调激活函数的是Google Brain team,他们提出的非单调激活函数叫做Swish函数,它被定义为:
F(x) = x ⋅ σ(x)
σ(x)代表的是sigmoid 函数。虽然此表达式与 ReLU 函数不同,但他们的函数图像 是明显相似的,其正部分基本相同,而Swish函数在负部分有一个“凹陷”且在负无穷除趋近于零(Fig1)。这是通过"自控"机制实现的:假设x是"信号",σ(x)是一个“门函数”(一个饱和于0的函数),σ(x)乘以x是就是让信号进行自我控制。在实验中,他们发现这种激活函数在非常深的网络(30 层)中优于 ReLU 函数。
最后,SERLU 激活函数是对 SELU 的改进,在保留self-normalizing的同时,引入了“自控机制”使负值极限于零。作者没有用sigmoid函数,而是使用指数函数作为“门函数”,并重新计算常系数来实现self-normalizing。这导致函数的负部分类似于 Swish 函数,出现了比Swish 函数更明显的"凹陷"(图 1,红色曲线)。SERLU 的数学表达式为:
SERLU(x) ≈ 1.0786 ⋅ max(0, x) + 3.1326 ⋅ min(x⋅ eˣ — 1, 0)
请注意 x ⋅ eˣ 和x ⋅ σ(x)之间的相似性,两者都实现了自控机制。
虽然现在已经是2020 年,但判断这些非单调函数是否能经受时间考验,是否能替代ReLU 或 SELU作为通用的激活函数还为时过早。不过我敢打赌,self-normalizing这个操作将会一直存在。
特殊的激活函数
如前所述ReLU并非万能的,神经网络有些层需要特殊的激活函数,对于这些层,可以使用线性、sigmoid、tanh 和 softmax 等激活函数,下面给出了一些例子:
- 线性激活函数:当您需要网络的原始输出时可以用线性函数。线性函数对于融合操作很有用,例如sigmoid 交叉熵和softmax交叉熵函数,它们在数值上更稳定。此外,在理论分析中,这种激活函数对于调试和简化网络非常有用。
- Tanh: 可用于正则化回归问题,其输出在 [-1, 1] 范围内。通常与 L2 损失结合使用。
- Sigmoid: 用于二分类问题中。将输出压缩到 [0, 1] 范围内。大部分时候都与二元交叉熵损失一起使用。
- Softmax:在多分类中经常使用,使网络输出的是有效的概率分布。这意味着所有值都在 [0, 1] 范围内,且总和为 1。可与多元交叉熵损失一起使用。
正如您所看到的,给出一个问题,选择使用哪个激活函数是非常简单的事情。此外,选定激活函数也表明了应使用或考虑哪些损失函数。如前所述,经验法则告诉我们在大部分情况下都要使用 ReLU 激活函数,然后为输出层选择最合适的特殊激活函数,并在以后的训练中扩大选择范围并尝试替代这些函数。
最后值得一提的是,对于一些分类问题,类别之间不是相互排斥的。在此特殊情况下,单个输入可能被对应多个类。在这些情况下是应按类使用Sigmoid,而不是用softmax。这样,所有输出都被压缩到 [0, 1] 范围,但它们的和不是1。
结语
本文回顾了激活函数中的state-of-the-art,并介绍了如何选择和使用它们。总之,激活函数使网络变成非线性的映射,使得输出层具有某些数值性质。对于中间层,使用 ReLU 类的激活函数。并且根据经验,尽可能地使用 ReLU,然后再考虑用 SELU 激活函数并删除所有batch normalization操作。对于输出层,请考虑对非正则化/正则化回归使用线性/tanh激活函数,对二分类/多分类使用 sigmoid/softmax。
很少有一本指南能面面俱到,有些东西总是会被遗漏。在这里,我故意遗漏了那些不太为人所知或使用的函数,如softplus, softsign,和relu6函数。我选择这样做,是为了使保持文章尽可能简短的同时,让大家了解常用的激活函数。如果您未能理解这篇文章中的任何函数,不同意我的论述,或希望看到一些扩展的概念,请在评论部分留言让我知道,我会尽可能保持本文档的更新:)
原文地址:https://imba.deephub.ai/p/3d3daf8068ba11ea90cd05de3860c663


 浙公网安备 33010602011771号
浙公网安备 33010602011771号