

Mysql查询数据时,自动为结果编上序号
ROW_NUMBER () over (PARTITION BY id) AS row_num,
自己之前没遇到过这种在查询时给结果编号的情况,是同事打算跳槽,面试回来问到这种情况才想到去研究,以下以单表查询为例分析下:
SQL:
SELECT (@i:=@i+1) i,user_id,user_name FROM dt_user_all_orders, (SELECT @i:=0) as i WHERE user_name=’qqqqqqqqqq’ LIMIT 0,10;
结果:
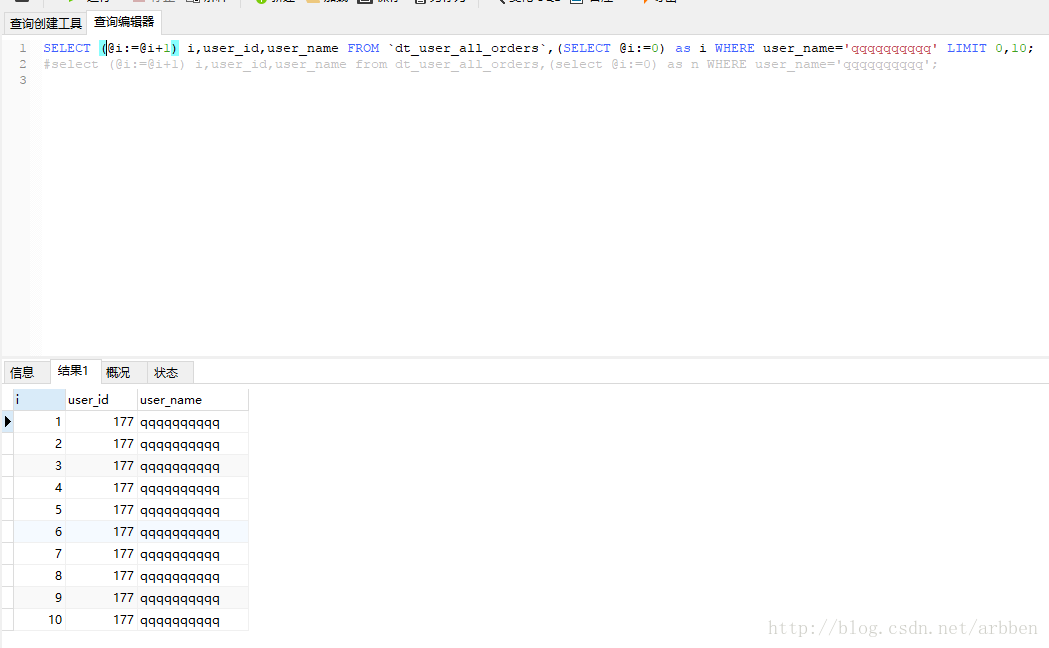
分析:
在开始是定义一个变量i,让它每增一条结果是➕1,@i:=1;
这里顺带复习下mysql定义用户变量的方式:select @变量名
对用户变量赋值有两种方式,一种是直接用”=”号,另一种是用”:=”号。其区别在于使用set命令对用户变量进行赋值时,两种方式都可以使用;当使用select语句对用户变量进行赋值时,只能使用”:=”方式,因为在select语句中,”=”号被看作是比较操作符
(@i:=@i+1) 也可以写成 @i:=@i+1,加括号是为了视觉上看这结构更清楚些。在定义好一个变量后每次查询都会给这个变量自增,而我们每次执行查询语句获取结果后就不需要这个变量自增了,所以要把它重置为0,在表名后用逗号分格下使用 (SELECT @i:=0) as i 就可以了,说下这个as i为什么要这样用,是因为派生表必须需要一个别名,这个就是做它的别名,可以任意字符。
更多请到:https://onepersonsite.com
————————————————
版权声明:本文为CSDN博主「汪得福」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/arbben/article/details/78665389



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix