2017 软工作业结队第二次作业
结队成员
- 031502212 符天愉
- 031502240 杨艺
github
编程语言
C语言
生成输入数据
生成数据原理:
在生成学生和部门的数据中,对于部门时间、学生实践、部门标签、学生标签等的可能有多个的 数据,分别采用两个随机数t1,t2,随机数t1表示这个数据的数目,随机数t2表示数据的内容,通过这两个随机数来确定一组数据。在考虑生成的数据中,我们将学生的时间所能选的时间比部门活动时间多,所选的时间都是比较正常的,尽量能让学生能够符合部门的时间,学生的标签和部门的标签的内容保持一致。一个学生的数据,通过上述的方法生成,并同时存入json格式。300个学生的数据通过循环生成。而部门的数据也是通过同样的方法来生成,存入json格式,并循环20次。
在测试生成的数据时,比如部门标签中,发现会有重复的标签生成,这也是之前没有考虑到随机数会发生重复。所以后来,便在生成随机数时加一个判断来保证在生成一个学生或部门数据中不会生成重复的随机数。
生成的数据:input_data.txt
数据建模及匹配程序
数据建模:
在匹配程序之前,我先通过创建两个结构体数组student和department分别存入学生的相关信息和部门的相关信息,并且在student的结构体中加入一个标志来判断这个学生是否被部门选中,而在department这个结构体中,加入两个个数组,一个是来存志愿选这个部门的学生的编号,另外一个是来存已经加入这个部门的学生编号。为了方便在全局定义个applications_number[21]来记录选各个部门的学生的人数。
匹配程序的思路:
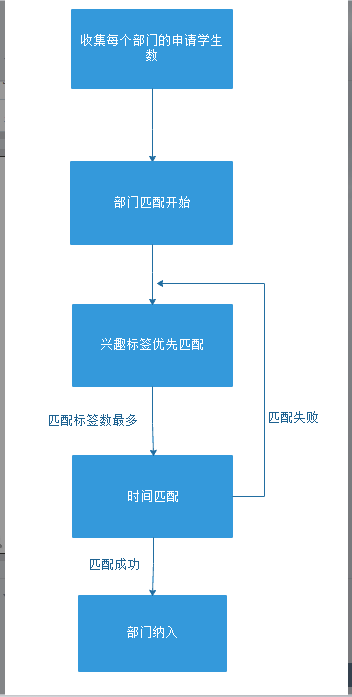
首先,在学生和部门匹配前,我们是站在部门的视角上。通过得到的数据,先去存储志愿加入各个部门的学生编号以及学生人数。
然后,我们是以兴趣为优先级高的,当你兴趣匹配部门的标签越多你就容易先被部门考虑,所以,匹配学生的兴趣和部门标签相同的个数,匹配相同个数越多的学生,这个学生就会被优先匹配时间。
最后,通过匹配时间来最终决定其是否能够被这个部门选择,当学生时间有满足部门活动时间时,则这个学生被部门选中,并被部门计入,学生也将记录其有加入的部门。
通过以上的流程来实现学生和部门的匹配。
相关流程图
代码规范
//时间段匹配
if(strcmp(s_day,d_day)==0)
{
//当满足时间段,纳入学生
if(time2[1]*60+time2[2]<= time2[5]*60+time2[6] && time2[3]*60+time2[4] <= time2[7]*60+time2[8] )
{
//判断学生是否已经被这个部门纳入
if(test == stu[d_student[i][max_number]].student_no)
{
n2++;
break;
}
test = stu[d_student[i][max_number]].student_no;
//在部门里加入这个学生的编号
dep[i].member[d_member] = stu[d_student[i][max_number]].student_no;
stu[d_student[i][max_number]].department=1; //当这个学生被部门纳入则标记
//部门收的人数加1
d_member++;
}
}
代码规范上,因为之前没有养成这样的良好的习惯,所以在变量的命名上还是比较难想,在一些细节上也没做的很好,还需要更多的练习,养成良好的代码习惯。
结果评估
在匹配数据的结果上,我们发现在结果中有些不足,我们分析可能有以下几个原因。
- 在兴趣标签匹配数相同的情况可能没有考虑的很全,有种情况当部门差一个人就收满了,但最后两个人的兴趣标签匹配数相同没有在深入下去的判断。
- 在我们的匹配程序中,志愿优先级并没有很重,没有过于强调志愿的优先级。
以上的原因会导致匹配的效果并不是特别好,
结队编程心得
结队的心得:
这是第一次的结队编程,确实是与一个人编程不同。在编程前,互相沟通交流各自的意见,确定思路逻辑,这也会比一个人想清晰完善很多。编程的过程中,对友也会实时检错,这也减少了很多不必要的Bug。因为我们并不是分开编程,所以对于项目的代码上都比较熟悉,不会出现看不懂的情况。与此同时,在解决问题的方法上也可能会比一个人编程会更好,在和我队友编程的时候也实践了C的指针。如果是我一个人编程,我可能就不会用到指针了。
在逻辑处理上也不容易乱,在用到很多变量,逻辑又绕,一个人可能会容易急躁,好在我的队友很有耐心,在和队友两个人理逻辑会比一个人又快又好。在编程过程中,也能从队友编程上学到很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号