论文阅读:Blink-Fast Connectivity Recovery Entirely in the Data Plane
1、背景
在网络中,链路故障的发生在所难免,为了降低故障带来的影响,就需要重新路由,将数据传输到合适的链路上。当因为链路故障发生处的不同,也有不同的解决方法。
AS(Autonomous System)内发生的故障如下图:
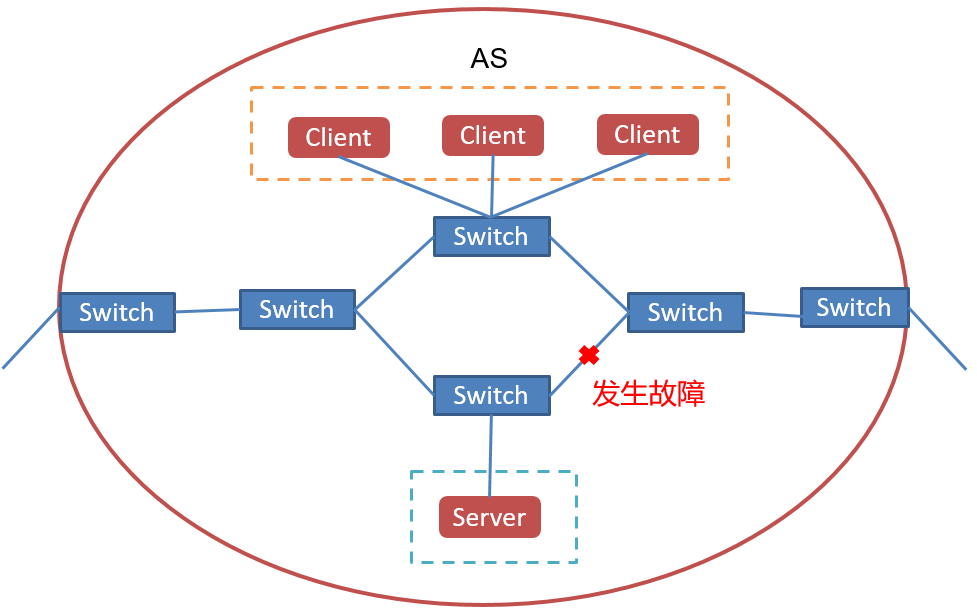
这种情况有现有的如下几种重路由方案:
- IPFFR(IP Fast Reroute Framework,RFC 5714)
- LoopFree Alternates (RFC 5286)
- MPLS fast reroute (RFC 4090) 等等
上述的几种重路由可以达到亚秒级的重路由
如上几种重路由的方法有两个共同点:
- 快速检测:硬件信号通告;
- 快速恢复:使用预先计算的备份链路,而不是重新来计算链路;
2、要解决的问题
当故障发生在AS外时,如下图所示:
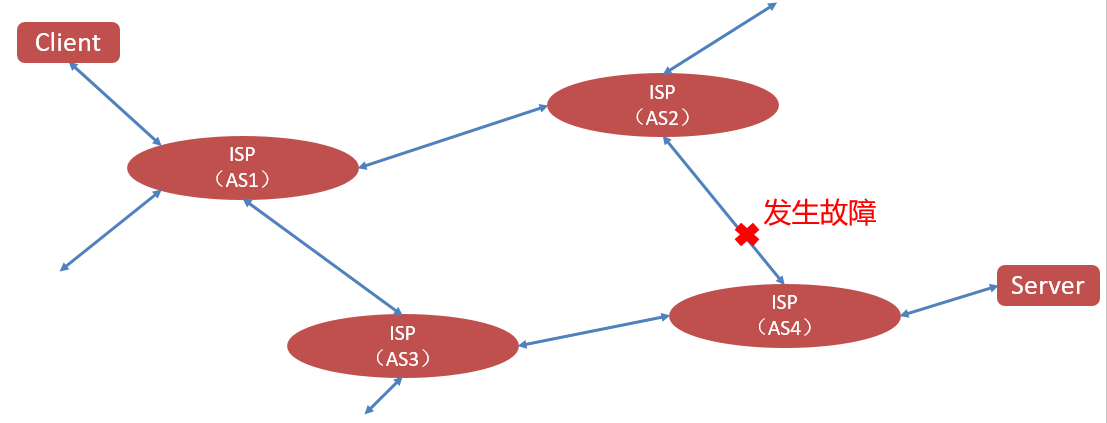
现有也有几种解决方案:
SWIFT是优化了BGP的解决方案,SWIFT为了缩短收敛时间,利用一些已更新的BGP更新(例如,它们共享相同的AS-PATH)这一事实,从收到的一些BGP更新中预测了整个远程失败的程度。但是,SWIFT的基本问题是,在相应的数据平面故障后,而第一次BGP更新可能需要O(分钟)才能传播。
综上,现有得方案在解决远程故障是很缓慢的,所需要的时间是分钟级,主要原因是要靠控制面来驱动重路由。
3、Blink
Blink:一个数据驱动的快速重路由框架,并基于可编程数据平面构建,目的为了实现远程故障亚秒级的收敛。
Blink利用TCP事件信号直接在数据平面上检测故障的发生。

TCP流在中断时表现的可预测的行为:在时间上按指数间隔反复传输相同的报文,而当多个流混合时,TCP流中断的重传行为变会变成明显的故障特征信号。
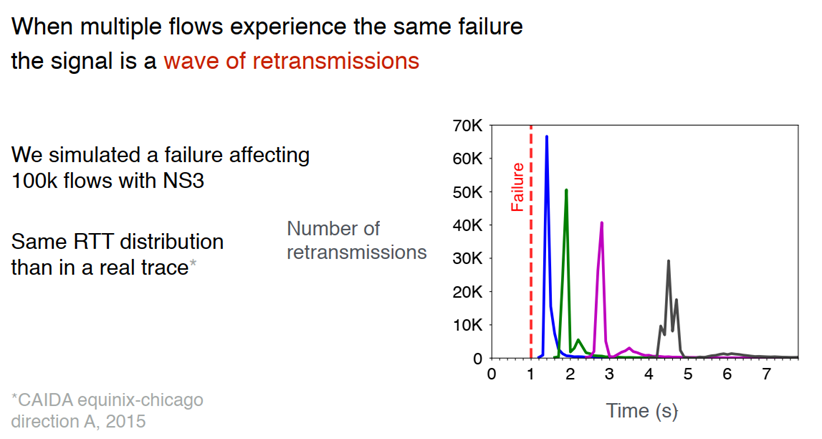
4、关键挑战
- 1.数据平面的资源有限。无法跟踪所有的TCP应用流,如果采用随机采样,那常常会导致跟踪到无用流,例如传输很少的流;
- 2.如果只发生暂时的拥塞,对任何重传的报文进行重新路由,那么可能会导致适得其反的流量变化,需要区分短暂的拥塞和链路故障。
- 3.数据平面的故障信号并不提供发生故障的根本原因,如果在重新路由是不协调的路由决策,那么很容易导致一些问题的发生,例如:路由黑洞,环路,振荡。
5、解决思路
- 1.使用流抉择器来解决跟踪流问题,该抉择器会自动驱逐不活动的流并将其替换成活动的流。因为活跃的流几乎会立即重传,而不活动的流可能根本不会重传。
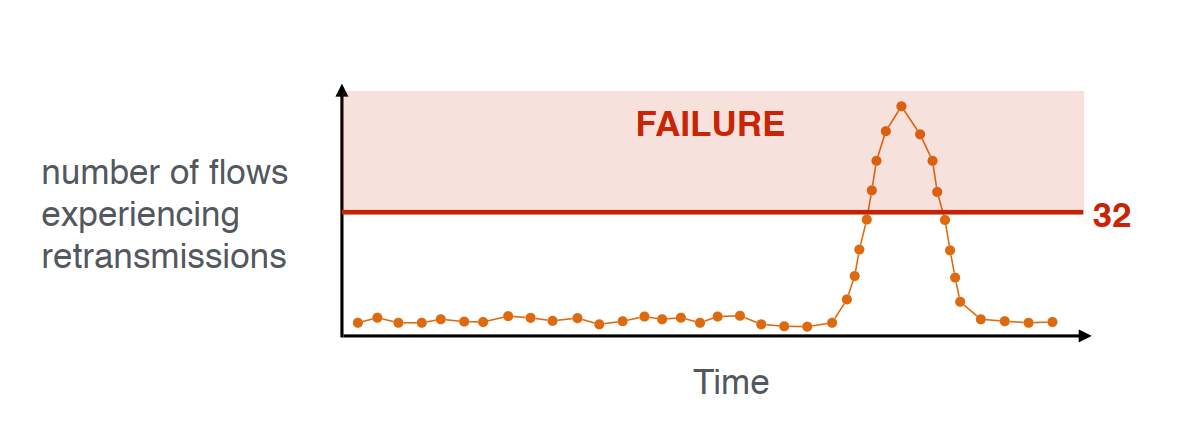
- 2.即使没有网络故障,短暂的拥塞也会导致TCP重传。Blink系统主要对破坏性事件作出反应,不受噪声和常规协议的影响。如下图所示
![]()
- 3.随着TCP重传数量随着时间逐步减小,Blink系统在第一个TCP重传过程中,捕获到故障信号。
- 数据平面重路由对于转发的正确性,只能通过尝试和观察来判断重路由的正确性,以数据驱动的方式来备份下一跳,验证流量是否恢复。
附录
论文地址:https://www.usenix.org/conference/nsdi19/presentation/holterbach
github源码地址:https://github.com/nsg-ethz/Blink

 浙公网安备 33010602011771号
浙公网安备 33010602011771号