Java基础IO流(一)
IO概念:
大多数应用程序都需要实现与设备之间的数据传输,例如键盘可以输入数据,显示器可以显示程序的运行结果等。在Java中,将这种通过不同输入输出设备(键盘,内存,显示器,网络等)之间的数据传输抽象表述为"流",程序允许通过流的方式与输入输出设备进行数据传输。Java中的"流"都位于java.io包中,成为IO(输入输出)流。
IO分类:
IO流有很多种,按照操作数据的不同,可以分为字节流和字符流,按照数据传输方向的不同又可以分为输入流和输出流,程序从输入流中读取数据,向输出流中写入数据。在IO包中,字节流的输入输出流分别用java.io.InputStream 和 java.io.OutputStream表示,字符流的输入流分别用java.io.Reader 和 java.io.Writer表示,如图:
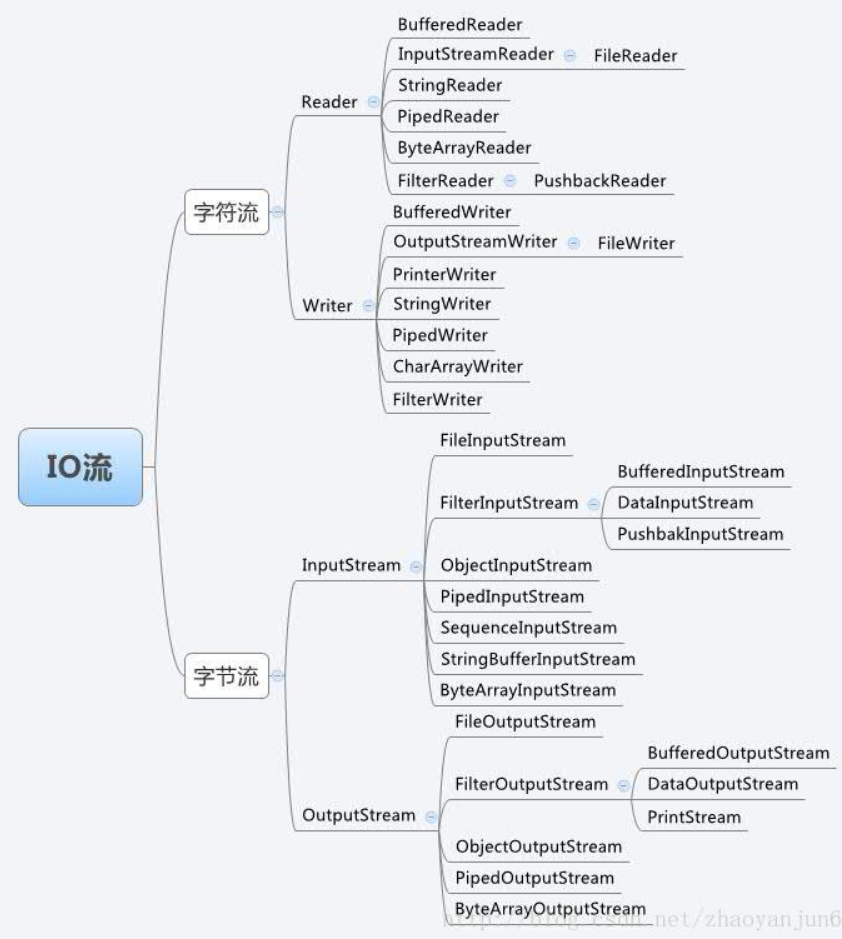
提示:
- 输入流:InputStream或者Reader:从文件中读到程序中;
- 输出流:OutputStream或者Writer:从程序中输出到文件中;
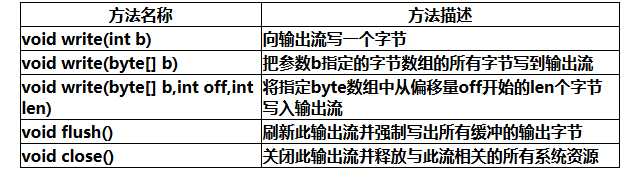
下面是一些InputStream的常用方法:

下面是一些OutputStream的常用方法:
入门案例中比较重要的语句:
1.FileInputStream in = new FileInputStream("test.txt");
解析1:创建一个文件字节输入流,接下来可以用in.read()来读取test.txt中的字节,输出的是整型(字节),想获得具体字符需要在输出前加上强制转换(char)后才能输出字符类型。
2.FileOutputStream out = new FileOutputStream("example.txt");
解析2:创建一个文件字节输出流(程序运行后,会在当前目录下生成一个新的文本文件example.txt),接下来可以定义字符串然后把字符串转换成字节类型就可以利用上面展示的write方法把字节写入到example.txt文件中了。
部分代码展示:
String str = "测试字符";
byte[] b = str.getBytes();
这样就做到了把要输入的字符再调用方法前转换成字节类型。
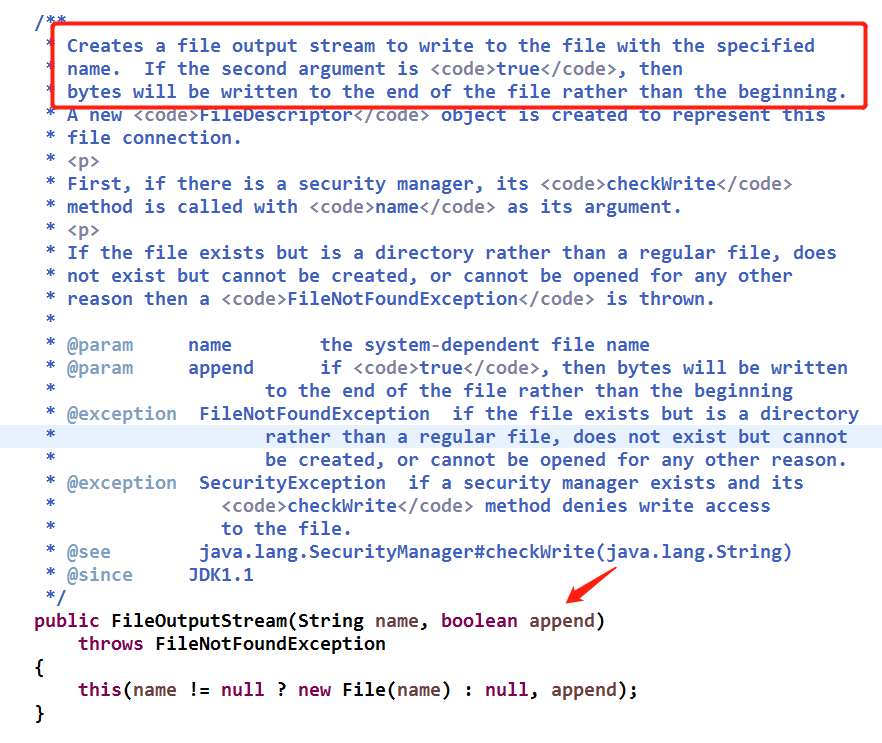
发现问题:我在按照书上的demo敲代码运行后发现,没办法续写,就是每次都是重新开始写。
解决:后来发现查询后发现,FileOutputStream的构造函数中还有另一个参数是指定是否续写的。源码如下(嘿嘿....经过一段时间的学习已经习惯有看源码的好奇心了,虽然百分之95以上看不怎么懂,但是这次的貌似能看懂一些..哈哈)
Demo(拷贝文件)

1 import java.io.FileInputStream; 2 import java.io.FileNotFoundException; 3 import java.io.FileOutputStream; 4 import java.io.IOException; 5 import java.io.InputStream; 6 import java.io.OutputStream; 7 8 public class CopyFile { 9 public static void main(String[] args) { 10 try { 11 //创建一个字节输入流,用于读取当前目录下的mp3文件 12 InputStream is = new FileInputStream("DJ Daniel Kim - Pop Danthology 2012.mp3"); 13 //创建一个文件字节输出流,用于将读取的数据写入copy.mp3中 14 OutputStream os = new FileOutputStream("copy.mp3"); 15 //定义一个int类型的变量ch,记住每个读取的一个字节 16 int ch; 17 //获取拷贝文件前的系统时间 18 long beginTime = System.currentTimeMillis(); 19 20 //把每个读取的字节赋值给ch变量,并判断是否读到文件末尾(返回-1) 21 while((ch = is.read()) != -1){ 22 os.write(ch); //将读到的字节写入文件 23 } 24 25 //获取拷贝文件结束时的系统时间 26 long endTime = System.currentTimeMillis(); 27 28 System.out.println("文件拷贝用了" + (endTime - beginTime) + "毫秒"); 29 30 //不要忘记关闭流了(老实说,我在写的时候还是忘记了,对着书再看的时候才发现自己漏了...) 31 is.close(); 32 os.close(); 33 34 } catch (FileNotFoundException e) { 35 // TODO Auto-generated catch block 36 e.printStackTrace(); 37 } catch (IOException e) { 38 // TODO Auto-generated catch block 39 e.printStackTrace(); 40 } 41 } 42 }

很明显,文件拷贝是相当成功了的!但是吧,换算了一下,这个拷贝时间有点长啊,10M的音乐...不过没关系,我在看书的时候发现背面就是解决这个问题的知识点-----------字节流的缓冲区
抄一下概念把...
上述的代码虽然实现了文件的拷贝,但是一个字节一个字节的读写,需要频繁的操作文件,效率非常低,这就好比从北京运送烤鸭到上海,如果有一万只烤鸭,每次运送一只,就必须运输一万次,这样的效率显然非常低。为了减少运输次数,可以先把一批烤鸭装在车厢中,这样就可以成批的运送烤鸭,这时的车厢就相当于一个临时缓冲区。当通过流的方式拷贝文件的时候,为了提高效率也可以定义一个字节数组作为缓冲区。在拷贝文件时候,可以一次性读取多个字节的数据,并保存在字节数组中,然后将字节数组中的数据一次性写文件...
1 import java.io.FileInputStream; 2 import java.io.FileNotFoundException; 3 import java.io.FileOutputStream; 4 import java.io.IOException; 5 import java.io.InputStream; 6 import java.io.OutputStream; 7 8 public class CopyFileByCache { 9 10 public static void main(String[] args) { 11 12 try { 13 InputStream in = new FileInputStream("DJ Daniel Kim - Pop Danthology 2012.mp3"); 14 OutputStream out = new FileOutputStream("copyByCahe.mp3"); 15 16 //定义存储(缓存)一定大小字节的字节数组 17 byte[] buff = new byte[1024]; 18 //定义一个整型len 用来记录read方法返回的读入的字节数或者读到文件末尾的时候返回的-1 19 int len; 20 21 long beginTime = System.currentTimeMillis(); 22 23 int i = 0; 24 25 while((len = in.read(buff)) != -1){ 26 27 //输出读入的字节数 28 i++; 29 System.out.print(len + "\t"); 30 if (i % 8 == 0){ 31 System.out.println(); 32 } 33 34 //从b数组中的第一个开始,取len个字节写入到文件中 35 out.write(buff, 0, len); 36 } 37 38 long endTime = System.currentTimeMillis(); 39 40 System.out.println(); 41 System.out.println("文件拷贝用了" + (endTime - beginTime) + "毫秒"); 42 43 44 //我又忘记写关闭流了,写完后对照书发现我又忘记了.... 45 in.close(); 46 out.close(); 47 48 } catch (FileNotFoundException e) { 49 // TODO Auto-generated catch block 50 e.printStackTrace(); 51 } catch (IOException e) { 52 // TODO Auto-generated catch block 53 e.printStackTrace(); 54 } 55 } 56 }

从运行效果可以看出,每次读入出了1024个字节,相对于之前我说速度是之前的1024倍应该没什么问题吧....运行确实快了很多
这里主要运用了InputStream中的read的方法,int read(byte[] b) 【刚开始我一直搞不清楚怎么回事,仔细看返回值才知道,返回的是读入的字节数而不是读入的字节的一个数组,读入的字节的字节数组已经存到了b中】
上述定义中,我定义了1024大小的字节数组,每次最多可以读入1024字节,然后再利用OutputStream中的void wirte(byte[] b,int off,int len)把b数组中的从第off个开始的len个字节写入文件中。
参考书籍:《Java基础入门》传智播客高教产品研发部 编著

 浙公网安备 33010602011771号
浙公网安备 33010602011771号