Elasticsearch必备原理理解
Elasticsearch读写原理
心得:
- 主分片、副本分片的存在类似各大组件的”主从结构“,需要注意的是,Elasticsearch的写入是针对主分片,而读操作是主分片、副本分片都可以(采用随机轮询策略)。所以——适当增加”副本分片数“将会减缓对主分片的查询压力,需要注意的是将会消耗同样的内存、CPU等资源,需要考量。
- Elasticsearch的”协调节点“非常巧妙,直接接受到客户端检索请求的节点会将请求并发交给其他主分片所在的节点去让它们自己处理(而主分片和副本分片又会有负载策略),当它们都处理完后由”协调节点“做数据的后续整理操作,而这一切对于客户端来说都是透明的。所以——适当增加”主分片“、”副本分片“的数量将会有利于检索请求(当然写请求也有利),如果只有一个主分片,那么请求永远是由它自己来处理,如果有两个主分片,那么请求就会有两个主分片一起合作(异步、并发),当然会快很多,需要注意的是一般来说建议检索场景的主分片在20G以内,日志场景在50G以内,所以需要综合考量。
- Elasticsearch的【路由】策略,正是因为它所以能够很方便地找到文档所在的主分片,从而找到对应的节点。同时也证明了,索引的主分片一旦确定,将不能再更改。(如果后来增减了主分片的数量,那么再通过公式去路由某文档所在的主分片就会与之前有所不同了。所以——在创建索引的时候就要预估好数据量,来确定好合适的主分片数。当然也可以通过官方提供的RolloverAPI来滚动创建索引或者自己通过业务控制按某时间维度来维护索引,相关的配置可以放在分布式配置中心(如Apollo)中,这样就能更好地把控索引的相关配置了。
系统特性
Elastic本身也是一个分布式存储系统,如同其他分布式系统一样,我们经常关注的一些特性如下。
- 数据可靠性:通过分片副本和事务日志机制保障数据安全;
- 服务可用性:在可用性和一致性的取舍方面,默认情况下Elastic更倾向于可用性,只要主分片可用即可执行写入操作;
- 一致性:弱一致性。只要主分片写成功,数据就可能被读取。因此读取操作在主分片和副本分片上可能会得到不同结果;
- 原子性:索引的读写、别名更新是原子操作,不会出现中间状态。但Bulk不是原子操作。不能用来实现事务;
- 扩展性:主副分片都可以承担读请求,分担系统负载。
Elasticsearch写入数据过程
- 客户端请求到Elasticsearch的节点上,该节点就有了新身份>>>coordinating node(协调节点)
- 由”协调节点“对document进行路由,将请求转发给对应的有主分片的节点
- 主分片处理写入请求,然后将数据同步到该主分片对应的所有副本分片上
- ”协调节点“收到主分片、副本分片都处理完的通知后,就返回响应结果给客户端。
【路由】Elasticsearch会根据传入的"_routing"参数(或Mapping中设置的_routing,如果参数和设置中都没有则使用_id),按照公式 shard_num = hash(\routing) % num_primary_shards,计算出要分配到的主分片,从集群元数据中找出对应的主分片的位置,将请求路由到该分片进行文档操作。
Elasticsearch写入底层原理
理解近实时——“refresh_interval"参数默认为”1s“,意味着1秒后才能够检索到最新的更新。
- 最先的写入是会写入到”内存Buffer“中(同时将数据双写到translog日志文件中)
- 默认每隔一秒就会将”内存Buffer“中的数据刷新到新的段(segment)中,这个时候就能够被检索到了。
总结:
- 如果对实时性要求高的,可以将该参数设置为很低的值如“10ms”等
- 琐碎的段越来越多,对性能也不会有好处,这时候我们需要综合考量该参数的值,减少“新段”的产生;同时也可以通过定时任务,如每天凌晨对索引执行“强制段合并”,将小段合并为大段。
Elasticsearch数据持久化——refresh、translog
数据写入磁盘后,还要调用fsync才能把数据刷到磁盘中,如果不这样做在系统断电的时候就会导致数据丢失。
elastic底层采用的是lucene这个库来实现倒排索引的功能,在lucene的概念里每一条记录成为document(文档),lucene使用segment(分段)来存储数据,用commit point来记录所有segment的元数据,一条记录要被搜索到,必须写入到segment中,这一点非常重要。
elastic使用translog来记录所有的操作,我们称之为“write-ahead-log”,新增一条记录的时候,es会把数据双写到translog和内存buffer中,如下图所示:
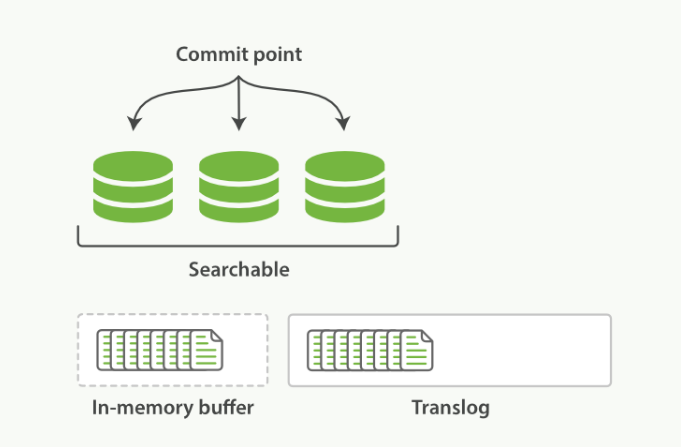
refresh操作
默认间隔一秒refresh,参数“index.refresh_interval"。对应操作:
- 所有在内存缓冲区中的文档被写入到一个新的segment中,但是没有调用fsync,因此内存中的数据可能丢失
- segment被打开使得里面的文档能够被搜索到
- 清空内存缓冲区
flush操作
随着translog文件越来越大时,要考虑把内存中的数据刷新到磁盘中,这个过程称为flush。对应操作:
- 把所有内存缓冲区的文档写入到一个新的segment中
- 清空内存缓冲区
- 往磁盘里写入commit point信息
- 文件系统的page cache(segments)fsync到磁盘
- 删除旧的translog文件,因此此时内存中的segments已经写入到磁盘中,就不需要translog来保障数据安全了。
注意:默认30分钟或512MB的时候会执行flush操作。对应相关参数前缀,”index.translog"
Elasticsearch读数据过程
与”写入“过程类似
- 客户端请求到Elasticsearch节点上,该节点将作为协调节点做如下操作
- 将读请求进行【路由】,将请求转发到【路由】到的主分片所在的节点上
- 该节点会使用【随机轮询算法】,在该主分片和该主分片对应的所有副本分片中随机选择一个去处理读请求
- 最终接受到请求的节点处理完后会将结果返回给协调节点,由协调节点将结果响应给客户端
Elasticsearch搜索过程
一般分为两个步骤,我们称之为——Query Then Fetch,即被要求执行检索的分片本地执行查询,将结果添加到from+size的本地有序优先队列中,随后每个分片返回各自优先队列中所有文档的ID和排序值给协调节点,协调节点合并这些值到自己的优先队列中,产生一个全局排序后的列表,协调节点确定哪些文档”确实“需要被取回,例如如果指定了from,size则会从偏移量为from开始取size个结果,确定好要Fetch的数据后就会向相关的Node发送GET请求取回完整数据。(Fetch阶段的目的就是通过文档ID获取完整的文档内容)
- 客户端将检索请求发送到Elasticsearch节点上.....
- 协调节点将搜索请求转发到所有的分片上(主分片或者主分片对应的任意副本分片)
- 每个分片将自己的检索结果(即doc_id)返回给协调节点,协调节点来进行数据合并、排序、分页等操作
- 最后协调节点会根据整理好的doc_id再去各个节点上反查实际的文档数据,最终响应给客户端。
基础概念
段
索引文档以段的形式存储在磁盘上,而段就是索引文件拆分出的多个子文件,每一个段本身就是一个倒排索引,并且段具有不可变性,一旦索引的数据被写入硬盘,就不可再修改。在底层采用了分段的存储模式,使它在读写时候完全避免了锁的出现,大大提升了读写性能。
新增、更新、删除时段的状态
- 新增:新增一个段
- 删除:对于删除操作,通过一个.del文件标记被删除的文档,在后续检索中移除结果集中被标记”删除“的文档
- 更新:更新是两个步骤——删除、新增
段被设置为不可修改的优势
- 不需要锁
- 一旦索引被读入内核的文件系统缓存,由于其不可变性,只要文件系统缓存中有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘
- 写入单个大的倒排索引允许数据被压缩,减少磁盘I/O和需要被缓存到内存的索引的使用量。
段被设置为不可修改的缺点
- 当对旧数据进行删除时,旧数据不会马上删除,而是在.del文件中被标记为删除,空间浪费(段合并操作可以真正移除被删除的文档)
- 若有一条数据频繁地更新,每次更新都是新增新的标记旧的,则会有大量的空间浪费
- 每次新增数据时都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源消耗很大(文件句柄、内存、CPU运行周期)
- 在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,增加了查询的负担
段合并
简而言之就是将小段合并为大段的过程(同时真正删除被标记删除的文档), 如果之前一个查询需要遍历150个小段,现在只需要查询一个大段即可。
段合并的操作是Elastic后台自动处理的,当然业务中也可以通过API,定时强制段合并。(如每天凌晨某个点,强制段合并)
【备注:】如果想减少段的生成,可以适度提升”refresh_internal"的值,因为这个值是内存buffer刷新到文件系统,成为真正的segment_file的间隔,值越小意味着越短时间就会有一次对内存buffer中的数据整合成一个段落到文件系统Cache中的操作。
参考资料:
《Elasticsearch translog文件介绍》
《Elasticsearch 技术分析(九):全文搜索引擎Elasticsearch,这篇文章给讲透了!》
《Elasticsearch源码解析与优化实战》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号