
摘要:
hive metastore server hive --service hiveserver2 阅读全文
posted @ 2021-07-19 22:18
deepJL
阅读(31)
评论(0)
推荐(0)
摘要:
1、查询topic,进入kafka目录: bin/kafka-topics.sh --list --zookeeper localhost:2181 2、查询topic内容: bin/kafka-console-consumer.sh --bootstrap-server localhost:909 阅读全文
posted @ 2021-07-19 16:56
deepJL
阅读(10900)
评论(0)
推荐(2)
摘要:
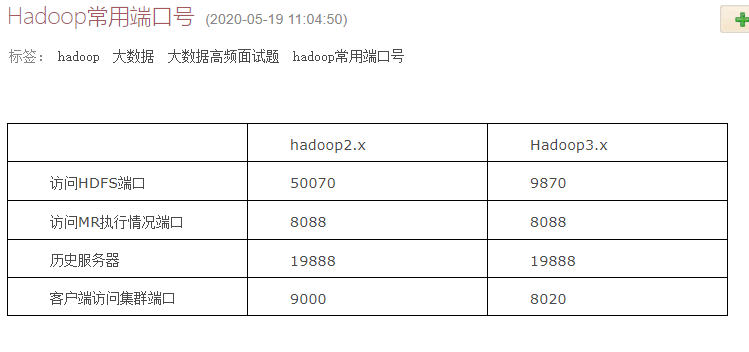 阅读全文
posted @ 2021-07-19 01:15
deepJL
阅读(35)
评论(0)
推荐(0)
摘要:
在确保kafka、zookeeper 版本正确,并且启动正常的情况下, 可以自己看看配置的zookeeper路径下有没有kafka的元数据。 我遇到的原因是 kafka的server.properties 配置文件写的 127.0.0.1:2181/kafka 然后使用命令的时候写了 –zookee 阅读全文
posted @ 2021-07-19 01:05
deepJL
阅读(979)
评论(0)
推荐(1)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号