Spark新手入门——1.Scala环境准备
欢迎大家关注我的公众号,“互联网西门二少”,我将继续输出我的技术干货~

主要包括以下三部分,本文为第一部分:
一. Scala环境准备
二. Hadoop集群(伪分布模式)安装 查看
三. Spark集群(standalone模式)安装 查看
因Spark任务大多由Scala编写,因此,首先需要准备Scala环境。
注:楼主实验环境为mac os
Scala环境准备
-
下载JDK1.8并安装、配置环境变量(JAVA_HOME),建议使用1.8,与时俱进;
-
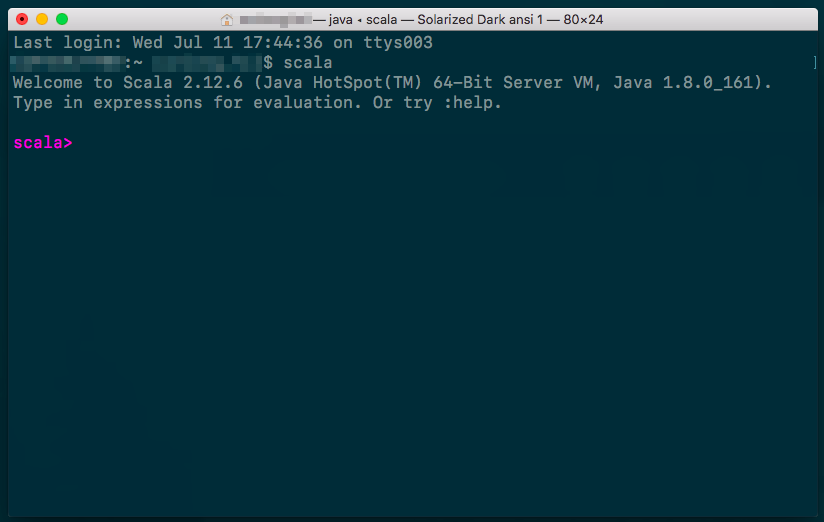
下载scala-sdk并解压到某个路径(如:
~/tools/scala-2.12.6),为方便使用还可以设置一下SCALA_HOME,在终端输入~/tools/scala-2.12.6/bin/scala(未设置SCALA_HOME)或scala(前提设置了SCALA_HOME)可以验证scala的版本或进行交互实验(scala官网推荐的图书《Programming in Scala, 3rd ed》中的实例均为在此模式下运行,故学习scala阶段到这一步就够了)
![图1.1 scala sdk验证]()
-
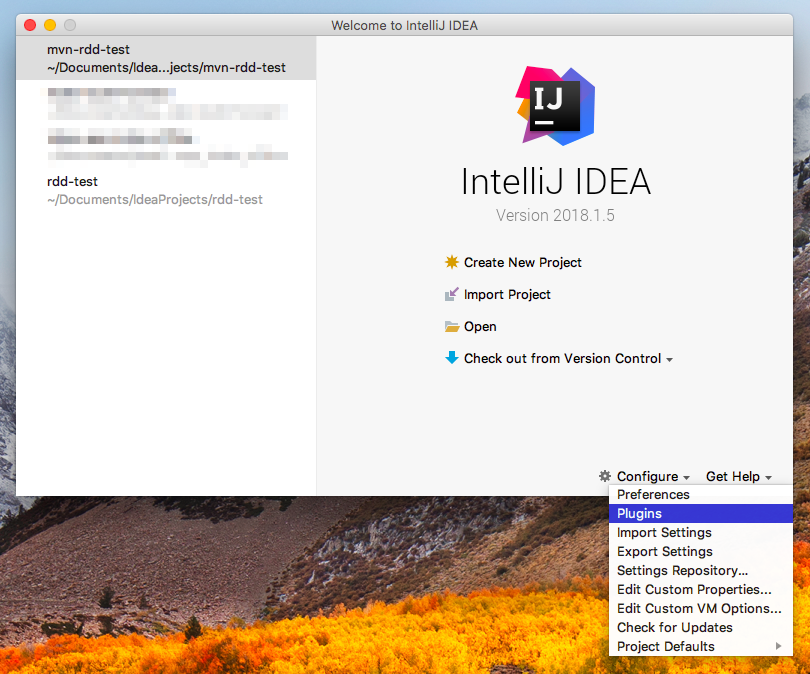
下载IntelliJ IDEA(Ultimate"版即为免费版本)并安装,安装后安装Scala插件(plugin),如下图所示;
打开plugin菜单:
![图1.2 打开plugin菜单]()
搜索并安装scala插件

- 写个小程序测试一下吧
选择“Create New Project”
![图1.4 create new project]()

选择项目类型为“Scala”
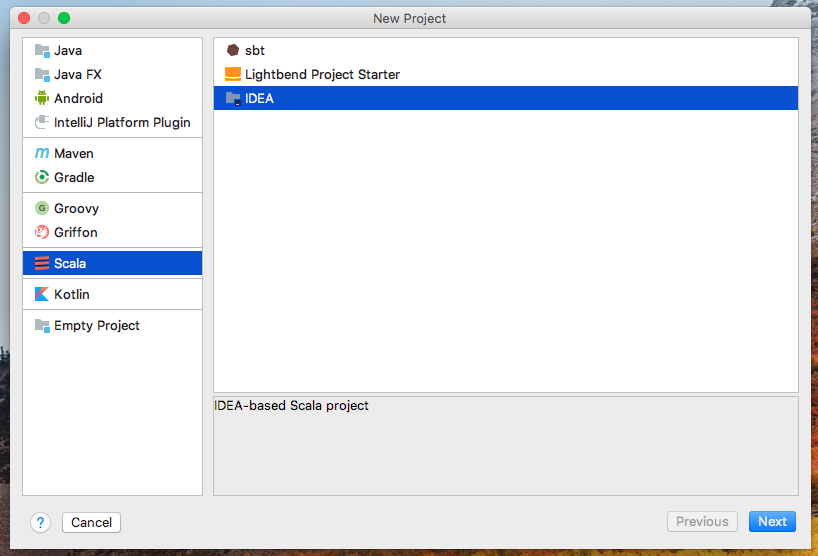
默认没有Scala SDK,通过以下方式添加:Create->Browse...
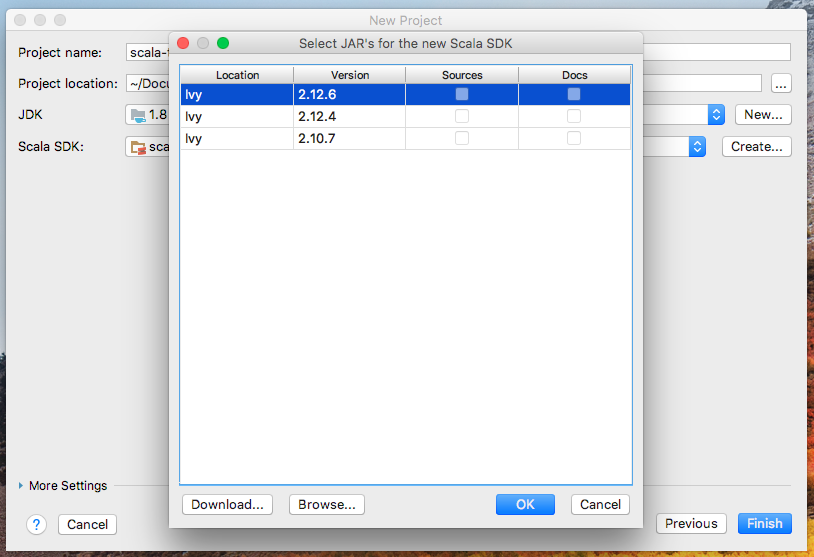
找到SCALA_HOME
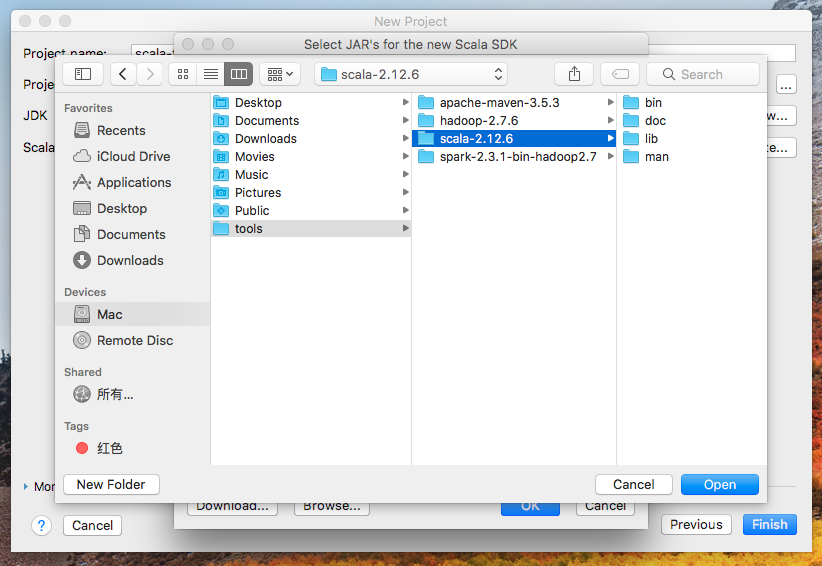
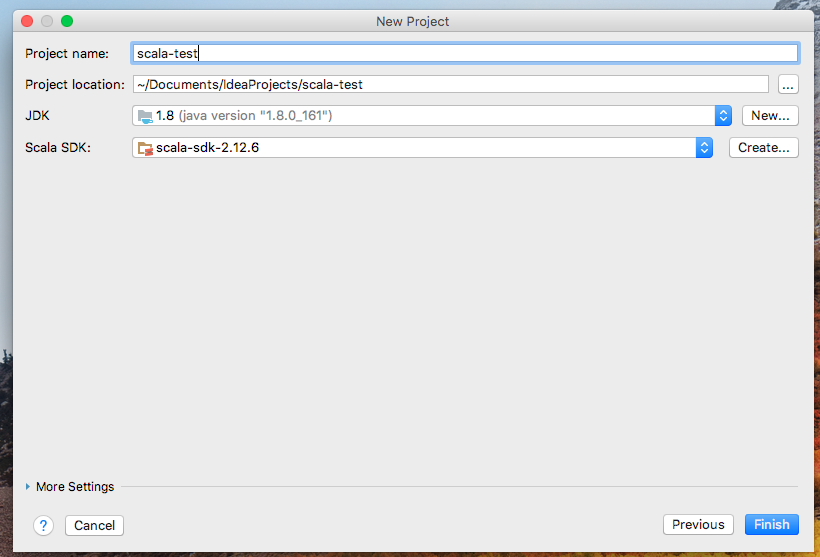
完成配置
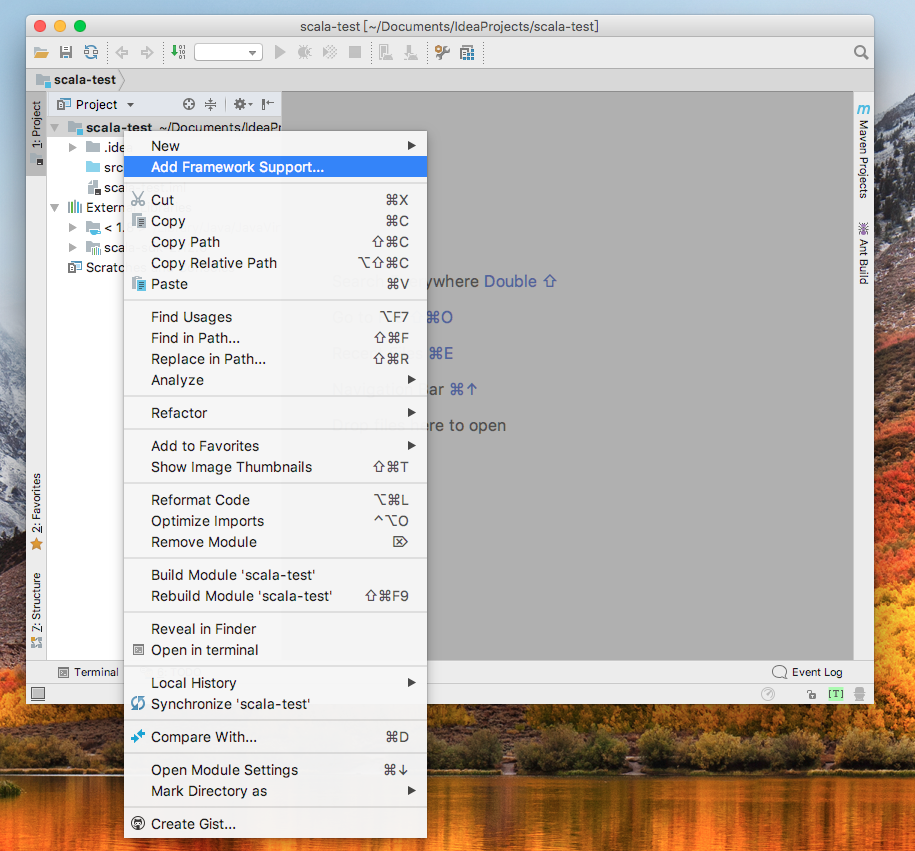
为方便开发,将项目转换为maven项目以解决繁琐的依赖包问题,项目名右键-->Add Framework Support...
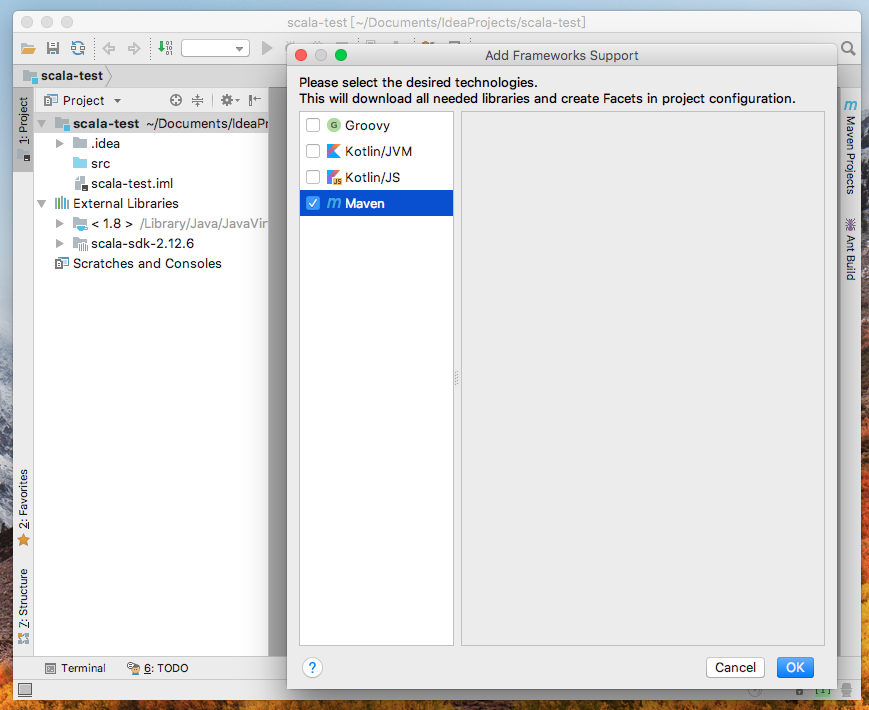
选择maven
项目会自动引入pom.xml,变为scala maven project,并在src下创建source root(可以在package上右键更改)
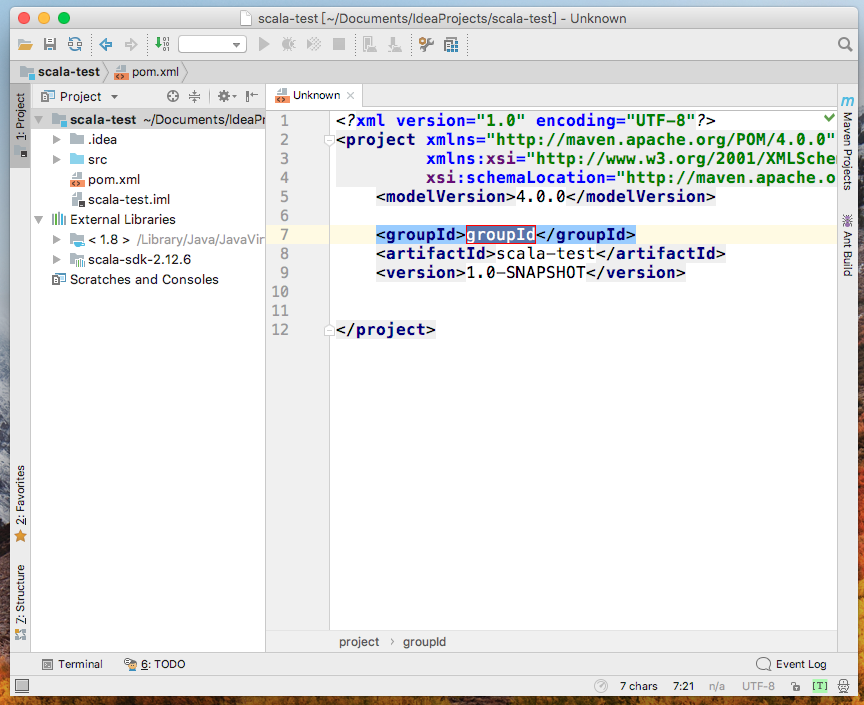
source root(该项目中为main.java)上右键-->New-->Scala Class
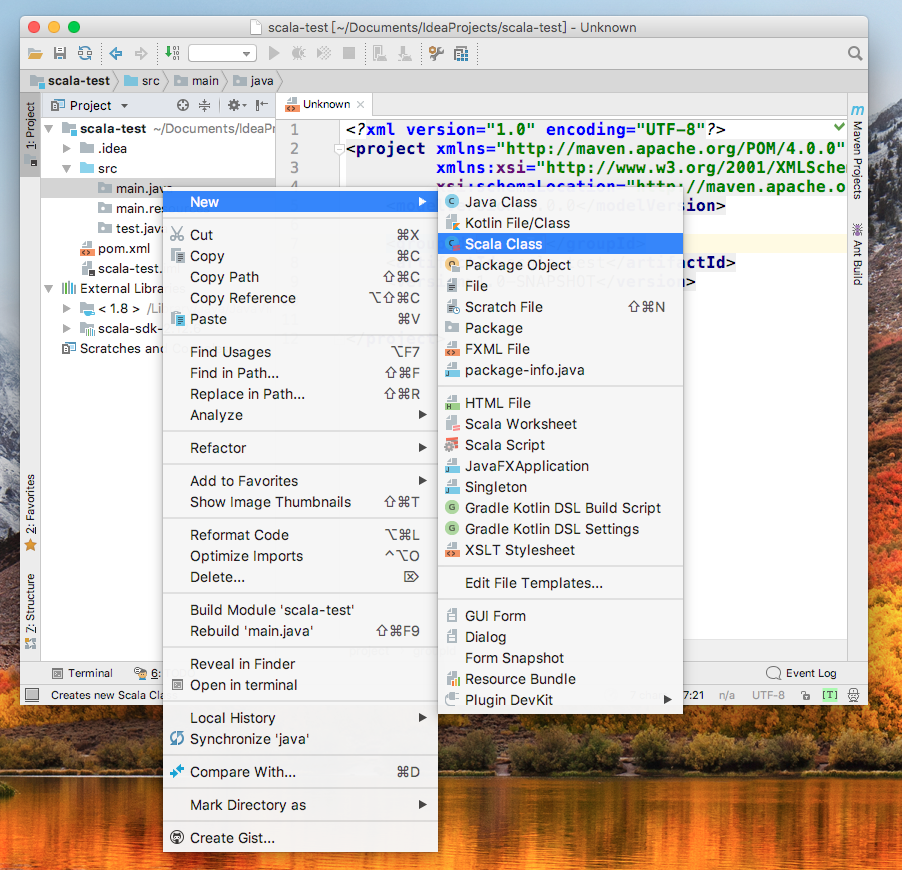
选择类型为Object,用以创建main函数
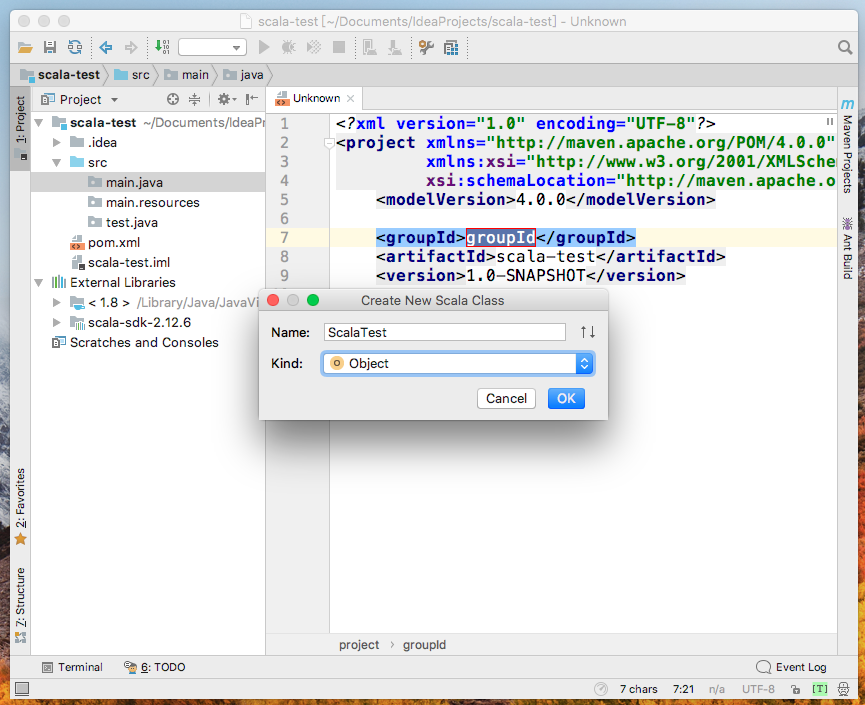
编写测试代码
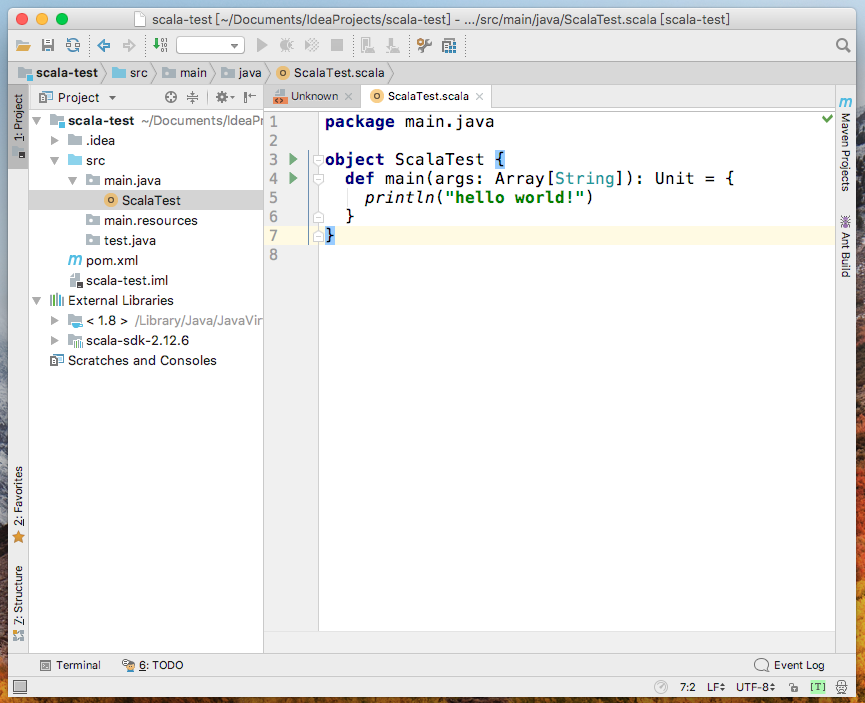
在代码空白处或项目名处右键-->Run 'ScalaTest'测试代码
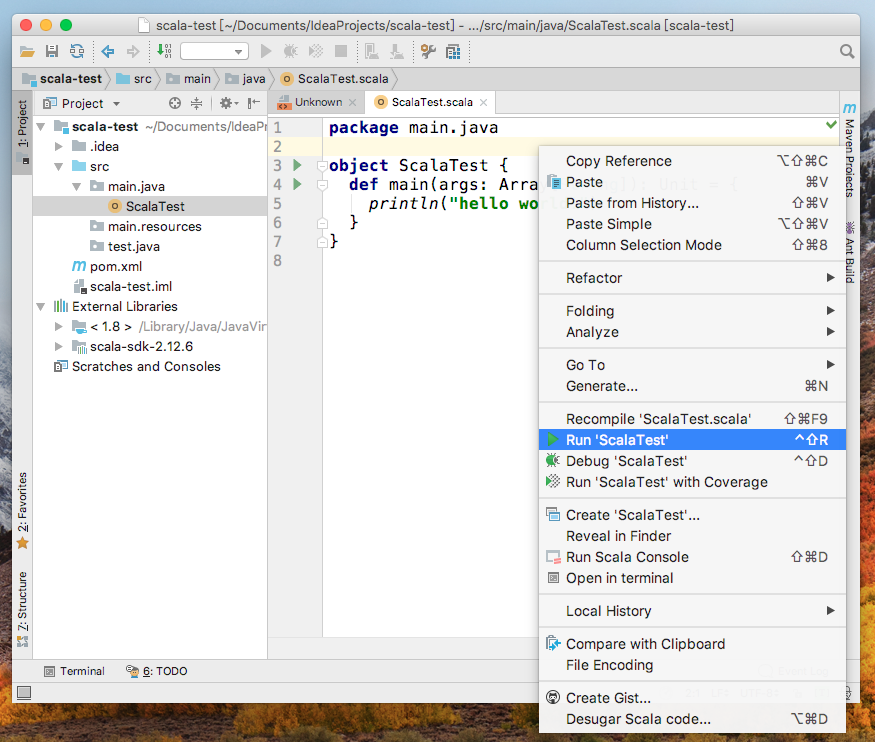
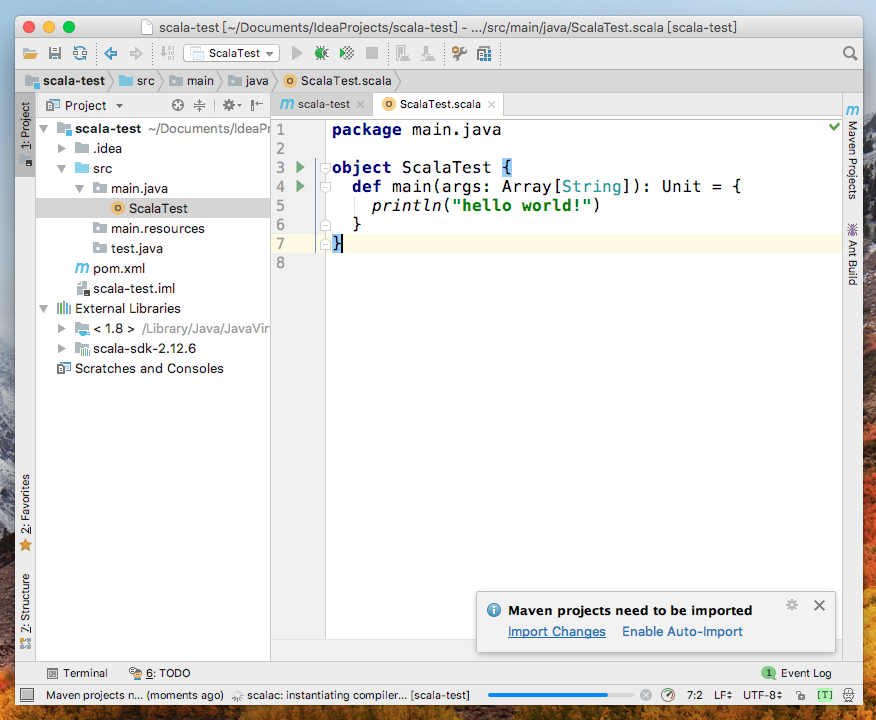
虽然引入了pom.xml,默认却不会自动import依赖包,出现提示选择“Auto-Import”
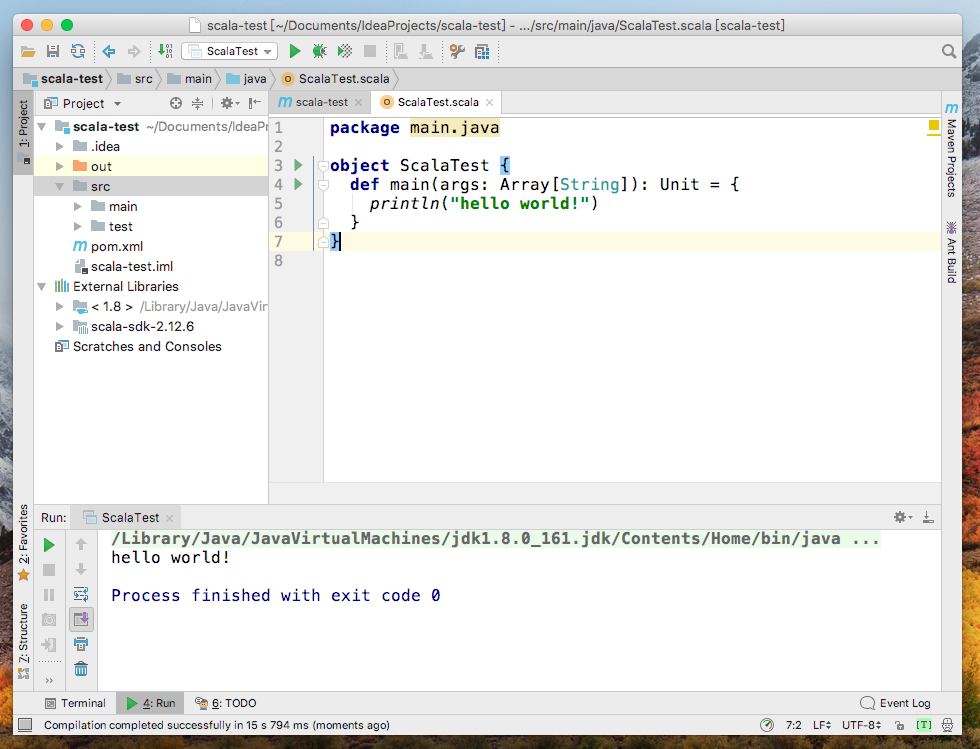
测试结果
之所以这一步这么详细是因为我发现创建项目的时候选择哪种project类型会很纠结,也没有官方标准,经过实验,推崇先创建scala project再转换为maven project;如果创建的时候选择了maven project,通过“Add Framework Support...”再引入Scala SDK也是可以的,最终效果和图中给出的差不多,但是目录结构会有差异。
注1:SCALA_HOME、JAVA_HOME在mac下设置方式:
在~/.bash_profile中添加如下指令:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_161.jdk/Contents/Home
export SCALA_HOME=/Users/<你的名字>/tools/scala-2.12.6
export PATH=$JAVA_HOME/bin:$SCALA_HOME/bin:$PATH
参考文档:官方文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号