算法工程师想进一步提高竞争力?向TensorFlow开源社区贡献你的代码吧
算法工程师为什么也要向社区贡献代码?
[作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor]
欢迎大家关注我的公众号,“互联网西门二少”,我将继续输出我的技术干货~

“做算法的人要熟悉算法框架源码吗?算法工程师难道不应该会使用框架建模就可以了吗?如何成为具有一定竞争力的算法工程师?”...
我经常被不同的人问类似这样的问题。坦白地说从我个人经验来看,身边算法做的不错的人对算法框架源码普遍熟悉,而且算法建模这件事在当前来看还并不能纯粹的与底层隔离,因为你会经常与计算性能,算法实现原理打交道。当然,我也见过一些比较浮躁的从业者,认为算法工程师应该只做建模不碰源码,这些人一般都只是根据网上教程跑通了个MNIST,ImageNet的例子就认为自己可以胜任算法工程师的工作了,这种人其实不是想做算法,而是不想写代码而已。算法门槛表面上在降低,可其实是不断升高的。一方面,学术界算法创新竞争越来越激烈,主要表现在AI相关的顶会变多,accept的paper也越来越多,多到根本看不过来,你现在所想到的模型创新,没准在另一家公司或者学校已经走到实验验证阶段了;另一方面,性能优化和定制的功能开发等工程能力越来越重要。现在来看,市场上做想要算法的人非常多,但到面试通过的概率很低,这也侧面说明了竞争门槛其实是比较高的。
但这也是机会。如果你是做算法的,请趁此机会提升自己的工程能力和算法领域内的影响力。How?其实很简单——为算法领域的知名开源软件贡献代码。因为我个人是TensorFlow的contributor,所以我以TensorFlow为例为大家介绍。
向TensorFlow社区贡献代码的步骤
第一步 Fork!
首先,进入TensorFlow的GitHub页面,地址如下:https://github.com/tensorflow/tensorflow ,可以看到如下页面。

红色框内表示当前TensorFlow这个开源项目已经有1844个人贡献过代码,想要加入这个行列的coder们请努力吧,这并没有想象中那么难。因为我们无法直接对开源项目clone开发,而只能在我们自己的仓库中开发,所以我们需要点击Fork按钮,将该项目Fork到自己的GitHub仓库名下,然后我们就可以在我们自己的仓库中看到这个项目。
第二步 Clone自己的仓库
成功Fork之后,我们就可以将它Clone下来进行开发了。每次开发之前最好切出一个分支出来,避免直接在master上做修改。
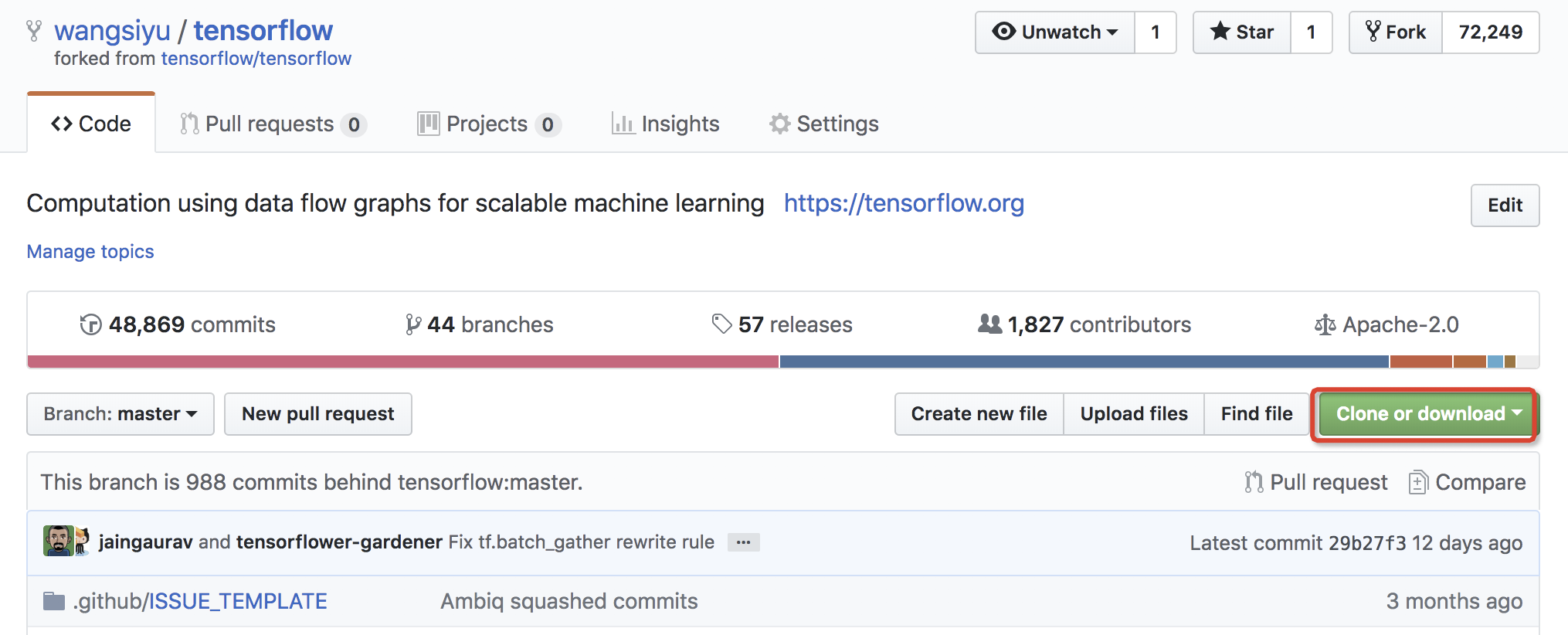
第三步 与Fork之前的开源master建立联系
自从我们Fork新项目起,我们自己仓库的master将不再与开源master有任何联系,也就是说我们自己仓库的master代码将不再随着开源master自动更新。那么如何及时更新自己的仓库呢?这需要为我们clone下来的项目添加upstream,即上游远程仓库。这非常简单,只需要一句命令即可搞定。我们需要将开源master的git地址复制下来然后添加到当前项目的,对于TensorFlow来说执行下面命令即可。
git remote add upstream git@github.com:tensorflow/tensorflow.git
这样就与开源社区master建立起了联系,我们可以看到配置文件.git/config文件中确实添加了upstream。
第四步 编写代码,提交到我们的仓库中
这一步比较常规,在本地切出开发分支,编写代码,提交到我们自己的仓库中。
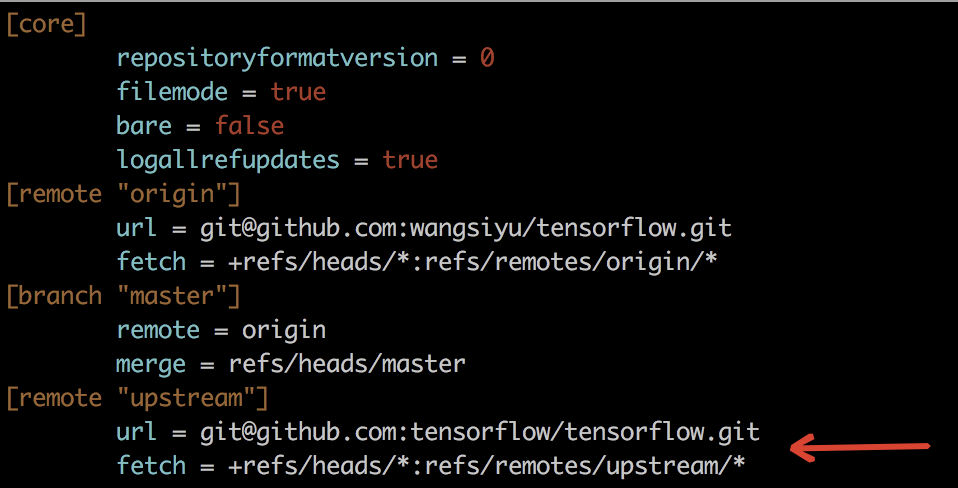
第五步 生成Pull Request
当我们将自己的commit提交到自己的GitHub仓库之后,就可以向Fork源master提交Pull Request(简称PR)申请了。首先进入自己的GitHub仓库页面,点击New pull request按钮。

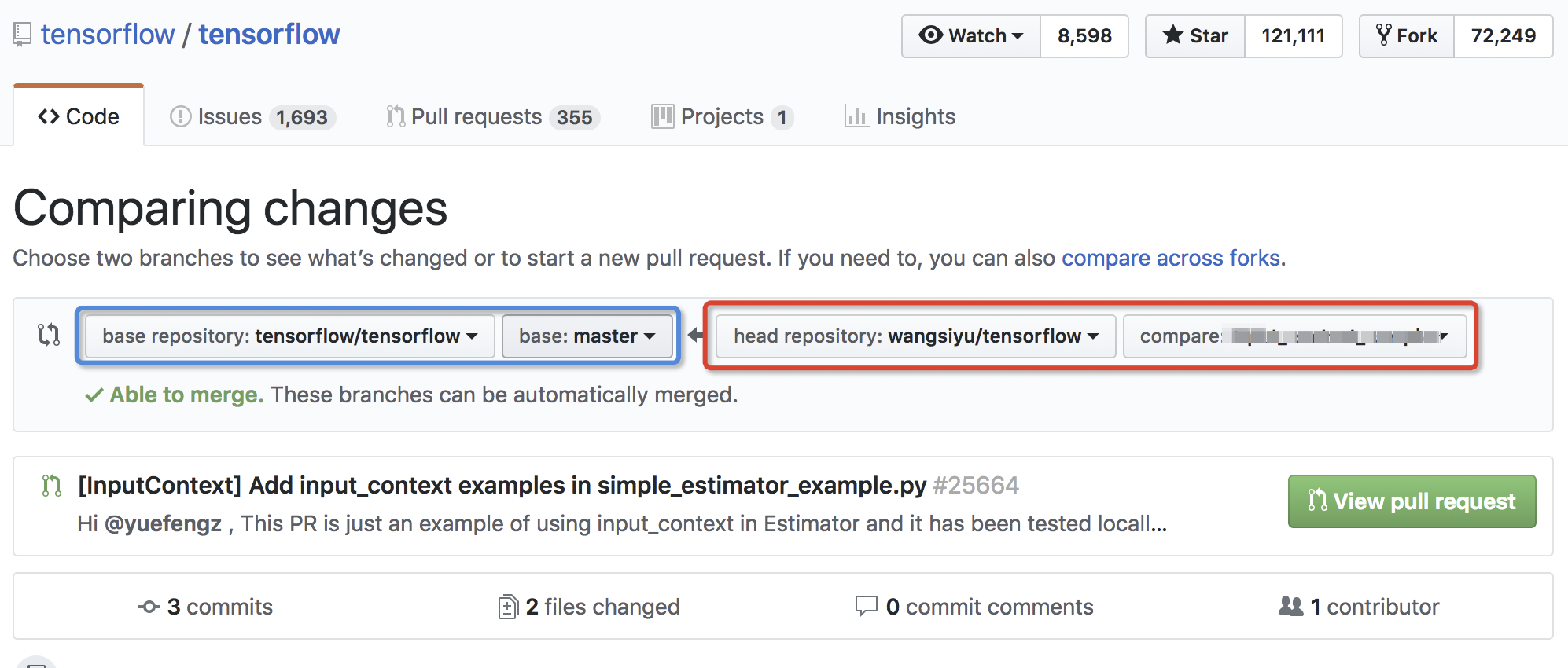
点击后进入Comparing页面,我们选择需要往Fork源merge的分支,如下所示。由于我当前这个分支已经提交了PR,但还处于review期间,所以生成的页面不太一样。
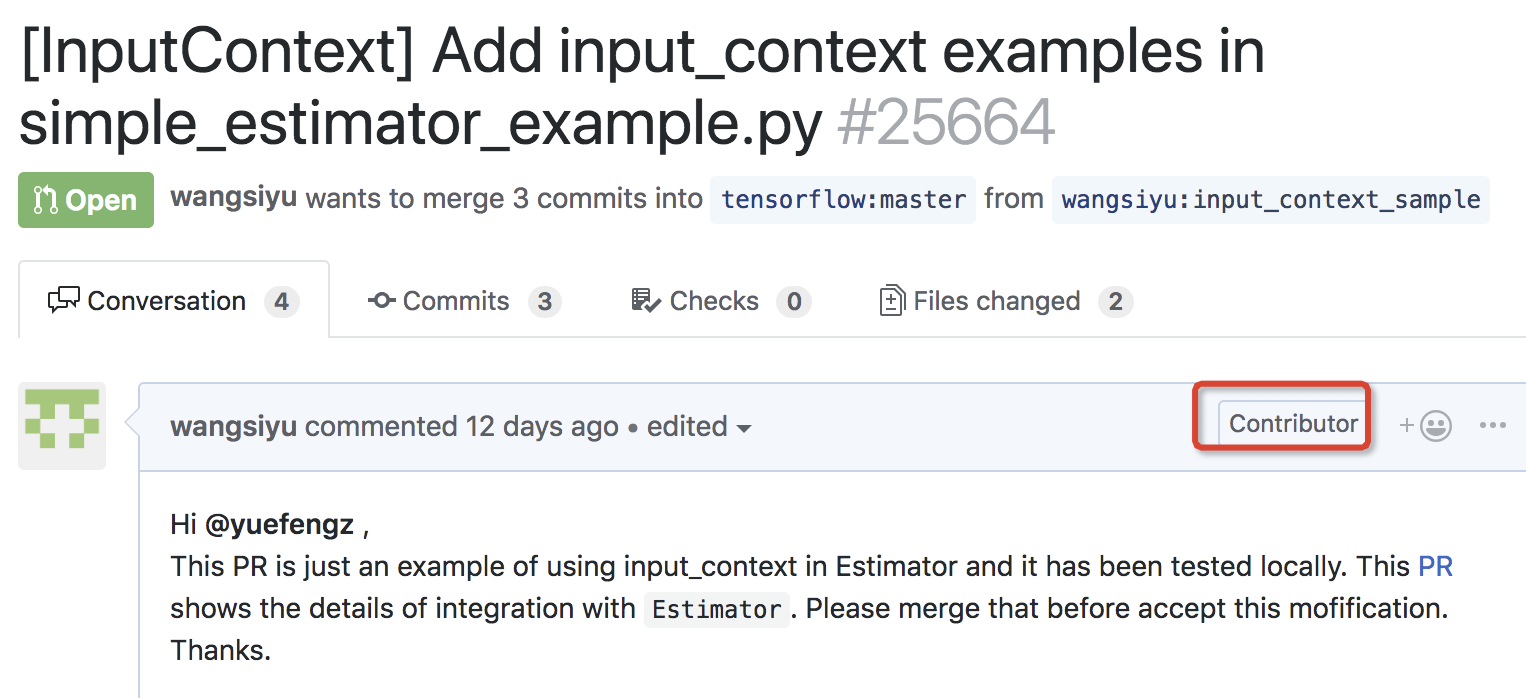
第六步 填写代码贡献说明
这是最后一步,需要在生成的页面中填写自己要贡献这段代码的原因,然后引入相关的reviewer进行讨论。不得不说,这一部分非常关键,因为大部分reviewer只会review代码规范,而这段代码的作用本身需要大家自己解释清楚。如果你曾经在该项目中贡献过代码,那么会显示Contributor字样。
自此,你成功的向开源社区提交了一个PR,离成为Contributor走进了一步。
关于PR的状态跟踪
一般情况下,TensorFlow的reviewer响应都是比较快的,而且他们对于技术讨论非常开放,也非常愿意社区积极贡献代码。Reviewer会在你的PR上提出各种Comments,在不断的代码refine之后,代码将最终成功merge到开源master中,从状态上看你的PR将会显示紫色的Merged。如果到了这一步,那么恭喜你,成功成为了TensorFlow社区的Contributor!
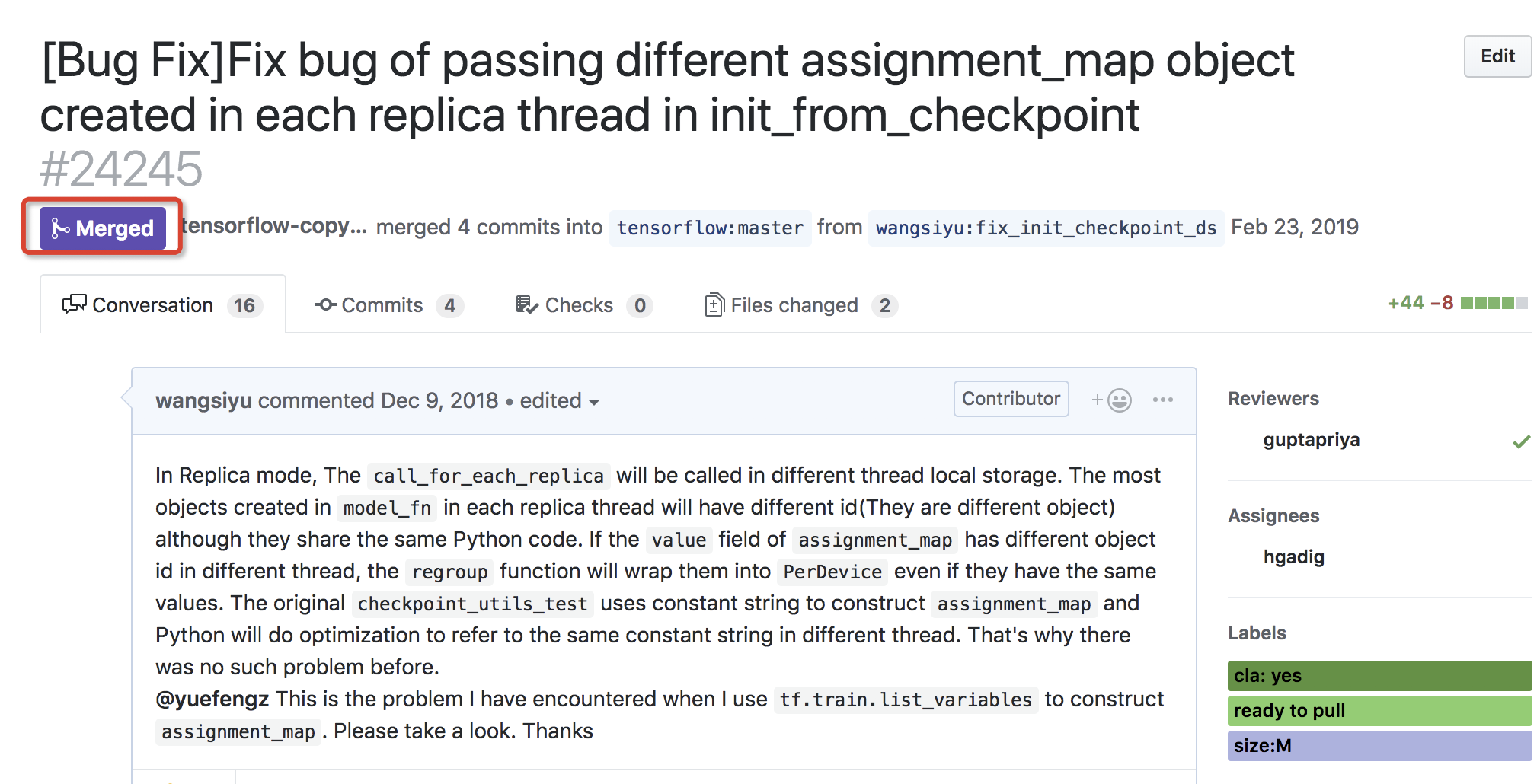
如何与开源master同步
TensorFlow社区master每天都会更新,所以建议每天做一次代码同步,非常简单,两行git命令就能搞定。
git pull upstream master
git push origin master
分别是将upstream(也就是Fork源)代码更新到本地,向origin(自己的仓库远端)更新代码。
TensorFlow发布通告中会有你的名字
因为你的贡献让TensorFlow更加完善,所以在之后的发布通告中会出现你的名字。下面的这段发布通告来自于TensorFlow 1.13.0 RC2,其实你可以从描述中看到,在1800+名Contributor中,绝大部分是Google内部的人,所以Google外部的Contributor非常少。

TensorFlow有那么多待完善的功能吗?怎么发现它们?
其实非常多。TensorFlow一大特点是通用性,希望能够在各种场景下均能够变得成熟。但是这个目的工程量浩大,不免存在Bug,设计不完善,性能不理想,功能不全面等情况。其实在使用TensorFlow建模时就会遇到他们,而且概率还真不小。当然你可以遇到问题选择绕开它们,但这可能也意味着你错失了一个提PR的机会。提PR的前提是你必须对源码有所了解,所以算法工程师们在读paper读累了的时候不妨换换思路,每天看一点TensorFlow源码多提升一些工程素养。
TensorFlow社区值得关注的东西
TensorFlow是Google重要的算法军火库,Google围绕着TensorFlow本身还做了其他子项目,他们也非常重要。另外,也可以加入讨论组。
TensorFlow生态中的其他子项目
TensorFlow生态中子项目相当丰富,有前端TensorBoard,有易用性框架Estimator等等。这些子项目也同样需要社区贡献力量。
TensorFlow 2.0的标准制定项目——Community
Community子项目其实就是TensorFlow的RFC文档,它是TensorFlow 2.0的标准,里面含有一些模块和接口的设计。为什么要关注RFC文档?这是因为TensorFlow的发展比较快,经常出现某些模块被弃用,某些新模块将要大力发展的情况。这些信息对于开发者非常重要,如果你想共享一段代码,但它与社区的发展标准背道而驰,那么将是无用功,所以RFC文档对于避免虚工是非常有用的。但一个标准的提出也需要经过社区的审核和讨论,所以如果有自己的想法,可以在Community中提出自己的comments,引入更多的人参与讨论。
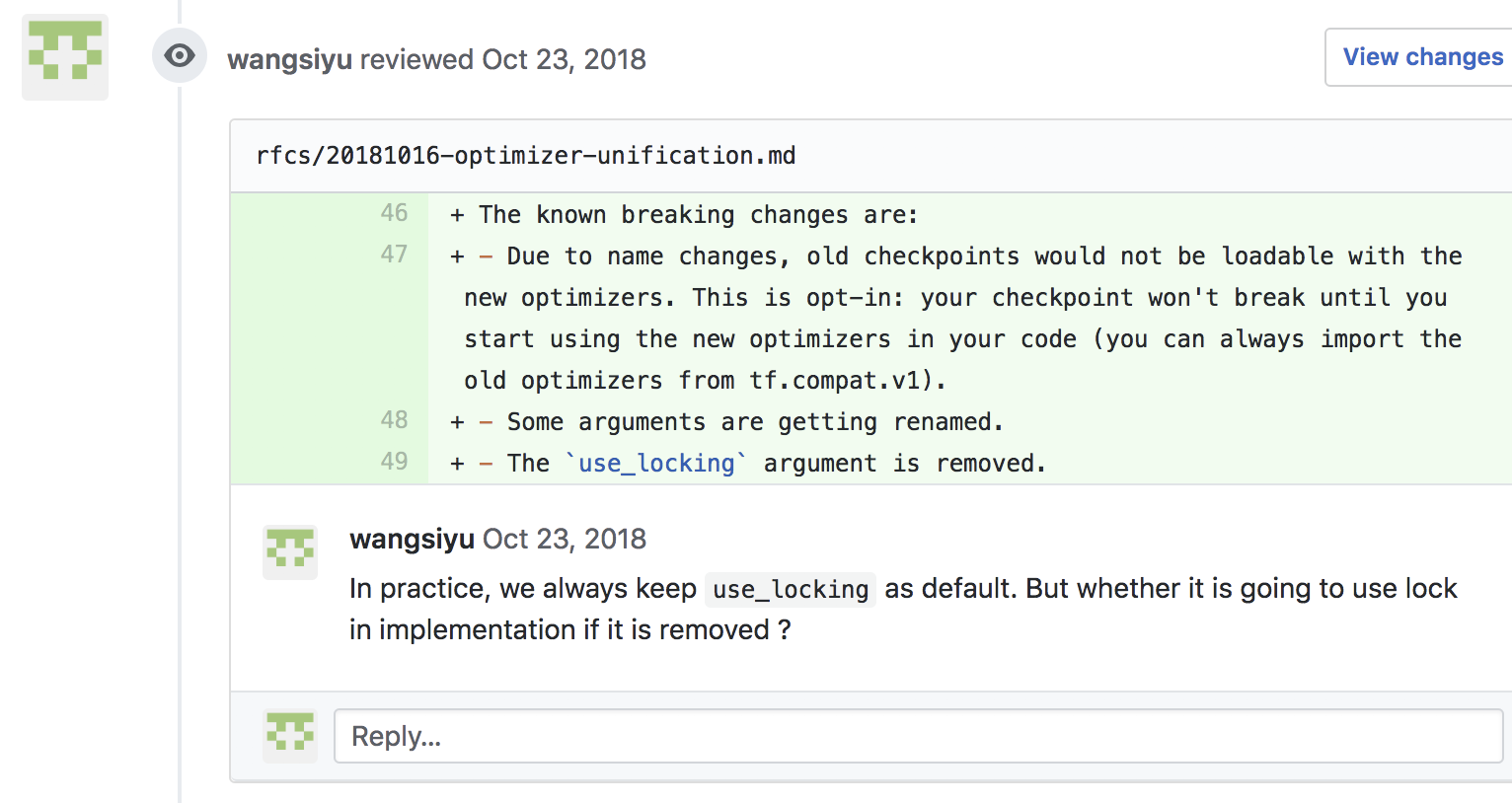
扩展——与TensorFlow有关的项目
从TensorFlow项目这一个点出发,我们可以不怎么费力气地学习到更多的开源项目,而且TensorFlow架构和源码设计足够复杂,这使得我们在看其他相关项目时变得相对轻松。比如当你对TensorFlow使用单机多卡GPU通信感兴趣时,可以参考NCCL。当你对多机分布式感兴趣时,你或许可以看看Uber开源的Horovod。当你想要研究不同框架之间的差异时,你也许可以看看Pytorch,caffe2和MXNet。这种辐射式的积累会让我们学习更多的软件设计哲学。
写在最后
由于本人也是算法工程师,工作中不仅是TensorFlow的用户,也在自己所任职的公司参与TensorFlow的定制开发与性能优化。从我个人角度来看,算法工程师这个职位不得不说是含有大量水分的,一方面真正懂算法能够在AI顶会发一些高质量paper的人占比并不高,另一方面,在算法工程上理解较深的人也并不多,而在算法和工程两方面都比较强的人就更少了。现在属于算法领域较热的时段,这方面的油水,薪资竞争力和需求量都很大,所以市场上存在很多想要进入这个领域的人,这是好事。但是如果一个人自己跑几个模型例子就声称自己可以做算法并且十分反感写代码的话,那他在算法领域也不会有很好的发展。除非,你是一个算法造诣非常高的天才并且能够胜任算法科学家的人。否则,请不要欺骗自己,认真培养你的算法能力和工程能力,毕竟你的目标还是一个合格的算法工程师。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号