filebeat原理解析
cat:一次查看所有内容,不过文本行数过多,不能全部显示
less:查看长文本时候使用,可以翻页
head:查看文件开始,默认10行
tail:查看文件结尾,默认10行
而对于tail也可以一直查看文件结尾,类似于top命令
用tail -f 用于实时查询linux下的日志文件
Filebeat的可靠性很强,可以保证日志At least once的上报,同时也考虑了日志搜集中的各类问题,例如日志断点续读、文件名更改、日志Truncated等。
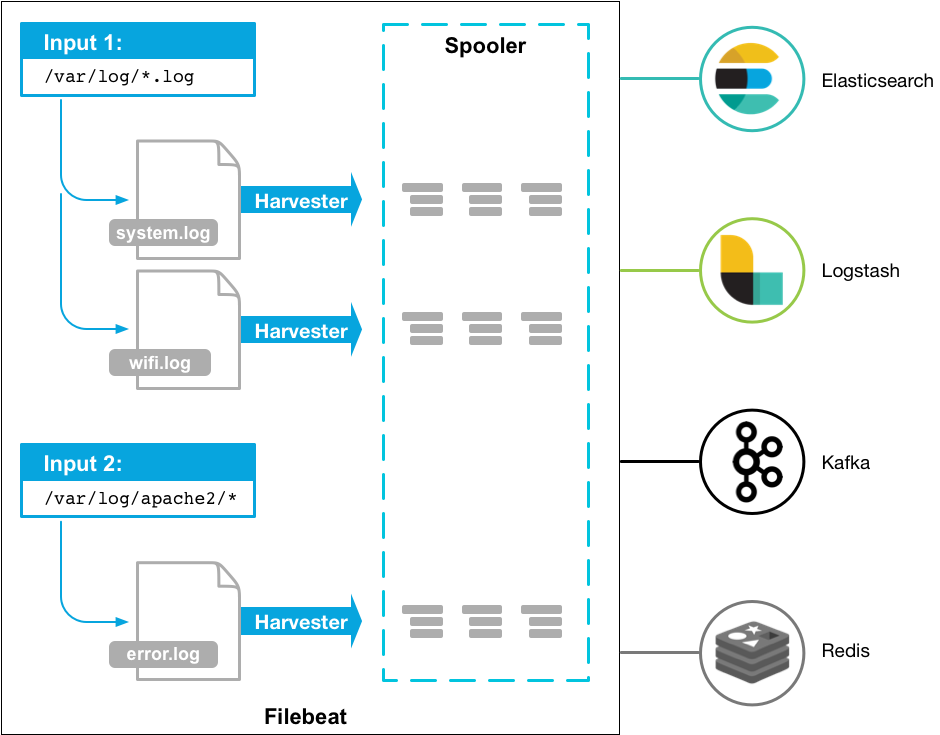
Filebeat涉及两个组件:查找器prospector和采集器harvester,来读取文件(tail file)并将事件数据发送到指定的输出。
启动Filebeat时,它会启动一个或多个查找器,查看你为日志文件指定的本地路径。对于prospector所在的每个日志文件,prospector启动harvester。每个harvester都会
为新内容读取单个日志文件,并将新日志数据发送到libbeat,后者将聚合事件并将聚合数据发送到你为Filebeat配置的输出。
部分资料直接复制网络中其他文章,仅供个人参考学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号