摘要: 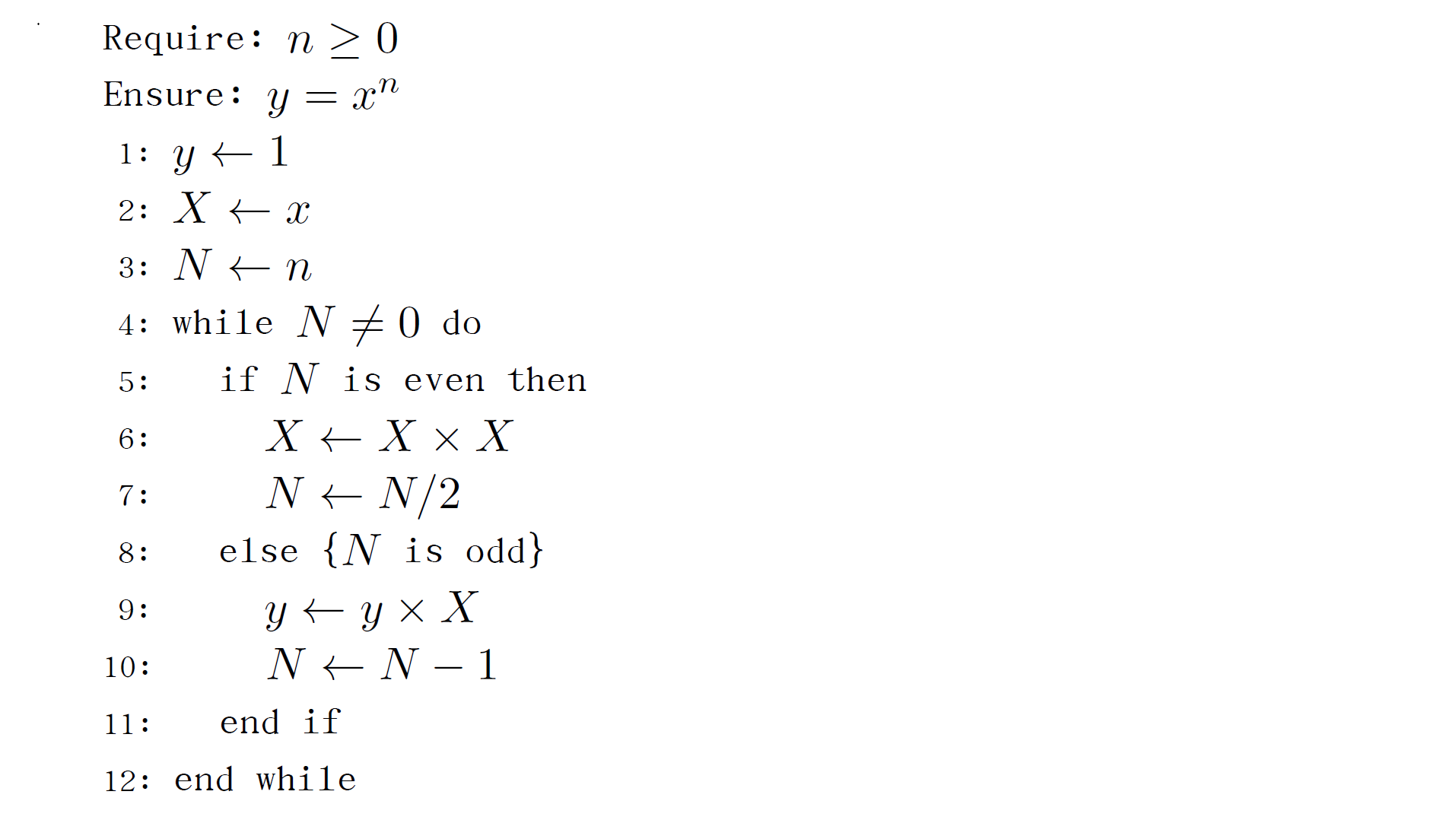 接上一篇介绍的基本Markdown通过pandoc编译转为Beamer风格文档的文章,本文主要介绍一些Markdown转Beamer其中的进阶用法。如Mermaid流程图,和Algorithms算法伪代码的使用等。 阅读全文
接上一篇介绍的基本Markdown通过pandoc编译转为Beamer风格文档的文章,本文主要介绍一些Markdown转Beamer其中的进阶用法。如Mermaid流程图,和Algorithms算法伪代码的使用等。 阅读全文
接上一篇介绍的基本Markdown通过pandoc编译转为Beamer风格文档的文章,本文主要介绍一些Markdown转Beamer其中的进阶用法。如Mermaid流程图,和Algorithms算法伪代码的使用等。 阅读全文
posted @ 2025-01-20 17:27
DECHIN
阅读(735)
评论(0)
推荐(0)
摘要: 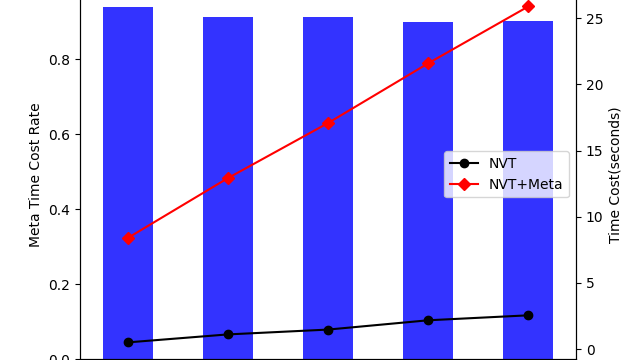 接前一篇关于PySAGES结合CudaSPONGE使用方法的文章,本文主要还是使用了一样的测试案例。仅通过不同的测试步长,来定性的分析PySAGES的MetaDynamics实现方案结合MD软件之后的性能数据。 阅读全文
接前一篇关于PySAGES结合CudaSPONGE使用方法的文章,本文主要还是使用了一样的测试案例。仅通过不同的测试步长,来定性的分析PySAGES的MetaDynamics实现方案结合MD软件之后的性能数据。 阅读全文
接前一篇关于PySAGES结合CudaSPONGE使用方法的文章,本文主要还是使用了一样的测试案例。仅通过不同的测试步长,来定性的分析PySAGES的MetaDynamics实现方案结合MD软件之后的性能数据。 阅读全文
posted @ 2025-01-20 16:04
DECHIN
阅读(142)
评论(0)
推荐(0)
 通过使用pandoc,使得我们可以直接将普通的Markdown文件编译成一个Latex Beamer PDF格式的演示文稿文件。相比于RMarkdown有更强的灵活性和通用性,只是不能在生成文稿时运行相关代码,不过这点对于那些只需要一个“静态”演示文稿的人来说影响不大。
通过使用pandoc,使得我们可以直接将普通的Markdown文件编译成一个Latex Beamer PDF格式的演示文稿文件。相比于RMarkdown有更强的灵活性和通用性,只是不能在生成文稿时运行相关代码,不过这点对于那些只需要一个“静态”演示文稿的人来说影响不大。  本文探索并梳理了一下CUDA SPONGE高性能分子模拟采样软件,和PySAGES高性能增强采样软件,这两者强强联合的MD模拟新范式。
本文探索并梳理了一下CUDA SPONGE高性能分子模拟采样软件,和PySAGES高性能增强采样软件,这两者强强联合的MD模拟新范式。 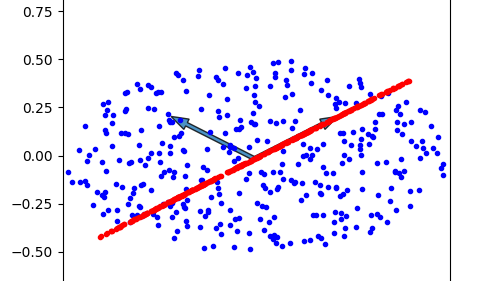 接上一篇文章介绍的矩阵特征分解,本文介绍了矩阵特征分解在主成分分析(PCA)算法中的应用。对于PCA算法,最直观的理解就是,在高维数据中找到一个低维的空间,使得所有的数据点投影到该低维空间之后尽可能的分离。
接上一篇文章介绍的矩阵特征分解,本文介绍了矩阵特征分解在主成分分析(PCA)算法中的应用。对于PCA算法,最直观的理解就是,在高维数据中找到一个低维的空间,使得所有的数据点投影到该低维空间之后尽可能的分离。 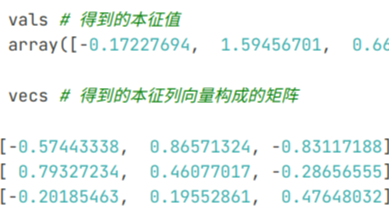 本文介绍了一下使用Numpy计算矩阵的特征值求解和特征值分解问题。Numpy的eig特征求解函数可以直接输出给定矩阵所有的特征值,和对应的所有特征列向量所构成的矩阵。再使用Numpy的矩阵求逆函数,即可得到相关矩阵的EVD特征值分解。
本文介绍了一下使用Numpy计算矩阵的特征值求解和特征值分解问题。Numpy的eig特征求解函数可以直接输出给定矩阵所有的特征值,和对应的所有特征列向量所构成的矩阵。再使用Numpy的矩阵求逆函数,即可得到相关矩阵的EVD特征值分解。 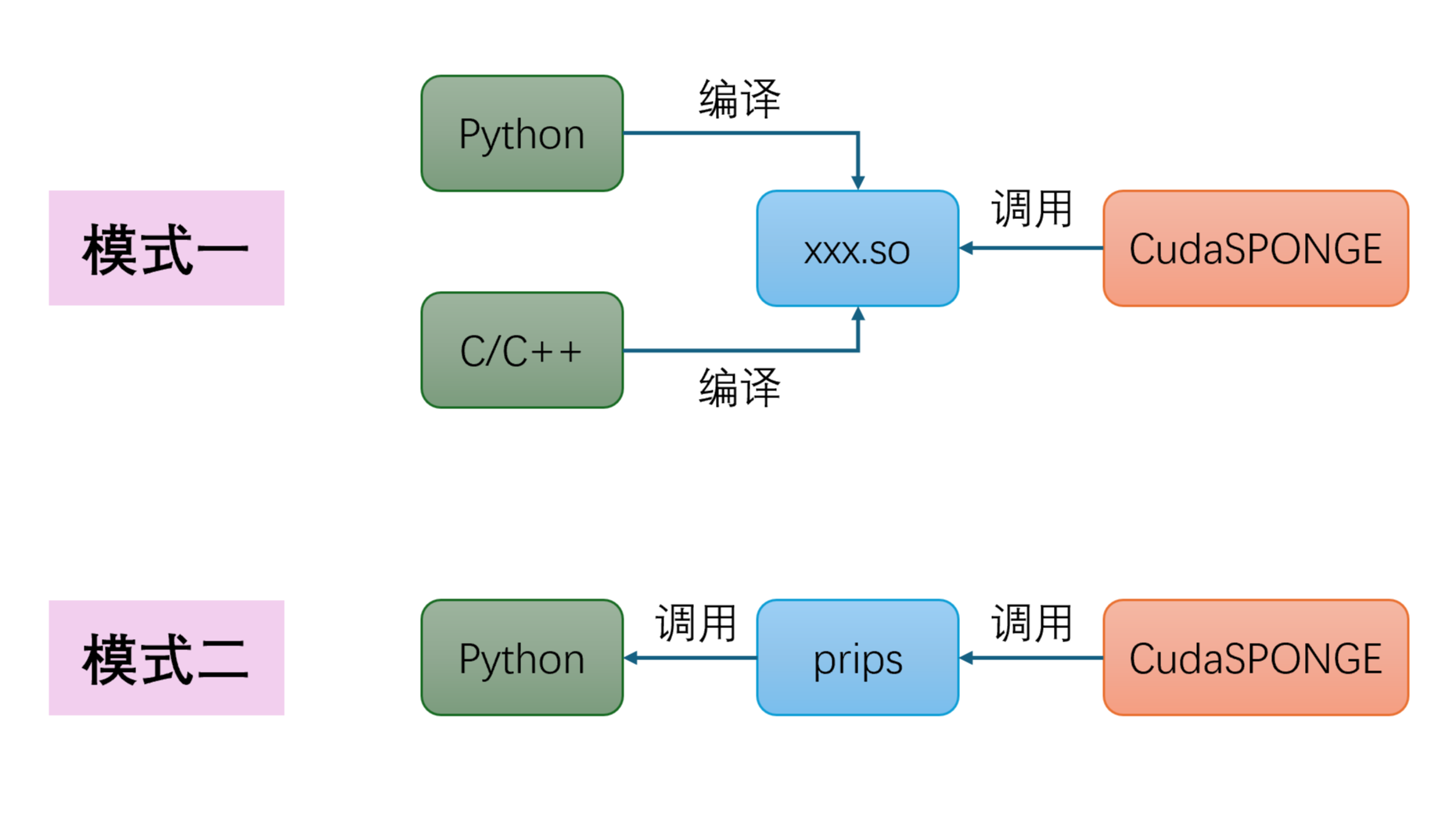 本文介绍了高性能GPU分子动力学模拟软件CudaSPONGE的Python API接口,通过官方开发的prips插件,使得我们可以在Python框架下很方便的开发一些分子动力学模拟的Force Wrapper,例如Meta Dynamics中就有很多可以外界的工具,非常方便开发者的二次开发,同时又能够兼顾到性能。
本文介绍了高性能GPU分子动力学模拟软件CudaSPONGE的Python API接口,通过官方开发的prips插件,使得我们可以在Python框架下很方便的开发一些分子动力学模拟的Force Wrapper,例如Meta Dynamics中就有很多可以外界的工具,非常方便开发者的二次开发,同时又能够兼顾到性能。 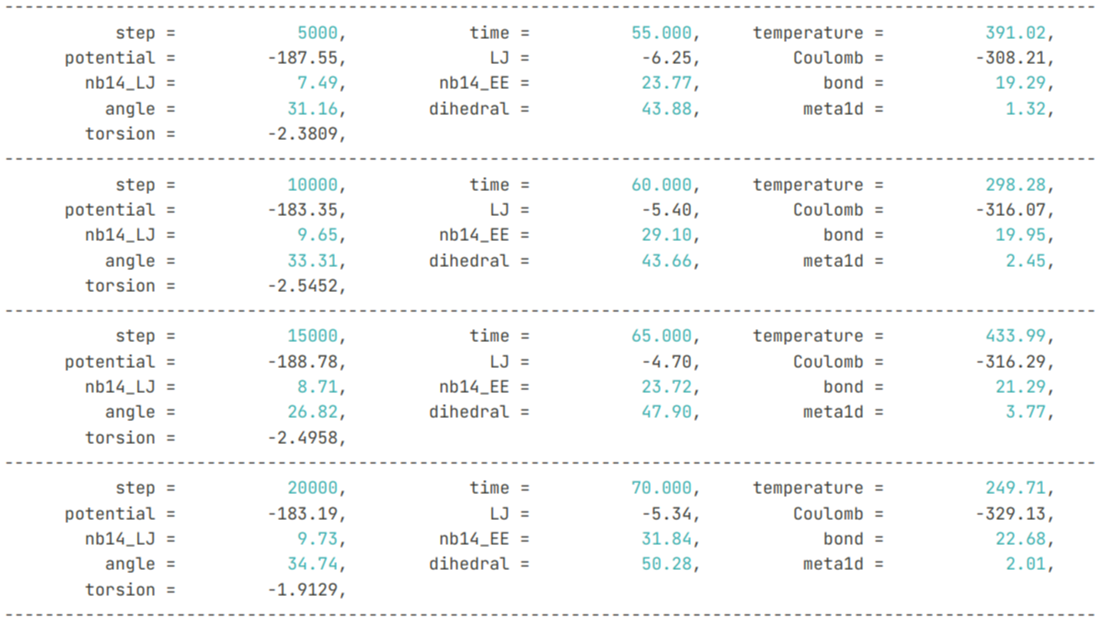 本文简单介绍了一下CudaSPONGE高性能分子动力学模拟软件,其基于原生的CUDA C开发,具有极高的模拟效率。结合前处理工具Xponge用于生成和处理输入文件,可以很好的兼容目前常用的很多力场形式。
本文简单介绍了一下CudaSPONGE高性能分子动力学模拟软件,其基于原生的CUDA C开发,具有极高的模拟效率。结合前处理工具Xponge用于生成和处理输入文件,可以很好的兼容目前常用的很多力场形式。  本文仅介绍一个可以在Jax的Jit即时编译模式下,也能够正常通过print打印函数来输出Jax Array内容的方法。
本文仅介绍一个可以在Jax的Jit即时编译模式下,也能够正常通过print打印函数来输出Jax Array内容的方法。 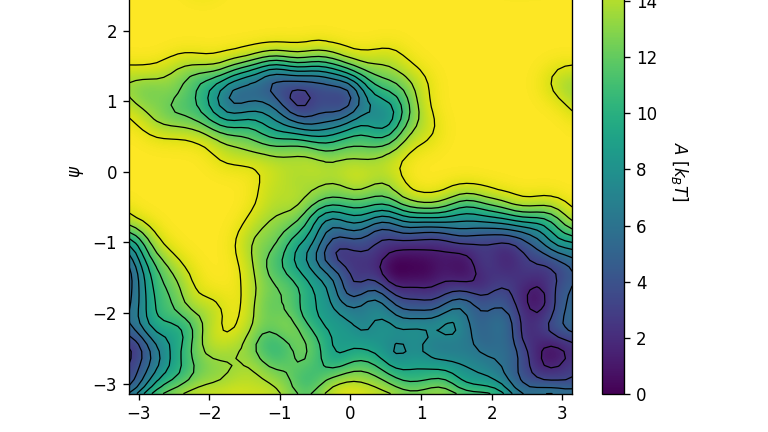 本文主要介绍了增强采样外接软件PySAGES的基本安装和使用方法,重点是安装过程中没有写清楚的一些环境依赖和可能出现的问题介绍,以及相应的解决方案。并简单的梳理了一下PySAGES软件的工作流机制,其能够做到Zero Copy,并使得Enhanced Sampling不再成为很多模拟的Bottleneck,这是一个相当出色的结果。
本文主要介绍了增强采样外接软件PySAGES的基本安装和使用方法,重点是安装过程中没有写清楚的一些环境依赖和可能出现的问题介绍,以及相应的解决方案。并简单的梳理了一下PySAGES软件的工作流机制,其能够做到Zero Copy,并使得Enhanced Sampling不再成为很多模拟的Bottleneck,这是一个相当出色的结果。  本文介绍了AlphaFold2中所使用到的开源分子动力学模拟软件OpenMM的安装和基础使用方法,其中包含了pdbfixer蛋白质构象文件修复工具的介绍和一个真空蛋白体系的能量极小化示例,并且提供了一些有可能在OpenMM的安装和使用过程中遇到的问题和解决方法。
本文介绍了AlphaFold2中所使用到的开源分子动力学模拟软件OpenMM的安装和基础使用方法,其中包含了pdbfixer蛋白质构象文件修复工具的介绍和一个真空蛋白体系的能量极小化示例,并且提供了一些有可能在OpenMM的安装和使用过程中遇到的问题和解决方法。  在使用Jax的过程中,有时候会遇到函数输出是一个动态的Shape,这种情况下我们很难利用到Jax的即时编译的功能,不能使得性能最大化。这也是使用Tensor数据结构来计算的一个特点,有好有坏。本文介绍了Jax的另外一个函数NonZero,可以使得我们能够编译那些动态Shape输出的函数。
在使用Jax的过程中,有时候会遇到函数输出是一个动态的Shape,这种情况下我们很难利用到Jax的即时编译的功能,不能使得性能最大化。这也是使用Tensor数据结构来计算的一个特点,有好有坏。本文介绍了Jax的另外一个函数NonZero,可以使得我们能够编译那些动态Shape输出的函数。  本文总结了一个在conda环境下使用git pull出现报错:symbol lookup error: /lib/x86_64-linux-gnu/libp11-kit.so.0: undefined symbol: ffi_type_pointer的问题。通过建立软链接到版本更新的系统环境下的动态链接库中,即可解决该问题。
本文总结了一个在conda环境下使用git pull出现报错:symbol lookup error: /lib/x86_64-linux-gnu/libp11-kit.so.0: undefined symbol: ffi_type_pointer的问题。通过建立软链接到版本更新的系统环境下的动态链接库中,即可解决该问题。  接上一篇对于MindSpore-2.4-gpu版本的安装介绍,本文主要介绍一些MindSpore-2.4版本中的新特性,例如使用hal对设备和流进行管理,进而支持Stream流计算。另外还有类似于Jax中的fori_loop方法,MindSpore最新版本中也支持了ForiLoop循环体,使得循环的执行更加高效,也是端到端自动微分的强大利器之一。
接上一篇对于MindSpore-2.4-gpu版本的安装介绍,本文主要介绍一些MindSpore-2.4版本中的新特性,例如使用hal对设备和流进行管理,进而支持Stream流计算。另外还有类似于Jax中的fori_loop方法,MindSpore最新版本中也支持了ForiLoop循环体,使得循环的执行更加高效,也是端到端自动微分的强大利器之一。  本文介绍了在Ubuntu-20.04系统下安装最新的MindSpore-2.4-for-GPU版本的方法,以及安装过程中有可能出现的一些问题。虽然在MindSpore的正式版本中已经不再支持GPU硬件后端,但是开发版本目前还是持续在支持的,并且其中包含了2.3和2.4版本的新特性,只是算子层面没有更新和优化。对于GPU后端的MindSpore用户来说,也算是一个好消息。
本文介绍了在Ubuntu-20.04系统下安装最新的MindSpore-2.4-for-GPU版本的方法,以及安装过程中有可能出现的一些问题。虽然在MindSpore的正式版本中已经不再支持GPU硬件后端,但是开发版本目前还是持续在支持的,并且其中包含了2.3和2.4版本的新特性,只是算子层面没有更新和优化。对于GPU后端的MindSpore用户来说,也算是一个好消息。  浙公网安备 33010602011771号
浙公网安备 33010602011771号