摘要: 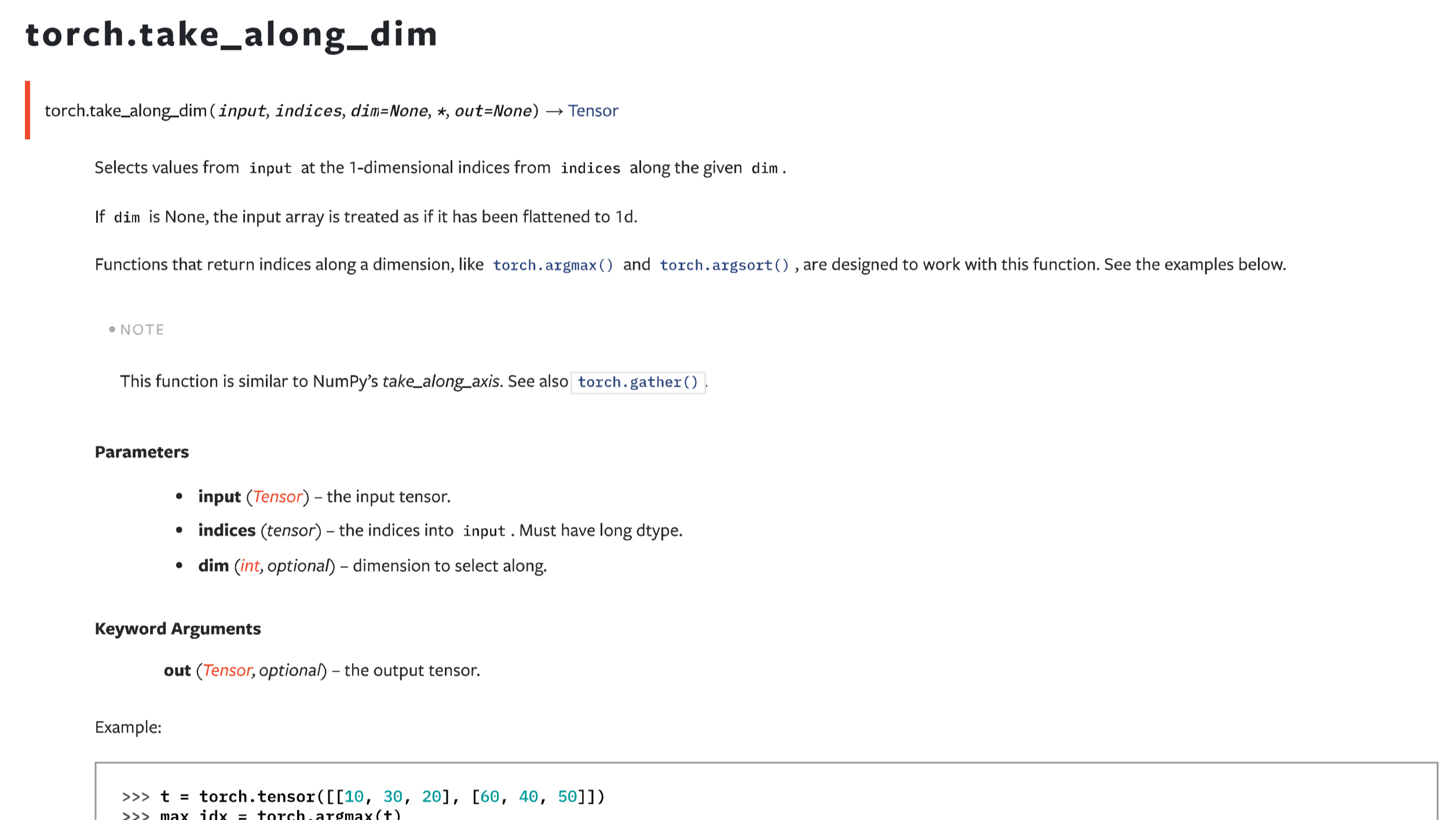 接前面一篇take_along_axis的文章,本文主要介绍在PyTorch框架下,功能基本一样的函数take_along_dim。二者除了命名和一些关键词参数不一致之外,用法是一样的。需要注意的是,两者都要求输入的数组和索引数组维度数量一致。在特定场景下,需要手动进行扩维。 阅读全文
接前面一篇take_along_axis的文章,本文主要介绍在PyTorch框架下,功能基本一样的函数take_along_dim。二者除了命名和一些关键词参数不一致之外,用法是一样的。需要注意的是,两者都要求输入的数组和索引数组维度数量一致。在特定场景下,需要手动进行扩维。 阅读全文
接前面一篇take_along_axis的文章,本文主要介绍在PyTorch框架下,功能基本一样的函数take_along_dim。二者除了命名和一些关键词参数不一致之外,用法是一样的。需要注意的是,两者都要求输入的数组和索引数组维度数量一致。在特定场景下,需要手动进行扩维。 阅读全文
posted @ 2025-07-17 10:18
DECHIN
阅读(303)
评论(0)
推荐(0)
 本文简单的介绍了一个在Pytorch中对张量进行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的区别。在其他框架中我们可以直接使用slice的方法对一个张量做逆序,但是在Pytorch中,可能需要使用到一个flip函数。
本文简单的介绍了一个在Pytorch中对张量进行逆序操作的方法相比于其他的框架,例如numpy和mindspore等的区别。在其他框架中我们可以直接使用slice的方法对一个张量做逆序,但是在Pytorch中,可能需要使用到一个flip函数。  本文介绍了在PyTorch中直接使用幂次函数计算有可能导致的计算结果异常的问题。由于PyTorch中并未像Numpy和MindSpore一样直接支持cbrt开立方函数,因此这里也提供了一个在PyTorch中计算开立方的函数。
本文介绍了在PyTorch中直接使用幂次函数计算有可能导致的计算结果异常的问题。由于PyTorch中并未像Numpy和MindSpore一样直接支持cbrt开立方函数,因此这里也提供了一个在PyTorch中计算开立方的函数。  本文简单的介绍了一下在空白的Ubuntu Linux中安装conda的方法和脚本,其中包含了CUDA部分的安装。
本文简单的介绍了一下在空白的Ubuntu Linux中安装conda的方法和脚本,其中包含了CUDA部分的安装。  本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。
本文介绍了MindSpore中的tensor_scatter_add算子的用法,可以对一个多维的tensor在指定的index上面进行加和操作。在PyTorch中虽然也有一个叫scatter_add的算子,但是本质上来说两者是完全不一样的操作。  本文通过2个实际的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的异同点。两者的输入都是tensor-axis-index,一个是输入顺序上略有区别,另一个是对于输入的张量索引维度的要求。在PyTorch中,如果我们要实现类似于MindSpore中的gather功能,需要手动对输入索引的维度操作一下。
本文通过2个实际的案例,演示了一下gather算子在MindSpore框架下PyTorch框架下的异同点。两者的输入都是tensor-axis-index,一个是输入顺序上略有区别,另一个是对于输入的张量索引维度的要求。在PyTorch中,如果我们要实现类似于MindSpore中的gather功能,需要手动对输入索引的维度操作一下。  本文介绍了在pytorch和mindspore中两种计算张量最大值的算子,如果直接使用max算子,两者的输出都是最大值元素和最大值索引。但是mindspore中额外的支持了ReduceMax算子,可以允许我们只输出最大值而不输出最大值索引。
本文介绍了在pytorch和mindspore中两种计算张量最大值的算子,如果直接使用max算子,两者的输出都是最大值元素和最大值索引。但是mindspore中额外的支持了ReduceMax算子,可以允许我们只输出最大值而不输出最大值索引。  本文通过几个示例,介绍了在Python、Numpy和PyTorch三个不同的框架下,对于求余数函数的定义。比较特殊的是pytorch中的fmod函数,并不符合数学上的求余数方法,而是需要使用remainder函数。
本文通过几个示例,介绍了在Python、Numpy和PyTorch三个不同的框架下,对于求余数函数的定义。比较特殊的是pytorch中的fmod函数,并不符合数学上的求余数方法,而是需要使用remainder函数。  本文介绍了在Python的classmethod装饰的类方法的cls变量的意义,通过几个不同的示例对比,凸显cls变量在Python编程中的应用场景。对于大多数的场景来说,使用普通的Python类和函数定义即可。如果需要在类的外部使用类的内部函数,但是可能有多个不同初始化的类输入,那么可以使用staticmethod进行装饰。如果只有一个类,而有多种不同的输入场景下,可以使用classmethod进行装饰。
本文介绍了在Python的classmethod装饰的类方法的cls变量的意义,通过几个不同的示例对比,凸显cls变量在Python编程中的应用场景。对于大多数的场景来说,使用普通的Python类和函数定义即可。如果需要在类的外部使用类的内部函数,但是可能有多个不同初始化的类输入,那么可以使用staticmethod进行装饰。如果只有一个类,而有多种不同的输入场景下,可以使用classmethod进行装饰。 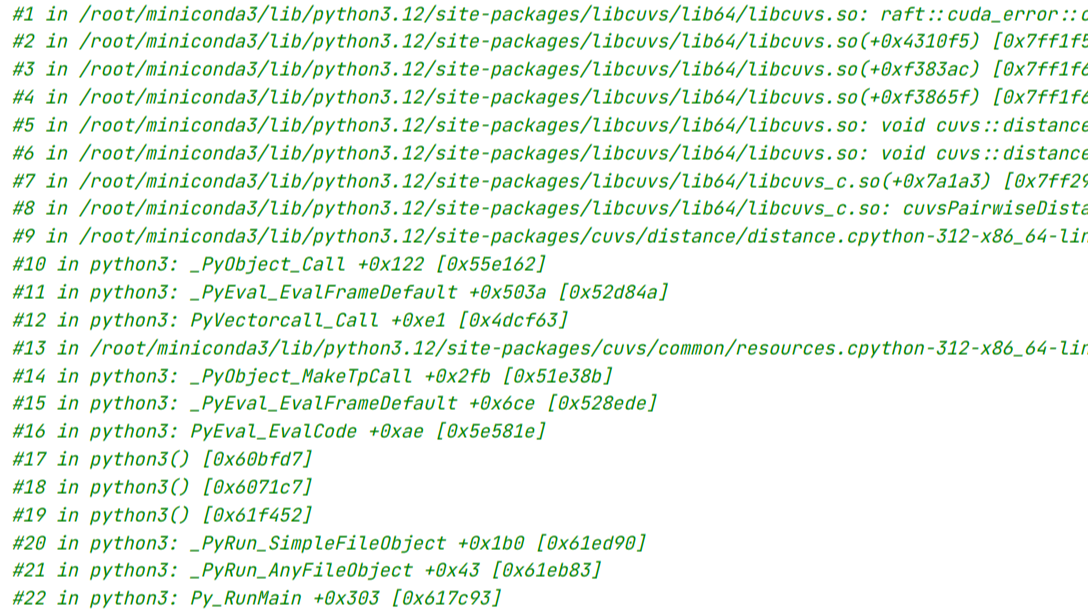 本文记录了一些使用python-cupy的过程中有可能的遇到的一些问题,一部分是环境配置问题,还有一部分是运行输入问题。
本文记录了一些使用python-cupy的过程中有可能的遇到的一些问题,一部分是环境配置问题,还有一部分是运行输入问题。 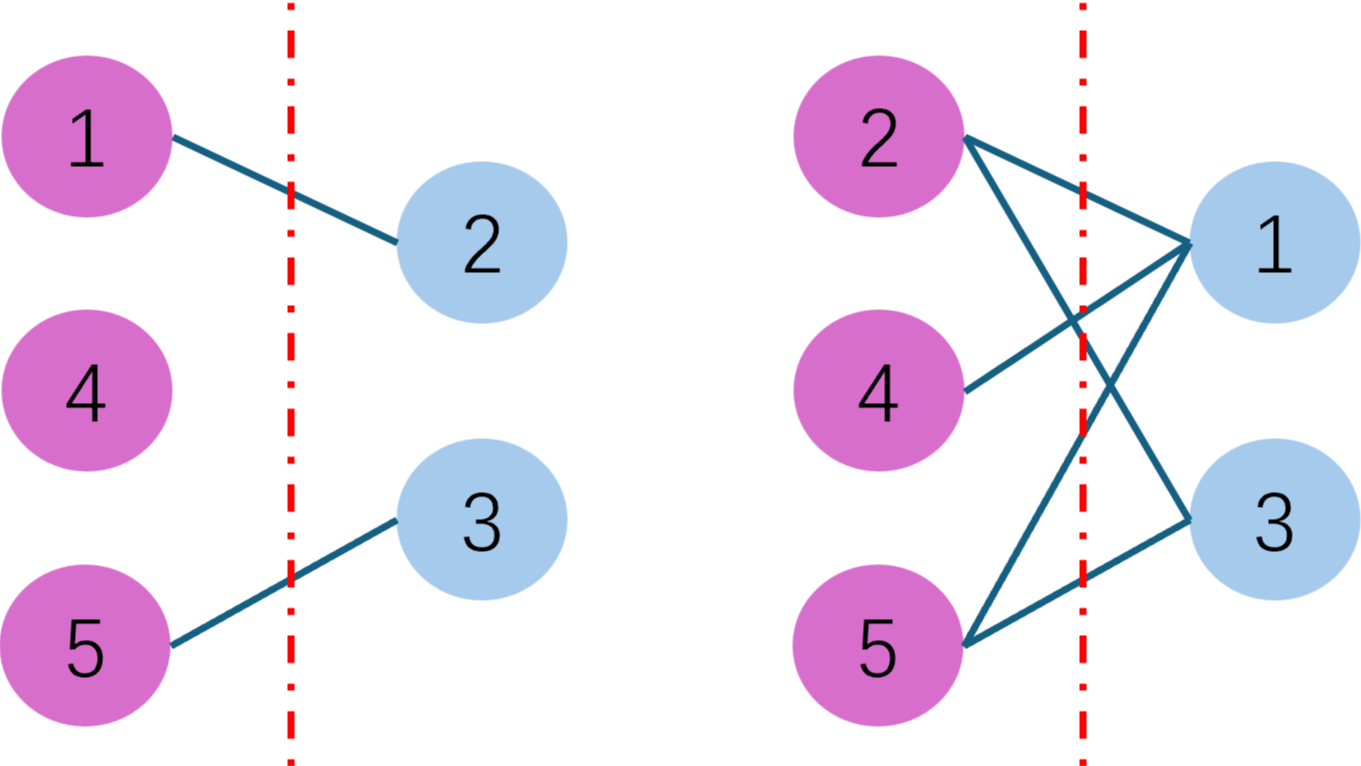 这篇文章算是对Fred Glover的一篇综述的解读,添加了一些方便直观理解的示例具体的建模过程。对于不同的场景,可以使用不同的惩罚项进行QUBO建模,从而可以使用求解器或者Ising机进行求解。
这篇文章算是对Fred Glover的一篇综述的解读,添加了一些方便直观理解的示例具体的建模过程。对于不同的场景,可以使用不同的惩罚项进行QUBO建模,从而可以使用求解器或者Ising机进行求解。  本文介绍了国产的大模型推理工具KTransformers在本地成功运行的一个案例,在容器化部署的基础上,结合Open WebUI做了一个用户友好的大模型服务。
本文介绍了国产的大模型推理工具KTransformers在本地成功运行的一个案例,在容器化部署的基础上,结合Open WebUI做了一个用户友好的大模型服务。  本文介绍了一种使用Slack聊天工具中的机器人SlackBot的API接口,实现本地化部署Ollama的DeepSeek大模型的远程通讯方案。相比于调用公网的API接口,数据隐私稍微好一点点。最终的方案应该是自建加密聊天工具+Ollama本地化部署,但是这个时间成本有点高,用户可以自行尝试。
本文介绍了一种使用Slack聊天工具中的机器人SlackBot的API接口,实现本地化部署Ollama的DeepSeek大模型的远程通讯方案。相比于调用公网的API接口,数据隐私稍微好一点点。最终的方案应该是自建加密聊天工具+Ollama本地化部署,但是这个时间成本有点高,用户可以自行尝试。  本文介绍了使用CUDA和Cython来实现一个CUDA加法算子的方法,并介绍了使用CUDA参数来估算性能极限的算法。经过实际测试,核函数部分的算法性能优化空间已经不是很大了,更多时候可以考虑使用Stream来优化Host和Device之间的数据传输。
本文介绍了使用CUDA和Cython来实现一个CUDA加法算子的方法,并介绍了使用CUDA参数来估算性能极限的算法。经过实际测试,核函数部分的算法性能优化空间已经不是很大了,更多时候可以考虑使用Stream来优化Host和Device之间的数据传输。  以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。
以学习CUDA为目的,接上一篇关于Cython与CUDA架构下的Gather算子实现,这里我们加一个Batch的维度,做一个BatchGather的简单实现。  浙公网安备 33010602011771号
浙公网安备 33010602011771号