摘要:  在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。 阅读全文
在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。 阅读全文
在往期关于DeepSeek的模型部署、KTransformer的安装与使用、PageAssist和OpenClaw的相关应用部署的基础之上,本文我们再讲述一个新版的KTransformer部署最新的BF16精度的Qwen3-Coder-Next模型的一些技术方案和操作指引。 阅读全文
posted @ 2026-06-25 15:01
DECHIN
阅读(226)
评论(0)
推荐(1)
 接上一篇关于Docker中的Ollama养虾的文章之后,这里补充一个Docker中部署Ollama模型的方案,通过这种方式建立一个完整的虚拟化环境,确保Ollama和OpenClaw在环境内的操作都相对可控。
接上一篇关于Docker中的Ollama养虾的文章之后,这里补充一个Docker中部署Ollama模型的方案,通过这种方式建立一个完整的虚拟化环境,确保Ollama和OpenClaw在环境内的操作都相对可控。  本文介绍了一种在Win11操作系统下,使用Docker部署OpenClaw的一种方案,并且Token由本地部署的Ollama加载开源的qwen3.5模型产生,实现零成本、相对安全可控的一种部署方案。当然,目前OpenClaw和Ollama的安全性还是有待提升,结合自己的情况,慎重部署!!!
本文介绍了一种在Win11操作系统下,使用Docker部署OpenClaw的一种方案,并且Token由本地部署的Ollama加载开源的qwen3.5模型产生,实现零成本、相对安全可控的一种部署方案。当然,目前OpenClaw和Ollama的安全性还是有待提升,结合自己的情况,慎重部署!!! 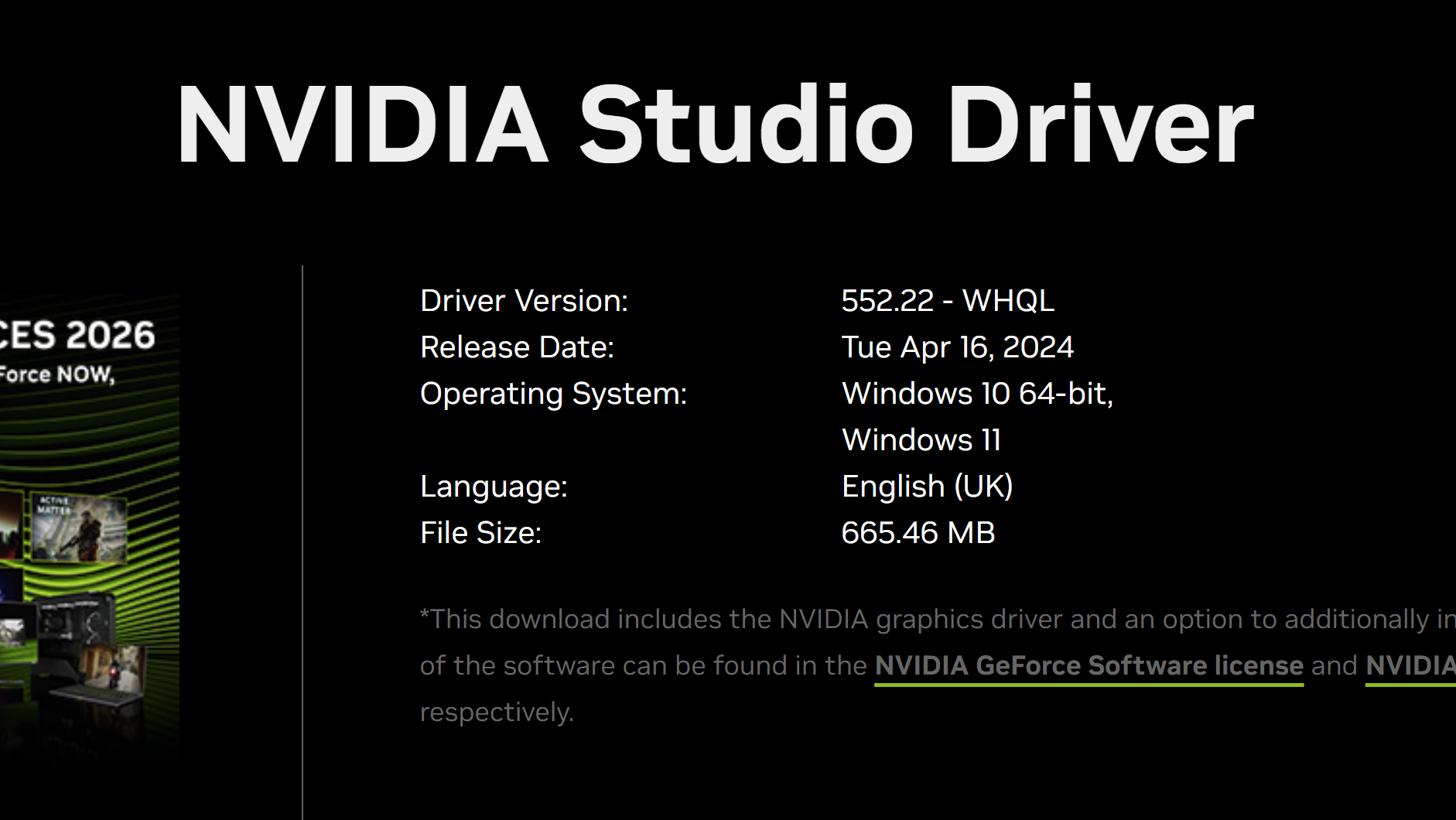 本文介绍了一个可能在Win11的自动更新之后出现的严重问题:由于显卡驱动被更新了,原本安装在WSL2和Docker中的GPU环境因为版本不适配的问题,会无法识别GPU(虽然在Nvidia-Smi中可以看到,也可以用nvcc编译,但正常使用会报错)。通过手动降驱动版本,可以解决该问题。
本文介绍了一个可能在Win11的自动更新之后出现的严重问题:由于显卡驱动被更新了,原本安装在WSL2和Docker中的GPU环境因为版本不适配的问题,会无法识别GPU(虽然在Nvidia-Smi中可以看到,也可以用nvcc编译,但正常使用会报错)。通过手动降驱动版本,可以解决该问题。 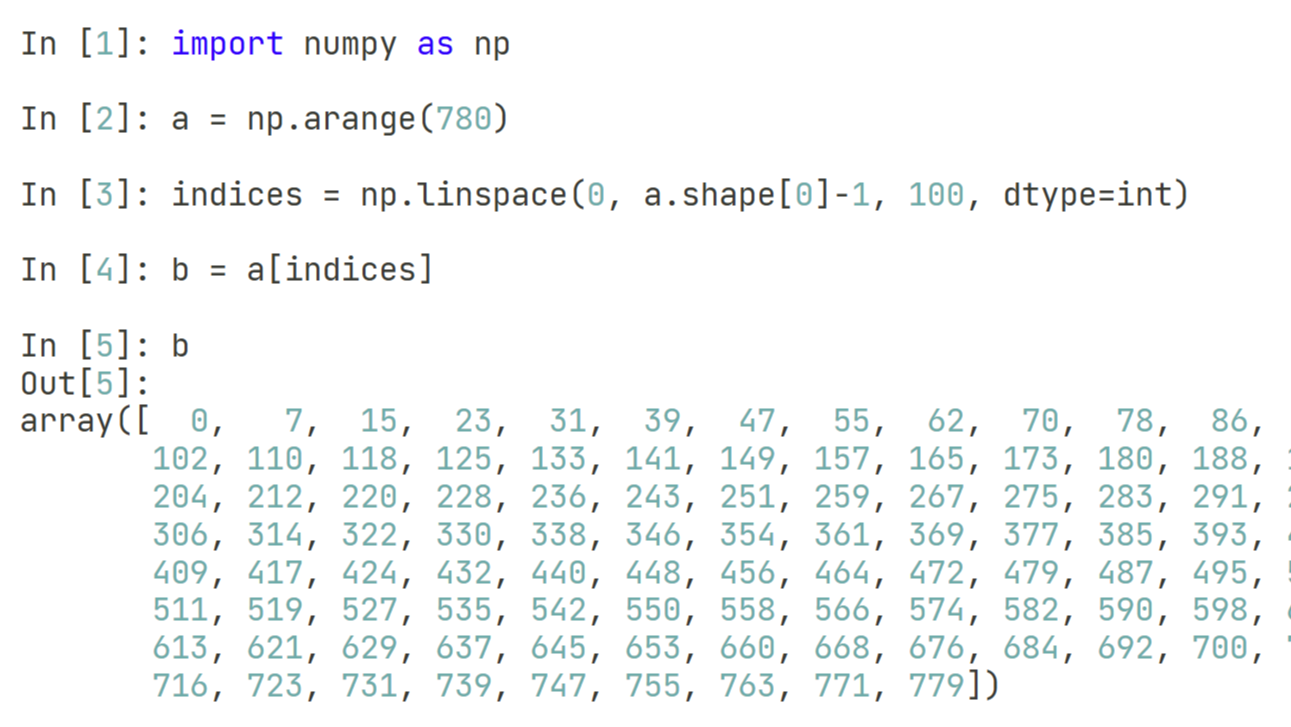 本文通过具体代码实现,介绍了一种在Python中,使用numpy对原始数据进行固定长度的等间距抽样方法。
本文通过具体代码实现,介绍了一种在Python中,使用numpy对原始数据进行固定长度的等间距抽样方法。 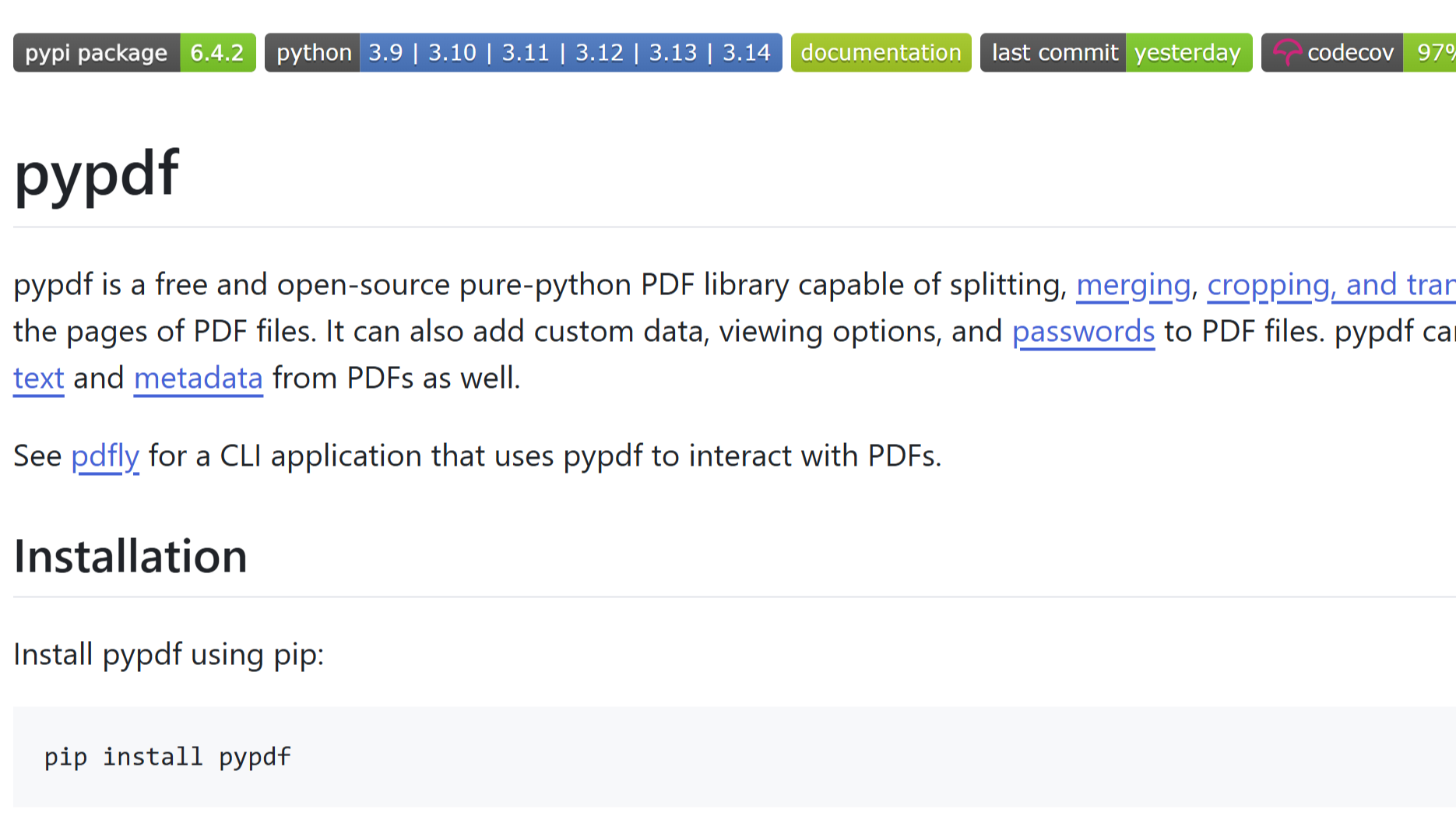 本文介绍了一个使用python进行免费pdf文档合并的实现方案。使用该方案,还可以针对同一个路径下的多个文件进行合并操作,还可以利用Python的正则表达式对文件名进行筛选。综合来说,该工具对于熟练使用Python的人来说,是一大办公福音。
本文介绍了一个使用python进行免费pdf文档合并的实现方案。使用该方案,还可以针对同一个路径下的多个文件进行合并操作,还可以利用Python的正则表达式对文件名进行筛选。综合来说,该工具对于熟练使用Python的人来说,是一大办公福音。 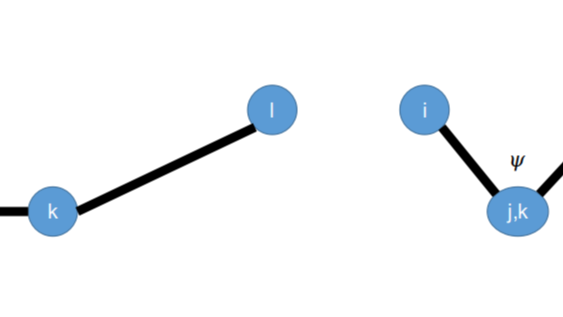 接前面一篇关于键长和键角的相互作用力计算的文章,本文简单的计算了一下传统分子力场项中常见的二面角项的相互作用力。
接前面一篇关于键长和键角的相互作用力计算的文章,本文简单的计算了一下传统分子力场项中常见的二面角项的相互作用力。 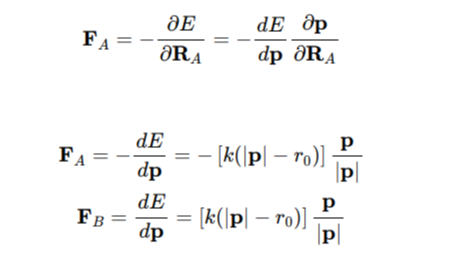 本文通过一个简单的微分计算,说明了为什么弹簧对两头的作用力方向总是沿着弹簧方向的。虽然是一个固有的认知,但其实也可以通过简单的计算来进行论证。
本文通过一个简单的微分计算,说明了为什么弹簧对两头的作用力方向总是沿着弹簧方向的。虽然是一个固有的认知,但其实也可以通过简单的计算来进行论证。  本文介绍了一种使用conda来安装gcc和g++编译工具的方法,可以不需要root权限,也能够在本地自己的路径下配置相应的编译器版本。
本文介绍了一种使用conda来安装gcc和g++编译工具的方法,可以不需要root权限,也能够在本地自己的路径下配置相应的编译器版本。  本文介绍了一个Ubuntu操作系统下如何挂载新硬盘,并配置重启开机默认挂载的流程和方法。
本文介绍了一个Ubuntu操作系统下如何挂载新硬盘,并配置重启开机默认挂载的流程和方法。  本文介绍了一个可以基于CPU和numpy的自动微分计算框架。如果只是需要使用自动微分计算的功能,就可以直接在CPU环境下简便的部署,快捷的完成环境搭建。
本文介绍了一个可以基于CPU和numpy的自动微分计算框架。如果只是需要使用自动微分计算的功能,就可以直接在CPU环境下简便的部署,快捷的完成环境搭建。  本文重点介绍了一下如何在PyTorch中去计算一个高维tensor的大小,也就是元素的总数。在其他框架中我们需要使用size函数来获取,而在PyTorch框架中这个接口被调整为numel,本文给出了两个具体代码示例。
本文重点介绍了一下如何在PyTorch中去计算一个高维tensor的大小,也就是元素的总数。在其他框架中我们需要使用size函数来获取,而在PyTorch框架中这个接口被调整为numel,本文给出了两个具体代码示例。  本文介绍了一个可以用于并行化串行累计操作的Blelloch算法,可以通过用空间换时间+并行计算的方法,来降低特定计算的时间复杂度。这里我们给出了算法原理的大致介绍,以及基于Numpy的算法代码实现。
本文介绍了一个可以用于并行化串行累计操作的Blelloch算法,可以通过用空间换时间+并行计算的方法,来降低特定计算的时间复杂度。这里我们给出了算法原理的大致介绍,以及基于Numpy的算法代码实现。  Ollama在本地普通算力机器上部署DeepSeek等大模型,有一定的生态优势。但是由于软件本身的一些策略问题,Windows平台的Ollama总是会随系统开机自动启动,还没有设置界面可以关闭。这里提供一种方法,可以在Windows平台永久关闭Ollama的开机自动启动功能。
Ollama在本地普通算力机器上部署DeepSeek等大模型,有一定的生态优势。但是由于软件本身的一些策略问题,Windows平台的Ollama总是会随系统开机自动启动,还没有设置界面可以关闭。这里提供一种方法,可以在Windows平台永久关闭Ollama的开机自动启动功能。  本文简单的介绍了如何禁用VSCode的版本自动更新,以及禁用更新后如何手动更新,或者切换VSCode的版本。
本文简单的介绍了如何禁用VSCode的版本自动更新,以及禁用更新后如何手动更新,或者切换VSCode的版本。  浙公网安备 33010602011771号
浙公网安备 33010602011771号