Asp-Net-Core学习笔记:WebApi开发实践
前言#
用AspNetCore做Api开发也有一段时间了,正好年底在做总结,做一个WebApi开发实践笔记。
暂时想到的一些技术关键词,同时也作为本文的大纲,现在对这套技术体系的了解还不够深入,以后会持续更新这个Api开发实践~
-
身份认证:JwtBearer
-
分页:X.PagedList
-
缓存
- ResponseCache
- Redis:StackExchange.Redis
-
数据持久化 / ORM
- FreeSQL
- Dapper
- EF Core
- MongoDB
-
接口文档(OpenApi)
- Swagger:Swashbuckle.AspNetCore
- IGeekFan.AspNetCore.Knife4jUI
- IGeekFan.AspNetCore.RapiDoc
-
序列化
- NewtonsoftJson
- System.Text.Json
-
爬虫
- HttpClient(System.Net.Http)
- System.Net.Http.Json
- AngleSharp
-
日志&监控
- NLog
- ExceptionLess
- Sentry
-
实时通信:SignalR
-
对象映射:AutoMapper
-
定时任务 / 异步任务队列:Hangfire
CRUD#
Web开发的本质就是……
RESTFul#
WebApi开发,我所知常用的无非HTTP和RPC调用两种方式,然后目前我们团队HTTP用得是比较多的,为了接口设计优雅和易用,RESTFul是必须的~
REST,全称为REpresentational State Transfer,即表述性状态传递,它是一种应用程序的架构风格,用于构造简单、可靠、高性能的Web应用程序。REST提出了一系列约束,遵循这些约束的应用程序称为RESTful API应用。
REST是一种基于资源的架构风格,在REST中,资源(Resource)是最基本的概念。任何能够命名的对象都是一个资源,如document、user、order等,通常情况下,它表示Web服务中要操作的一个实体。一个资源具有一个统一的资源标识符(Uniform Resource Identifier,URI),如
users/1234,通过资源标识符能够标识并访问该资源。除了单个的资源外,资源集合表示多个相同类型的资源,如users。在系统设计时,不同的实体之间往往存在某种关联关系,如一个用户有多个订单。同样,在REST中,这种关联关系也能够由资源之间的层次关系体现出来,如
users/1234/orders/1。由于REST以资源为中心,因此REST接口的端点(Endpoint)均以资源或资源集合结尾,它不像其他形式的Web服务一样以动词结尾,如api/GetUserInfo或api/UpdateUserInfo。在REST中,对资源的动作或操作是通过HTTP方法(GET / POST / PUT / DELETE / PATCH / HEAD / OPTION)来完成的。
贴了一段概念的引用,要设计出好的接口,真的有必要掌握REST的思想,只有按照规范来,才能延缓产生屎山代码的速度,增加项目可维护性hhh
具体就不说了,免得又当复读机…
分页#
分页很重要,不然数据太长没法传输。
其实很多ORM都有分页功能,自己实现一个也不难,不过有现成的库使用还是偷懒舒服。
而且我用的这个X.PagedList,还可以在MVC里使用,只需要@Html.PagedListPager一行代码就可以实现自动生成HTML分页器。(由于本文是说WebApi实践所以就不展开了)
放在WebApi里使用,分页参数是放在response headers里面,加了个名为X-Pagination的参数,大概长这样:
x-pagination: {"PageCount":22,"TotalItemCount":218,"PageNumber":1,"PageSize":10,"HasPreviousPage":false,"HasNextPage":true,"IsFirstPage":true,"IsLastPage":false,"FirstItemOnPage":1,"LastItemOnPage":10}
然后一个简单的,不带过滤、搜索、排序等功能的controller获取列表方法是这样:
[HttpGet]
public ActionResult<IPagedList<Tag>> GetList(int page = 1, int pageSize = 10) {
var paged = _tagRepo.GetAll().ToPagedList(page, pageSize);
Response.Headers.AddXPagination(paged);
return Ok(paged);
}
根据上面的REST规范,这个接口的地址是/api/tags/,使用GET方法请求所有tag对象。
代码里的_tagRepo.GetAll()返回的是一个List (数据量大的时候要用数据库的分页!),然后使用X.PagedList提供的扩展方法进行分页,然后下一行Response.Headers.AddXPagination(paged)是我写的对IHeaderDictionary的扩展方法,很简单就是把分页信息序列化成json之后添加到headers里面,定义如下:
public static void AddXPagination(this IHeaderDictionary headers, IPagedList page) {
headers.Add("X-Pagination", page.ToPaginationMetadataJson());
}
为了实现这个,又写了个IPagedList的扩展方法,哦不,是两个
public static PaginationMetadata ToPaginationMetadata(this IPagedList page) {
return new PaginationMetadata {
PageCount = page.PageCount,
TotalItemCount = page.TotalItemCount,
// ...省略
};
}
public static string ToPaginationMetadataJson(this IPagedList page) {
return JsonSerializer.Serialize(ToPaginationMetadata(page));
}
所以这里就完成了一个简单的分页实现,当然复杂功能还是自己实现比较好,第三方的库用着方便但要自定义还是得造轮子~
这里再补充一个注意点,数据量大的时候,不能先把所有数据取出再分页,应该把分页这一步放在数据库执行,这时候需要使用 X.PagedList 的手动分页功能。
[HttpGet]
public ActionResult<IPagedList<Tag>> GetList(int page = 1, int pageSize = 10) {
// 这里假设 数据库/ORM 提供了 Page 这个分页方法
var data = _tagRepo.Page(page, pageSize);
var total = _tagRepo.Count();
var paged = new StaticPagedList<Tag>(data, page, pageSize, total);
Response.Headers.AddXPagination(paged);
return Ok(paged);
}
改动不多,在数据量大的时候可以获得很大的性能提升。
关于 X.PagedList 的更多用法,可以参考官方文档: https://github.com/dncuug/X.PagedList/wiki/Use-in-ASP.NET-Core
杂项#
- C#匿名对象在创建Json或者请求接口的时候很好用,现在.Net6有了新的可写JSON DOM API也很方便
- Convert Json to C# Classes Online:https://json2csharp.com/
- 在程序里请求其他接口可以用.NetCore自带的HttpClient,挺好用的
参考资料#
- 理解C# 4 dynamic(1) - var, object, dynamic的区别以及dynamic的使用:https://www.cnblogs.com/justrun1983/p/3163350.html
- 官方文档 .NET 6 中的新增功能:https://docs.microsoft.com/zh-cn/dotnet/core/whats-new/dotnet-6#systemtextjson-apis
- 官方文档 控制序列化行为:https://docs.microsoft.com/zh-cn/dotnet/standard/serialization/
- 在ASP.NET Core中用HttpClient(二)——发送POST, PUT和DELETE请求:https://www.cnblogs.com/hhhnicvscs/p/14515922.html
缓存#
使用缓存的场景很多~ 我主要把缓存分成两种,客户端缓存和服务端缓存。一个用来减轻服务器负担,一个减轻数据库负担。
客户端缓存#
客户端缓存也就是基于HTTP的相应缓存,不会在服务器上对响应进行缓存,需要客户端实现*(像浏览器默认就是支持的),服务端返回资源时,在响应消息中包含HTTP缓存消息头,这些消息头为客户端指明了缓存行为(如是否使用缓存、缓存有效时间等),主要包括Cache-Control和Expires。如果要用缓存,那第一次请求完客户端就把结果保存下来,下次相同请求且缓存未过期的情况下客户端就把缓存拿出来用,不给服务器添堵~
在AspNetCore里主要是用相应缓存中间件来实现(具体不展开了,很基础的东西)
服务端缓存#
就是把缓存放在服务端啦,一般用来减少数据库压力,或者临时存一些东西,因为REST的设计是无状态的嘛,比如短信验证码之类的~
我用过的有下面这两种:
- AspNetCore自带的内存缓存
MemoryCache - Redis,用的
StackExchange.Redis这个库
内存缓存#
自带的内存缓存很方便,它和Redis一样是键值对的存储形式,不用额外安装什么库,首先注册服务services.AddMemroyCache(),然后在要使用的地方依赖注入就OK了~
// C# 伪代码
IMemoryCache _memoryCache;
ctor(IMemoryCache memoryCache) {
_memoryCache = memoryCache;
}
使用起来也是简单的Get和Set,可以设置缓存有效时间,例如验证码要在五分钟内有效,可以设置
_memoryCache.Set<string>(phone, codeStr, new MemoryCacheEntryOptions {
// 验证码 5分钟过期
AbsoluteExpiration = DateTime.Now.AddMinutes(5)
});
Redis#
典型的非关系型数据库,采用key - value形式存储数据,性能又高,简直缓存的不二之选啊!而且还能持久化,作为主流技术也能找到很多资料可以深入折腾~
在.NetCore中使用Redis很简单,用StackExchange.Redis这个库就行,网上一搜应该很多例子,不过我打算接下来写一篇博客来介绍并附上例子代码~
我用来缓存一些数据库请求结果,因为我们有些项目是基于旧项目继续开发的(简称屎山上拉屎),而旧项目基本就是DBA在Oracle数据库里写业务逻辑,暴露函数或视图来调用,所以我要在AspNetCore项目里面用SQL把需要的数据请求出来。
这个简单的缓存我就自己来实现了,把SQL语句用base64编码,作为缓存的key,然后数据库返回的结果用json序列化,作为value存进去,就OK了~
可能有同学想问为啥SQL语句不用md5编码成统一长度的key,原因在于我觉得md5可能会重复(虽然概率很小),那样读取缓存可能会出现两个不同的SQL语句拿到同样结果的情况…
同时我这种方法没考虑到高并发的问题,别问,问就是没场景,哈哈哈
Redis工具
如果是在本地装了Redis,可以安装一些可视化的Redis管理工具,能更直观的看到Redis里面的数据,方便调试。
下面推荐几个工具
- redis-desktop-manager:比较轻量快速,不过最新版本好像收费了,我下载的2020版本还能用,嘿嘿
- another redis desktop manager:顾名思义另一个Redis客户端,这个是使用electron开发的,界面比较美观,开源免费,值得推荐!
数据持久化 / ORM#
终于到这部分了
为什么需要数据持久化就不多比比了,ORM是bject relational mapping的缩写,中文意思是对象关系映射……还是复制一段ORM概念吧
ORM能够处理数据库与高级编程语言中对象之间的映射关系,从而无须开发人员直接书写SQL语句,使用ORM能够明显地提高应用程序的开发效率。
目前我在项目中用到的工具有这四个:
- FreeSQL
- Dapper
- EF Core
- MongoDB
(MongoDB虽然不是ORM,但这种非关系型数据库操作简单,好像并不需要ORM的支持… 所以也把它放进来了)
下面一个个简单介绍一下
FreeSQL#
这个是国产ORM,我发现.Net社区造轮子的挺多的,国产的各种框架工具都很多用不过来,这个FreeSQL是某天我刷博客时看到作者自己发的广告,然后刚好遇到一个项目需求,那个时候还不太熟悉EF Core,抱着“那就拿来试试吧”的心态,开始使用这个ORM。
这个ORM有个我很喜欢的特点:轻量,不限于在AspNetCore框架里使用,随便什么项目都可以用,最基本的用法安装FreeSQL的Nuget包和一个数据库驱动即可,简单的一行代码连接数据库,然后就能直接操作了。同时也能支持DB Frist和Code First。
一般用于新项目,这种情况下,技术选型就EFCore、FreeSQL都可以,前者是微软官方的ORM,网上文档比较多,新手接触能选EFCore就EFCore,国产ORM很多文档不太完善,并且出了问题不好找到资料。
Dapper#
这个很牛,被称为“the king of ORM”,这个ORM的最大特点就是性能强悍,长期霸占各种ORM性能评测的排行榜,猛得一批!
不过这个Dapper一般用来执行SQL语句,它本身的“ORM”功能一般般,只提供了查询结果映射为对象,没有Insert,想要实现Insert映射需要用扩展,所以我一般用它来执行一些纯粹的数据库交互,详情请看下面的团队场景。
团队场景#
我一般用得比较多的是FreeSQL和Dapper,EFCore用得倒不多,因为我们团队有专门的DBA(很多人),以前的业务全都是写在Oracle数据库里面,用函数、存储过程、触发器之类的东西,可以实现一切想要的功能,就恨不能直接用SQL写接口了……
(PS:据说有插件能实现PLSQL导出Web接口的,不敢试哈哈哈哈,数据安全不敢乱开玩笑)
各种各样的历史原因,一批又一批的人,不断增长的业务,在Oracle里面加上一坨又一坨的SQL代码,最终成为了不可撼动的“屎山”
基于这种背景,我和另外的几个开发小伙伴作为新技术的代表,自然不可能继续用Oracle + ASP这套技术了,维护性真的不强。
于是团队初期我们就敲定了技术框架,需要用到Oracle的(直接跟Oracle打交道的)项目,使用.Net Core技术栈;不需要直接打交道的(例如小程序、公众号),用Django技术栈。
提问:为啥用到Oracle不用Java呢?毕竟同一家的东西。
答:我不喜欢Java
(逃
DB First#
工作中这种用得比较多,似乎国内大环境(上古业务屎山代码写在数据库里)也是这种模式多 (所以Mybatis那么流行就是因为这样?)
这种情况用FreeSQL的DB First工具,根据数据库表生成实体类就很方便了。
我用的命令如下:
FreeSql.Generator -Razor 1 -NameOptions 1,0,0,0 -NameSpace "ProjectName.Data.OracleModels" -Filter View+StoreProcedure -DB "Oracle,DATA SOURCE=host/name; USER ID=user_id; PASSWORD=password; PERSIST SECURITY INFO=True"
应该有其他工具来做这种事,不过我没去深究,有得用就行了~
生成实体类之后用FreeSQL来查询、插入都可以,或者简单点的项目不想安装FreeSQL也可以直接用Dapper,性能更高~(比如我们的数据中台,就直接用Dapper)
目前查询用FreeSQL和Dapper对半开吧,因为有一部分项目是业务逻辑全都由DBA写在Oracle里面,很多查询只是提供一个函数给我调用的,这种情况我直接Dapper就搞定了,然后有涉及到增删改查的用FreeSQL就更方便一点~
Code First#
先定义实体类,再创建数据库表。
一般用于新项目,这种情况下,技术选型就EFCore、FreeSQL都可以,前者是微软官方的ORM,网上能找到的文档教程比较多,新手接触能选EFCore就EFCore,国产ORM很多文档不太完善,并且除了问题不好找到资料。
我之前为啥选FreeSQL,主要是两点:
- 轻量级
- 对多表操作的支持(我只用到一对多、多对多这类的关联)
- 自动同步表结构
之前2.0时代的EFCore好像对多表的支持一般般,而FreeSQL明显操作起来更方便,有点之前用Django的那意思了,所以我挺喜欢这个FreeSQL的~
不过现在EFCore也进步了很多了,微软官方支持,不会差的。
自动同步表结构这点,我之前用过的EFCore和DjangoORM都没有,这俩都是要设计好实体类之后执行数据库迁移操作,才会将修改反映到数据库里,在调试模式里,开启FreeSQL的自动同步表结构,不用迁移太方便了,改了什么,操作表的时候立即就同步修改~
仓储模式#
一般看各种教程,都会有教你把数据访问的代码抽出来,抽象成一个数据层,AspNetCore的开发一般就是EFCore的dbcontext或者是DDD的仓储模式两种风格,我比较喜欢更直观的仓储模式。
我一般是自己写一套:最顶层是一个IRepository接口,然后扩展IAppRepository接口,再写一个实现类BaseSqlRepo,其他有需要的就在这个实现类下做扩展。
接口IRepository的定义:
public interface IRepository<TEntity, TPrimaryKey> where TEntity : class {
TEntity GetById(TPrimaryKey id);
TEntity Get(Expression<Func<TEntity, bool>> expression);
IEnumerable<TEntity> GetAll();
TEntity Insert(TEntity obj);
int Update(TEntity obj);
int Delete(TPrimaryKey id);
}
接口IAppRepository,就是指定了实体的主键类型的子接口,考虑到不一定所有实体的主键都是一个类型,所以把这两个接口分开来写
public interface IAppRepository<TEntity> : IRepository<TEntity, string> where TEntity : class {
}
然后实现一下这个接口,作为基类,如果没有特别的要求,就可以直接把这个实现类拿来使用了。
以我最近正在做的开源项目CrawlCenterNet为例,目前有的几个仓储,注册服务
services.AddScoped<IAppRepository<CrawlTask>, CrawlTaskRepo>();
services.AddScoped<IAppRepository<Project>, ProjectRepo>();
services.AddScoped<IAppRepository<ProjectTag>, BaseSqlRepo<ProjectTag>>();
services.AddScoped<IAppRepository<RecurringTask>, RecurringTaskRepo>();
services.AddScoped<IAppRepository<User>, UserRepo>();
其中ProjectTag实体类的仓储就是用这个实现基类,其他的都是继承BaseSqlRepo重新实现了,因为需要处理关系字段。
不过如果只是简单的增删改查,自己定义一套确实比较折腾,没必要,FreeSQL自带了通用的仓储层的功能,按照官方的话
FreeSql.Repository 参考 abp vnext 接口,定义和实现基础的仓储层(CURD),应该算比较通用的方法吧。
我在之前的项目里面也用过,确实方便,也比我们自己定义的仓储层更灵活,代码量还少
使用services.AddFreeRepository();注入之后,使用IBaseRepository<T>类型注入即可使用,感觉比自己封装一套仓储层方便很多,当然这样做就会把项目跟FreeSQL建立强依赖,以后想要换ORM就很麻烦了。
自己实现一套仓储的意义更多是在抽象,降低对ORM的耦合依赖,不过小项目感觉没有什么必要吧~ 不要为了抽象而抽象~
MongoDB#
这个不是ORM,但也是常用的数据持久化手段/工具,MongoDB是文档型的非关系型数据库,大家都很熟悉的非关系型数据库啦,关系型数据库里存的是表,它存的是json对象,我一般用MongoDB来存爬虫采集下来的数据,还有我做了一个爬虫平台,其中的配置中心就用MongoDB来存配置数据。
虽然它不是ORM,但操作跟ORM一样方便~
另外提一点,在C#里MongoDB可以用lambda来查询,很方便:
// 通过 name 属性查询
collection.Find(a => a.Name == "name").FirstOrDefault();
// 通过 Id 查询
collection.Find(a => a.Id == 123).FirstOrDefault();
就跟普通的ORM一样用,方便~
AspNetCore中使用MongoDB需要安装这个nuget包:MongoDB.Driver
在CrawlCenterNet项目中,我没有用依赖注入的方式来使用MongoDB,直接在仓储实现类里创建MongoDB对象:
Client = new MongoClient(MongodbSettings.ConnectionString);
Database = Client.GetDatabase(MongodbSettings.DatabaseName);
Collection = Database.GetCollection<ConfigSection>(MongodbSettings.ConfigCollectionName);
不过这个MongodbSettings就是注入的配置对象,配置信息存在appsettings.json里(关于这个配置映射,可以参考官方文档:https://docs.microsoft.com/zh-cn/aspnet/core/fundamentals/configuration/?view=aspnetcore-6.0)
有了IMongoCollection<T>对象之后,就可以像ORM那种对MongoDB的数据做增删改查了~
例子:
// 查
Collection.Find(a => a.Id == id).FirstOrDefault();
// 增
Collection.InsertOne(obj);
// 改
Collection.ReplaceOne(item => item.Id == obj.Id, obj);
// 删
Collection.DeleteOne(a => a.Id == id);
使用简单,令人极度舒适!
参考资料#
总结一下这部分的参考资料
- 轻量级ORM框架 第一篇 Dapper快速学习:https://www.cnblogs.com/huangxincheng/p/5828470.html
- FreeSQL官方文档:http://freesql.net/
- FreeSql、AutoMapper处理多对多查询映射:https://blog.csdn.net/XinShun/article/details/104755959
- EFCore官方文档:https://docs.microsoft.com/zh-cn/ef/
接口文档(OpenApi)#
好像OpenApi + Swagger已经成为事实上的接口文档标准,后端写完接口直接生成可交互的接口文档还是非常方便的。
我主要用这几个组件:
Swagger:Swashbuckle.AspNetCoreIGeekFan.AspNetCore.Knife4jUI(注意最新版有bug不能修改RoutePrefix路径,需要用0.0.8版本)IGeekFan.AspNetCore.RapiDoc
上面第一个就是swagger在AspNetCore里的实现啦,功能很全(我还没一一探索完),一般用第一个就够了。
然后下面两个是社区大佬封装的swagger套壳皮肤,Knife4j这个组件写Springboot的同学应该会比较熟悉,这是xiaoymin老哥搞的swagger皮肤,左右两栏布局比原版swagger结构更清晰,如果接口比较多的话,原版swagger页面会变得很长很长,knife4j的两栏布局用起来就更方便~
还有knife4j里面可以配置全局请求头之类的,有点像postman,有些接口需要登录授权的得带上token,这个功能就很好用了。按理说原版swagger也可以支持登录授权,不过得配置,没有knife4j香,hhh
不过knife4j也有一个缺点,如果接口返回的内容太长的话,就不会显示,有时候调试的时候还以为是接口出问题了~ 你截掉一部分也行啊,为啥干脆就不显示了呢…
第三个RapiDoc也不错,界面和功能类似knife4j,更轻量,界面感觉更好看一点。
反正都可以试试,在项目中添加这几个文档组件很简单,nuget安装完直接几行代码配置一下即可。
首先安装nuget包:Swashbuckle.AspNetCore
然后添加服务:
services.AddSwaggerGen(options => {
options.SwaggerDoc("v1", new OpenApiInfo { Title = "CrawlCenter.Web API V1", Version = "v1" });
options.AddServer(new OpenApiServer {
Url = "",
Description = "vvv"
});
options.CustomOperationIds(apiDesc => {
var controllerAction = apiDesc.ActionDescriptor as ControllerActionDescriptor;
return $"{controllerAction?.ControllerName}-{controllerAction?.ActionName}";
});
var xmlPath = Path.Combine(System.AppContext.BaseDirectory, $"{typeof(Startup).Assembly.GetName().Name}.xml");
options.IncludeXmlComments(xmlPath, true);
});
配置一下中间件,三个组件全都用上
app.UseSwagger();
app.UseSwaggerUI(options => {
options.RoutePrefix = "api-doc/swagger";
options.SwaggerEndpoint("/swagger/v1/swagger.json", "V1 Docs");
});
app.UseRapiDocUI(options => {
options.RoutePrefix = "api-doc/rapi";
options.SwaggerEndpoint("/swagger/v1/swagger.json", "V1 Docs");
options.GenericRapiConfig = new GenericRapiConfig {
Theme = "light",
RenderStyle = "focused"
};
});
app.UseKnife4UI(options => {
options.RoutePrefix = "api-doc/knife";
options.SwaggerEndpoint("/swagger/v1/swagger.json", "V1 Docs");
});
显而易见,只要访问http://localhost:5000/docs/swagger就可以看到接口文档了(具体接口得看launchSettings.json的配置)
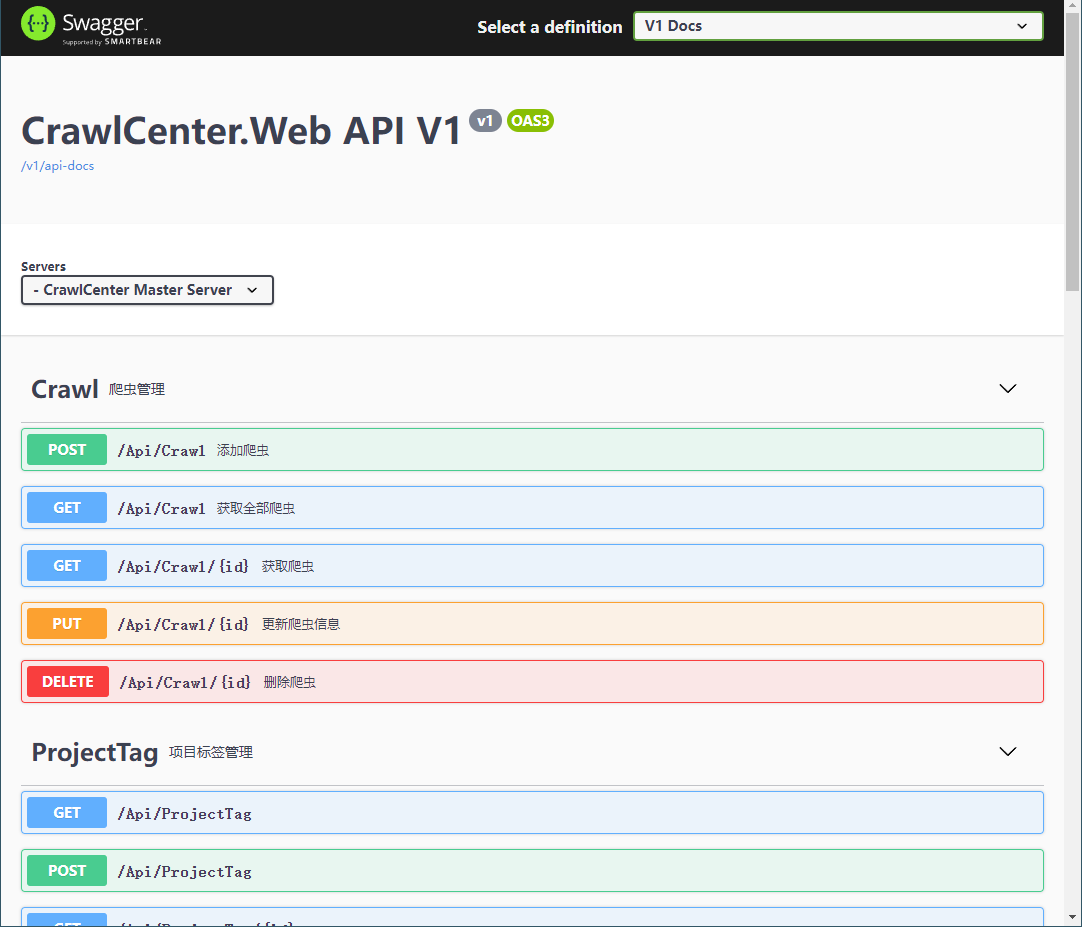
其他第三方Swagger UI#
swagger默认的UI说实话一般般,也不是说丑,就是从上到下的布局在接口很多的时候效率不高
这时候可以试试第三方的swagger ui,我只试用过这几个
- Knife4jUI:原本是spring社区的大佬搞的,luoyunchong大佬封装了一个AspNetCore版本
- RapiDoc:也是luoyunchong大佬封装的
- Redoc:Swashbuckle.AspNetCore自带
我在CrawlCenterNet项目中把这几个都配置上去了,小孩子才做选择,我全都要!
app.UseKnife4UI(c => {
c.RoutePrefix = "docs/knife4j";
c.SwaggerEndpoint("/v1/api-docs", "V1 Docs");
});
app.UseRapiDocUI(c => {
c.RoutePrefix = "docs/rapi";
c.SwaggerEndpoint("/v1/api-docs", "V1 Docs");
c.GenericRapiConfig = new GenericRapiConfig {
Theme = "light",
});
app.UseReDoc(c => {
c.RoutePrefix = "docs/redoc";
c.SpecUrl = "/v1/api-docs";
});
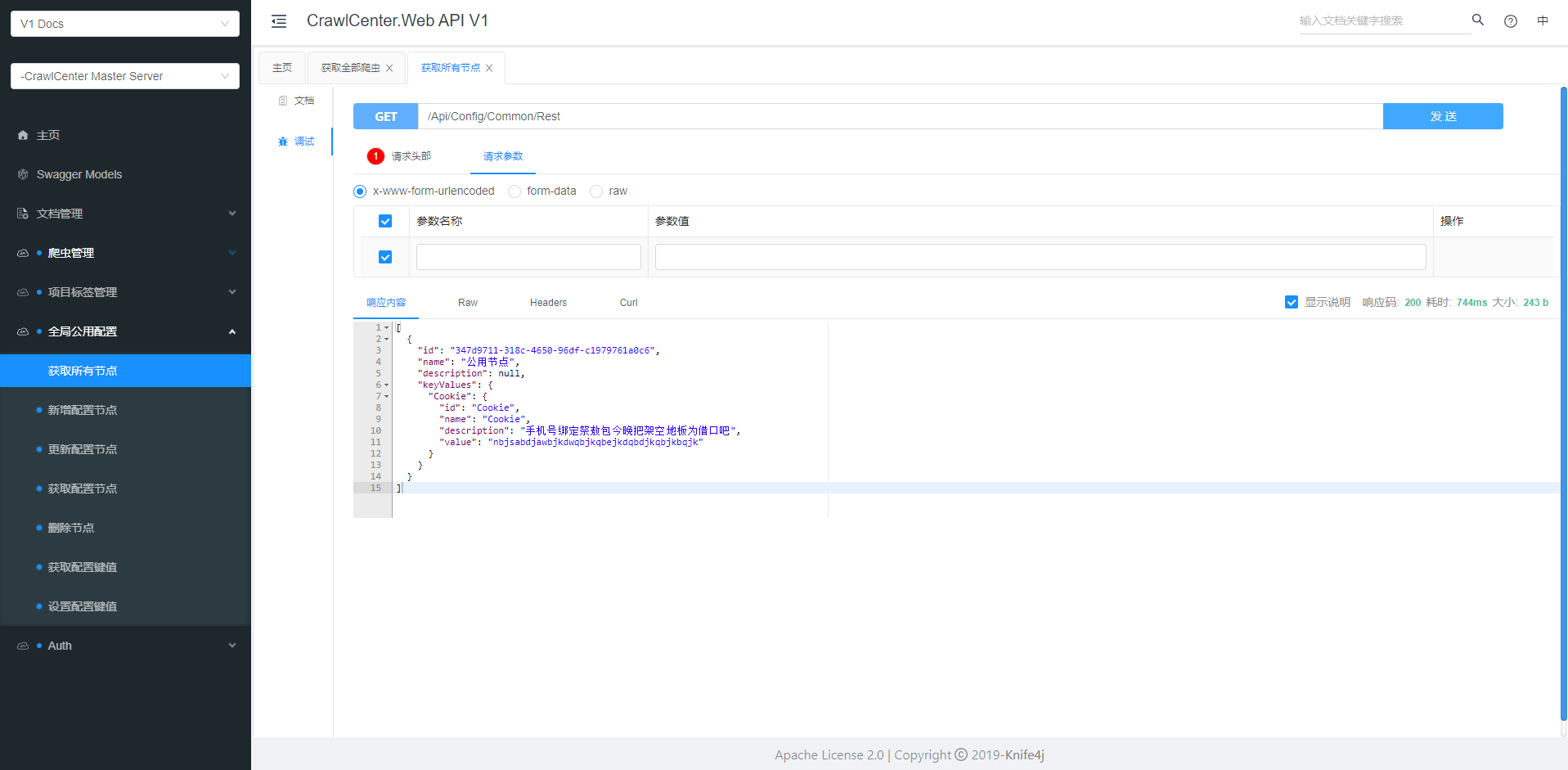
Knife4jUI#
直接看图吧,两栏布局,可以配置全局参数(header、query),测试需要token才能访问的接口很方便!
还支持导出离线文档(markdown、HTML、word、PDF),锦上添花吧,基本没怎么用到。
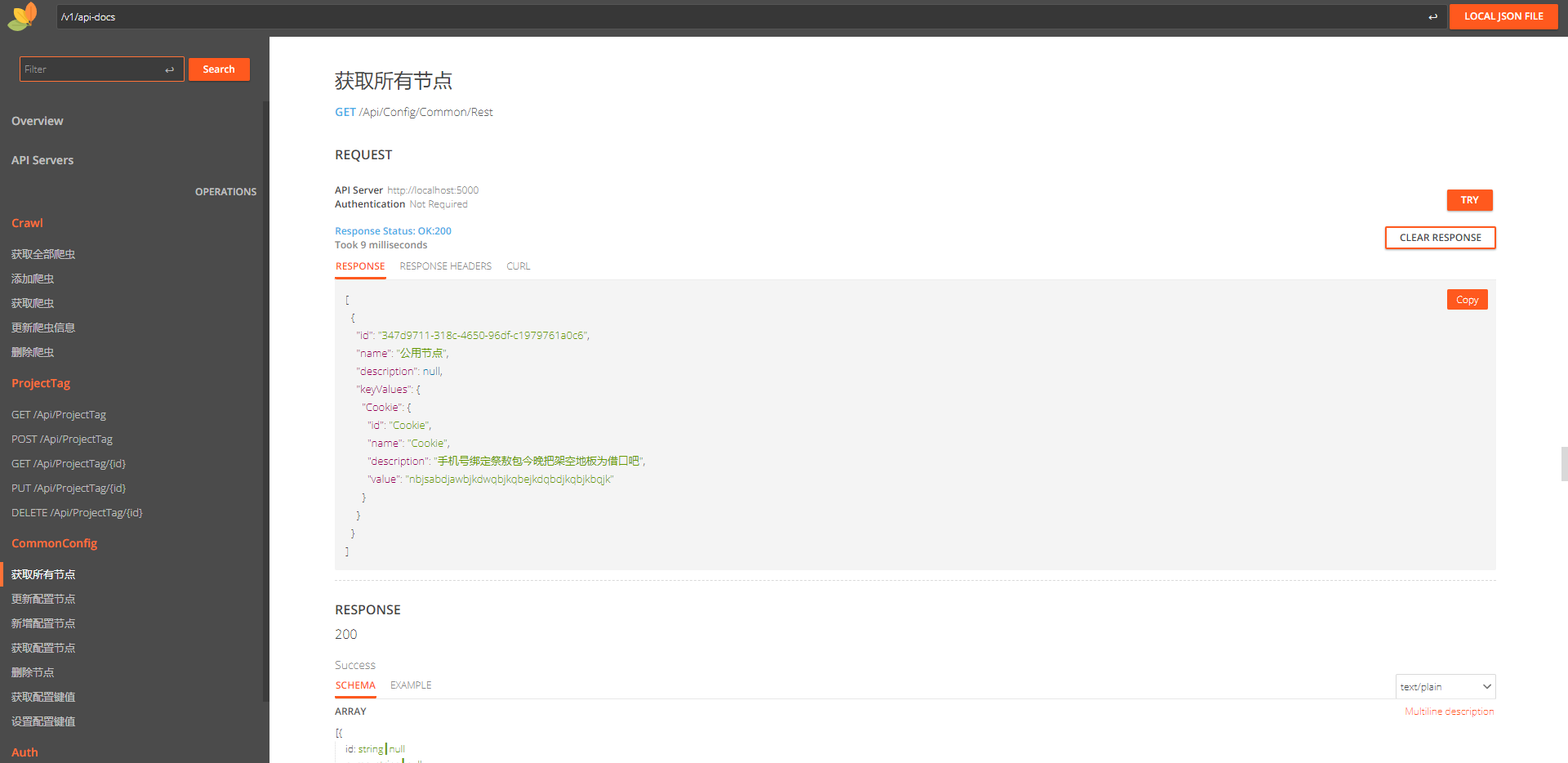
RapiDoc#
也是两栏布局,不过有些功能还没封装好,只能说刚好够用吧~
如果只是要一个简单的交互式文档,不需要授权认证啥的,可以用一用,界面挺清爽的
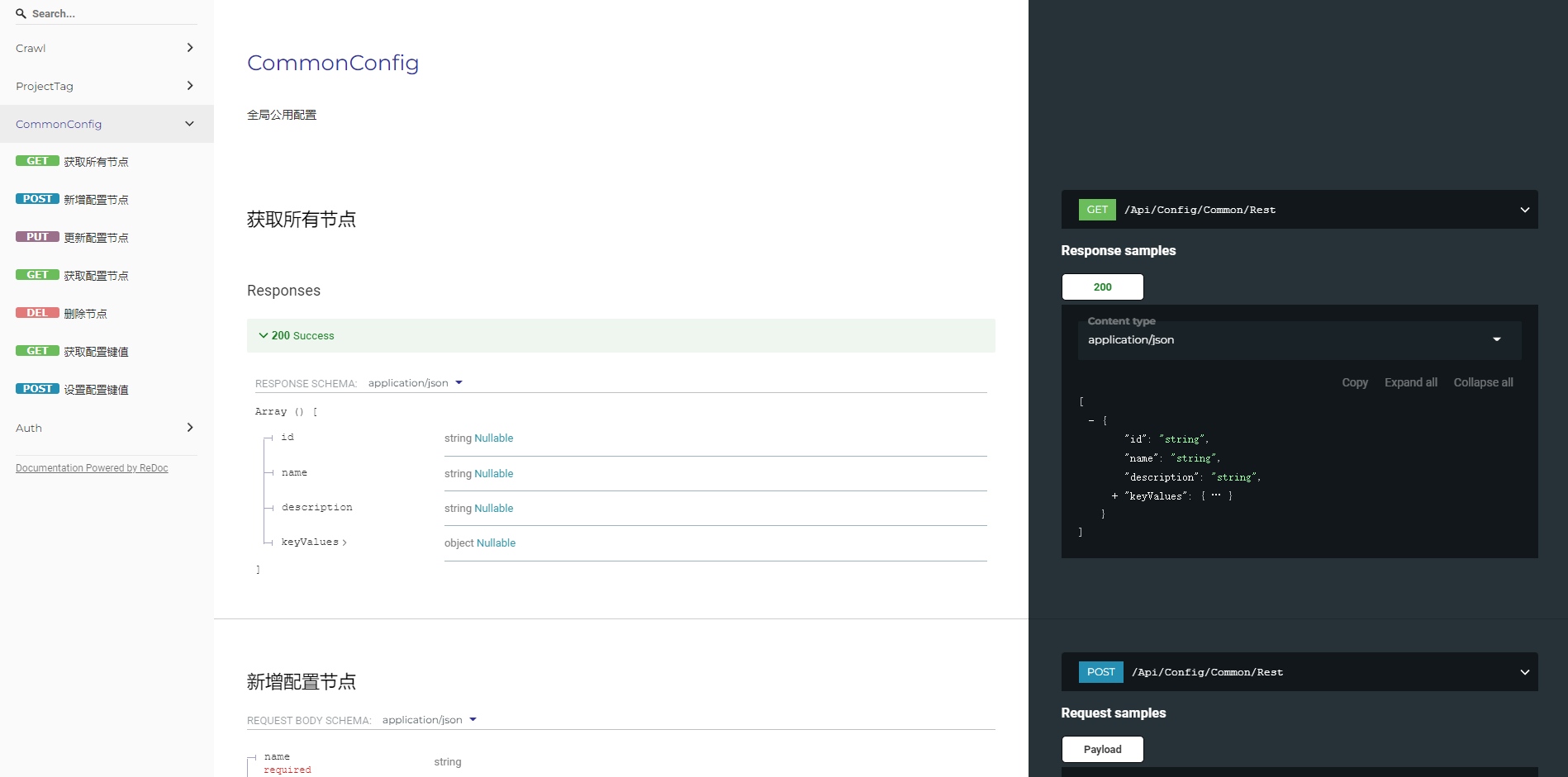
Redoc#
Redoc是Swashbuckle.AspNetCore提供的,需要安装Swashbuckle.AspNetCore.ReDoc这个nuget包。
两栏布局,但是这个redoc是不支持交互的,就单纯看~
界面感觉还不错,不过不支持交互就显得比较鸡肋了
接口测试工具#
除了我们自己的项目通过OpenApi自动导出的接口文档可以进行接口测试,有时候需要借助接口测试工具来测试一些合作方提供的接口,或者是把OpenApi导出的接口导入到接口测试工具来测试,还可以利用这些工具的团队协作功能来进行文档共享~
主流的接口测试工具大家第一个想到的就是postman吧,我也觉得很好用,最近也有看到一些国产的工具,也试着用了下~
- Postman:老牌工具,没啥好说的,就是免费版限制团队只能3个人
- ApiPost:国产工具,高仿postman,免费版团队可以15人,不错!(缺点是界面上有不少的广告)
- ApiFox:同样国产的,界面比ApiPost好看一点点,不过功能差一些,不推荐~
用了一圈下来,体验最好仍然是postman,不过postman团队只能3人,不够用啊!
然后我试了下师弟推荐的国产工具,首先是ApiFox,功能不全,比如针对每个项目设置全局header功能就没有,pass掉~
然后ApiPost,这玩意几乎就是中文版的postman,布局都很相似,团队可以支持15人,还可以~ 不过它患有国产软件的通病,狗皮膏药广告太多,有点恶心~ 不过都免费了还要啥自行车呢?凑合着用吧
参考资料#
- Swashbuckle.AspNetCore项目:https://github.com/domaindrivendev/Swashbuckle.AspNetCore
- Knife4jUI项目:https://github.com/luoyunchong/IGeekFan.AspNetCore.Knife4jUI
- RapiDoc项目:https://github.com/luoyunchong/IGeekFan.AspNetCore.RapiDoc
序列化#
本文的序列化就是说json对象序列化哈~
在.netcore3之前没有内置json库,所以序列化是依赖NewtonsoftJson这个库的,这个没啥好说的,挺好用的,而且发展这么多年了,这个库也很稳定了~
然后后面.netcore官方支持json了,我立刻转向System.Text.Json,不用额外装nuget包,真是方便,哈哈哈
// 序列化json
var json = JsonSerializer.Serialize(new {
login_state = loginStateCode,
client_id = "client123"
});
// 反序列化
public class LoginStateCodeResponse {
public int state { get; set; }
public object request { get; set; }
public string message { get; set; }
public string cause { get; set; }
public Dictionary<string, dynamic> variables { get; set; }
public string data { get; set; }
}
var data = JsonSerializer.Deserialize<LoginStateCodeResponse>(content);
提一下,C#的匿名对象真好用~
关于NewtonsoftJson的代码就不贴了,官网上有,简单易懂~
然后还有一个关于WebApi序列化的问题,跟设计有关,但在涉及到关联字段的时候经常会遇到,可以看我之前的博客。
参考资料#
- NewtonsoftJson官网:https://www.newtonsoft.com/json
序列化#
现在我们数据交互用的基本是JSON格式,在以前不用说,JSON首选就NewtonsoftJson,不过现在多了个System.Text.Json,感觉也不错,不用nuget安装第三方库,内置的直接拿来就用,比较方便~
所以我现在也是System.Text.Json用得比较多,用这两个方法,挺方便的
JsonSerializer.Serialize()JsonSerializer.Deserialize<T>()
日志&监控#
参考资料#
- ASP.NET Core 中获取客户端(Client)IP的方法:https://www.cjavapy.com/article/361/
- Exceptionless 5.x 无法正常发送邮件的问题解决:https://www.cnblogs.com/edisonchou/p/solve_the_problem_of_exceptionless_on_cannot_send_emails.html
定时任务 / 异步任务队列#
参考资料#
- Hangfire官方文档:https://docs.hangfire.io/en/latest/getting-started/index.html
- Hangfire项目实践分享:http://www.csharpkit.com/2017-12-03_50092.html
- HangFire Redis storage:https://github.com/marcoCasamento/Hangfire.Redis.StackExchange
todo#
关于开发实践只写了这么多,因为掌握的东西很有限没办法,不过学海无涯,有一些我有了解但是并未实践过的技术在这里记录下,接下来有时间研究实践一下。
接口节流还没做#
这个节流没做大概是因为AspNetCore的性能太好了,也是我们的项目规模比较小,单机足以轻松支撑,所以我也没有像之前用Django做项目那样去设置接口限流。
按照AspNetCore这种方便的设计,限流应该也是在IServiceColletion里一行代码配置的事吧~
作者:DealiAxy
出处:https://www.cnblogs.com/deali/p/18011887
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
微信公众号:「程序设计实验室」
新版StarBlog已经上线,地址:http://blog.deali.cn




【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Deepseek官网太卡,教你白嫖阿里云的Deepseek-R1满血版
· 2分钟学会 DeepSeek API,竟然比官方更好用!
· .NET 使用 DeepSeek R1 开发智能 AI 客户端
· DeepSeek本地性能调优
· 一文掌握DeepSeek本地部署+Page Assist浏览器插件+C#接口调用+局域网访问!全攻略