Canal 使用入门
- Canal 基础认知
- canal简介
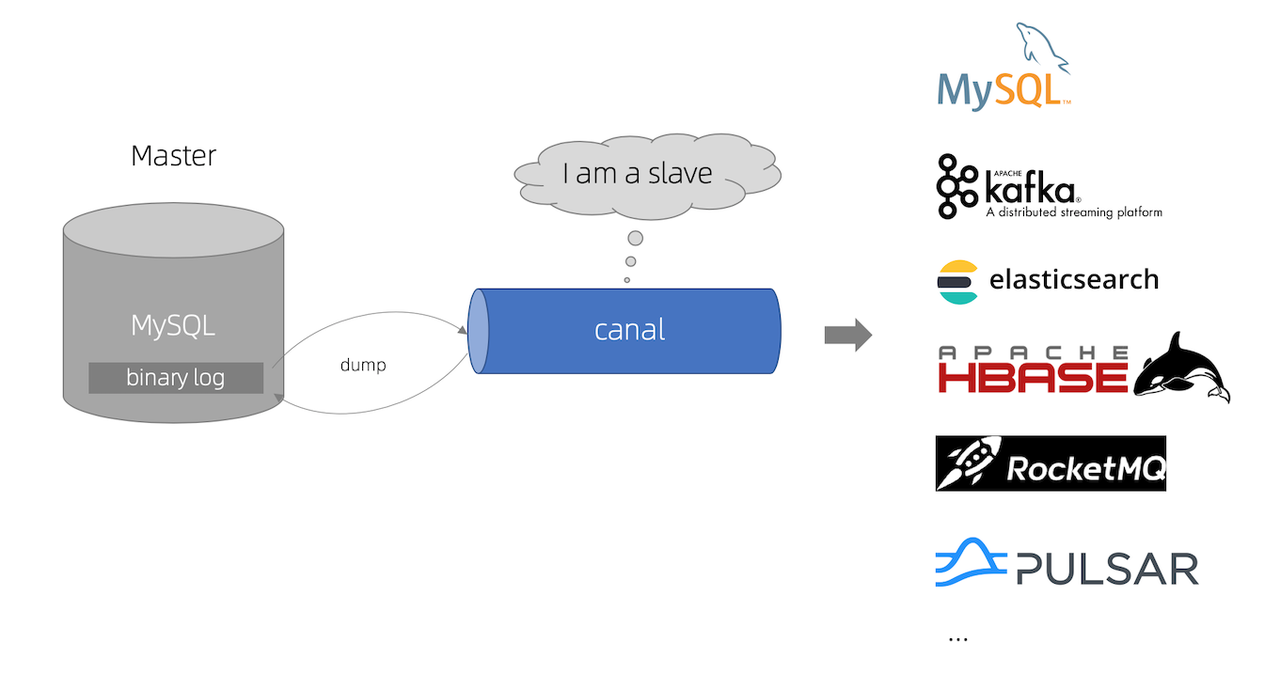
Canal 译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,
实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。 基于日志增量订阅和消费的业务包括 - 数据库镜像 - 数据库实时备份 - 索引构建和实时维护(拆分异构索引、倒排索引等) - 业务 cache 刷新 - 带业务逻辑的增量数据处理 当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x![]()
- canal原理
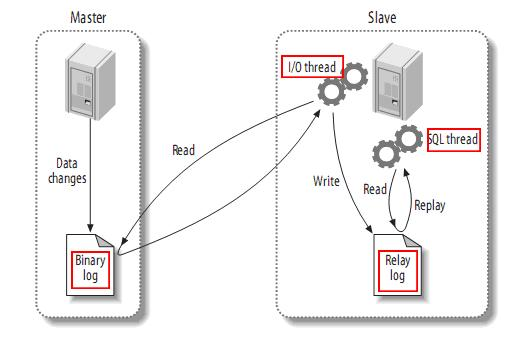
- MySQL主备复制原理
MySQL master(主)将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看) MySQL slave(从)将 master 的 binary log events 拷贝到它的中继日志(relay log) MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据![]()
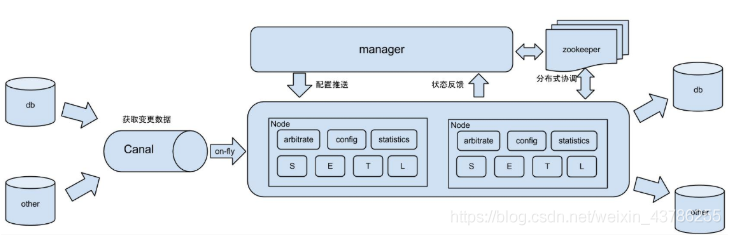
- Canal工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议 MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal) canal 解析 binary log 对象(原始为 byte 流),用户使用canal客户端对数据进行进一步处理
![]()
- MySQL主备复制原理
- Canal官方文档
- Canal源代码
- Canal架构简单说明
个人认知: 一个Canal Sever服务器中可以包含一个或者多个Instance(实例|目的地),每一个Instance就是一个任务处理线程,用于从不同的MySQL服务器或者同一个MySQL的
不同数据库监听收集binlog日志(canal监听mysql的数据配置在example/instance.properties文件中),canal默认提供一个example实例,
如果需要多个实例在conf中创建一个文件夹instanceA,复制example/instance.properties文件到instanceA中并修改,在canal.properties文件中设置destinations时逗号分割,
如果没有设置则实例无效![]()
- Canal安装包文件目录
conf/ ├── canal_local.properties ├── canal.properties ├── example │ ├── h2.mv.db │ ├── instance.properties │ └── meta.dat ├── logback.xml ├── metrics │ └── Canal_instances_tmpl.json └── spring ├── base-instance.xml ├── default-instance.xml ├── file-instance.xml ├── group-instance.xml ├── memory-instance.xml └── tsdb ├── h2-tsdb.xml ├── mysql-tsdb.xml ├── sql │ └── create_table.sql └── sql-map ├── sqlmap-config.xml ├── sqlmap_history.xml └── sqlmap_snapshot.xml
- 重要配置文件说明
- canal.properties
canal.properties这个配置文件负责的是canal服务的基础配置,每个canal可以启动多个实例instance,一个instance代表一个数据采集处理线程,
每个instance都有一个独立的配置文件instance.properties,不同的instance可以采集不同的mysql数据库,也就是一个canal可以对应多个mysql数据库。在instance里面有一个小队列,可以理解为是jvm级的队列,instance抓取来的数据先放入到队列中,队列可以有很多出口: ①mq模式:canal server自己主动把数据推送到kafka,这个比较简单,一行代码不用写,只需要配个kafka|rocketmq|rabbitmq的地址, 每个instance对应kafka的一个topic,数据是json串。 这种方式虽然简单,但是其缺点主要体现在两个个方面,一个instance对应一个topic,所有表都在这一个topic,所以实时的时候要进行分流。 另一方面,因为数据是json,并且携带了很多冗余信息,但是数据量大的时候传输效率比较低。 ②tcp模式:启动canal客户端连接到canal服务器端之后,主动去拉取数据,可以定义多长周期消费多少数据。缺点在于抓取出来的是序列化压缩的数据, 所以需要反序列化,解压,比较麻烦。优点在于我们可以进行压缩,过滤掉没用的冗余信息,只保留我们需要的信息,提交传输效率。########################################################## common argument ############################################################### tcp bind ip |canal server绑定的本地IP信息,如果不配置,默认选择一个本机IP进行启动服务canal.ip =# register ip to zookeeper |canal server注册到外部zookeeper、admin的ip信息 (针对docker的外部可见ip)canal.register.ip =# canal server提供socket服务的端口,端口号,是给tcp模式(netty)时候用的,如果用了kafka或者rocketmq,就不需要配置这个端口canal.port = 11111canal.metrics.pull.port = 11112# canal instance user/passwd canal数据端口订阅的ACL配置 (v1.1.4新增)如果为空,代表不开启#canal.user = canal# canal数据端口订阅的ACL配置 (v1.1.4新增)如果为空,代表不开启#canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458# canal admin config|canal链接canal-admin的地址 (v1.1.4新增)canal.admin.manager = 127.0.0.1:8089# admin管理指令链接端口 (v1.1.4新增)canal.admin.port = 11110# admin管理指令链接的ACL配置 (v1.1.4新增)canal.admin.user = admin# admin管理指令链接的ACL配置 (v1.1.4新增)canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441# canal server链接zookeeper集群的链接信息,单机部署不需要配置,集群部署需要配置canal.zkServers =# flush data to zk| canal持久化数据到zookeeper上的更新频率,单位毫秒canal.zookeeper.flush.period = 1000canal.withoutNetty = false# tcp, kafka, RocketMQ| Canal模式设定,主要有tcp和mq两种类型canal.serverMode = tcp# flush meta cursor/parse position to file|主要针对h2-tsdb.xml时对应h2文件的存放目录,默认为conf/xx/h2.mv.dbcanal.file.data.dir = ${canal.conf.dir}canal.file.flush.period = 1000## memory store RingBuffer size, should be Math.pow(2,n) |canal内存store中可缓存buffer记录数,需要为2的指数canal.instance.memory.buffer.size = 16384## memory store RingBuffer used memory unit size , default 1kb | 内存记录的单位大小,默认1KB,和buffer.size组合决定最终的内存使用大小canal.instance.memory.buffer.memunit = 1024## meory store gets mode used MEMSIZE or ITEMSIZE | canal内存store中数据缓存模式## 1. ITEMSIZE : 根据buffer.size进行限制,只限制记录的数量## 2. MEMSIZE : 根据buffer.size * buffer.memunit的大小,限制缓存记录的大小canal.instance.memory.batch.mode = MEMSIZEcanal.instance.memory.rawEntry = true## detecing config |是否开启心跳检查canal.instance.detecting.enable = false# 心跳检查sql#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()canal.instance.detecting.sql = select 1# 心跳检查频率,单位秒canal.instance.detecting.interval.time = 3# 心跳检查失败重试次数canal.instance.detecting.retry.threshold = 3# 心跳检查失败后,是否开启自动mysql自动切换# 说明:比如心跳检查失败超过阀值后,如果该配置为true,canal就会自动链到mysql备库获取binlog数据canal.instance.detecting.heartbeatHaEnable = false# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions deliverycanal.instance.transaction.size = 1024# mysql fallback connected to new master should fallback times# canal发生mysql切换时,在新的mysql库上查找binlog时需要往前查找的时间,单位秒# 说明:mysql主备库可能存在解析延迟或者时钟不统一,需要回退一段时间,保证数据不丢canal.instance.fallbackIntervalInSeconds = 60# network config# 网络链接参数,SocketOptions.SO_RCVBUFcanal.instance.network.receiveBufferSize = 16384# 网络链接参数,SocketOptions.SO_SNDBUFcanal.instance.network.sendBufferSize = 16384# 网络链接参数,SocketOptions.SO_TIMEOUTcanal.instance.network.soTimeout = 30# binlog filter config
# 是否使用druid处理所有的ddl解析来获取库和表名
canal.instance.filter.druid.ddl = true
# 是否忽略dcl语句
canal.instance.filter.query.dcl = false
# 是否忽略dml语句(mysql5.6之后,在row模式下每条DML语句也会记录SQL到binlog中,可参考MySQL文档)
canal.instance.filter.query.dml = false
# 是否忽略ddl语句
canal.instance.filter.query.ddl = false
# 是否忽略binlog表结构获取失败的异常(主要解决回溯binlog时,对应表已被删除或者表结构和binlog不一致的情况)
canal.instance.filter.table.error = false
# 是否dml的数据变更事件(主要针对用户只订阅ddl/dcl的操作)
canal.instance.filter.rows = false
# 是否忽略事务头和尾,比如针对写入kakfa的消息时,不需要写入TransactionBegin/Transactionend事件
canal.instance.filter.transaction.entry = false# binlog format/image check
# 支持的binlog format格式列表(otter会有支持format格式限制)
canal.instance.binlog.format = ROW,STATEMENT,MIXED
# 支持的binlog image格式列表(otter会有支持format格式限制)
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB# binlog ddl isolation
# ddl语句是否单独一个batch返回(比如下游dml/ddl如果做batch内无序并发处理,会导致结构不一致)
canal.instance.get.ddl.isolation = false# parallel parser config
# 是否开启binlog并行解析模式
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2| binlog并行解析的异步ringbuffer队列(必须为2的指数)
canal.instance.parser.parallelBufferSize = 256# table meta tsdb info
# 是否开启tablemeta的tsdb能力
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360#################################################
######### destinations #############
#################################################
# 当前server上部署的instance列表,多个使用逗号分隔
canal.destinations =
# conf root dir | conf/目录所在的路径
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance | 开启instance自动扫描
# 如果配置为true,canal.conf.dir目录下的instance配置变化会自动触发
canal.auto.scan = true
# instance自动扫描的间隔时间,单位秒
canal.auto.scan.interval = 5
# v1.0.25版本新增,全局的tsdb配置方式的组件文件
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
# 全局配置加载方式
canal.instance.global.mode = manager
# 全局lazy模式
canal.instance.global.lazy = false
# 全局的manager配置方式的链接信息
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
# 全局的spring配置方式的组件文件
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml##################################################
######### MQ #############
##################################################
# kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092
canal.mq.servers = 127.0.0.1:6667
# 发送失败重试次数
canal.mq.retries = 0
# kafka为ProducerConfig.BATCH_SIZE_CONFIG,每次发送批量消息的个数
canal.mq.batchSize = 16384
# kafka为ProducerConfig.MAX_REQUEST_SIZE_CONFIG
canal.mq.maxRequestSize = 1048576
# kafka为ProducerConfig.LINGER_MS_CONFIG , 如果是flatMessage格式建议将该值调大, 如: 200
canal.mq.lingerMs = 100
# kafka为ProducerConfig.BUFFER_MEMORY_CONFIG
canal.mq.bufferMemory = 33554432
# 获取canal数据的批次大小
canal.mq.canalBatchSize = 50
# 获取canal数据的超时时间
canal.mq.canalGetTimeout = 100
# 是否为json格式
canal.mq.flatMessage = true
canal.mq.compressionType = none
# kafka为ProducerConfig.ACKS_CONFIG
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = test - canl_local.properties
# 主要定义了本地webUI # register ip canal.register.ip = # canal admin config canal.admin.manager = 127.0.0.1:8089 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441 # admin auto register canal.admin.register.auto = true canal.admin.register.cluster = canal.admin.register.name =
- example/instance.properties
一个example的目录就是一个instance,canal要配置多个实例采集多个数据源mysql的话如下配置,然后把conf目录下example复制多份,分别重命名,如下########################################################## destinations ##############################################################canal.destinations = example1,example2,example3————————————————################################################### mysql serverId , v1.0.26+ will autoGen|作为Mysql从节点的id,1.0.26版本之后会自动生成# canal.instance.mysql.slaveId=0# enable gtid use true/false | 是否启用mysql gtid的订阅模式canal.instance.gtidon=false# position info# mysql主库链接地址canal.instance.master.address=rm-qj0lin9gpm5hn841b.mysql.rds.cnipaig2.cloud:3306# mysql主库链接时起始的binlog文件canal.instance.master.journal.name=# mysql主库链接时起始的binlog偏移量canal.instance.master.position=# mysql主库链接时起始的binlog的时间戳canal.instance.master.timestamp=# mysql主库链接时对应的gtid位点canal.instance.master.gtid=# rds oss binlogcanal.instance.rds.accesskey=canal.instance.rds.secretkey=canal.instance.rds.instanceId=# table meta tsdb infocanal.instance.tsdb.enable=fasle#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb#canal.instance.tsdb.dbUsername=canal#canal.instance.tsdb.dbPassword=canal#canal.instance.standby.address =#canal.instance.standby.journal.name =#canal.instance.standby.position =#canal.instance.standby.timestamp =#canal.instance.standby.gtid=# username/password# mysql数据库帐号canal.instance.dbUsername=rds_test# mysql数据库密码canal.instance.dbPassword=rds_test123canal.instance.connectionCharset = UTF-8# enable druid Decrypt database passwordcanal.instance.enableDruid=false#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==# table regex| 需要采集的MySQL表过滤匹配表达式canal.instance.filter.regex=.*\\..*# table black regex 数据表黑名单过滤匹配表达式canal.instance.filter.black.regex=# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch# mq config | mq的topic信息canal.mq.topic=drds# dynamic topic route by schema or table regex|是否每张表动态匹配一个topic#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*# mq的分区数量canal.mq.partition=0# hash partition config | 散列模式的分区数#canal.mq.partitionsNum=3#canal.mq.partitionHash=test.table:id^name,.*\\..*#################################################
- canal.properties
- Canal安装包文件目录
- canal简介
- Canal使用前提条件--安装MySQL+开启binlog支持(Mac)
- 下载Mac版本MySQL安装包
mysql dmg安装包下载地址,选择版本和系统版本下载 https://downloads.mysql.com/archives/community/
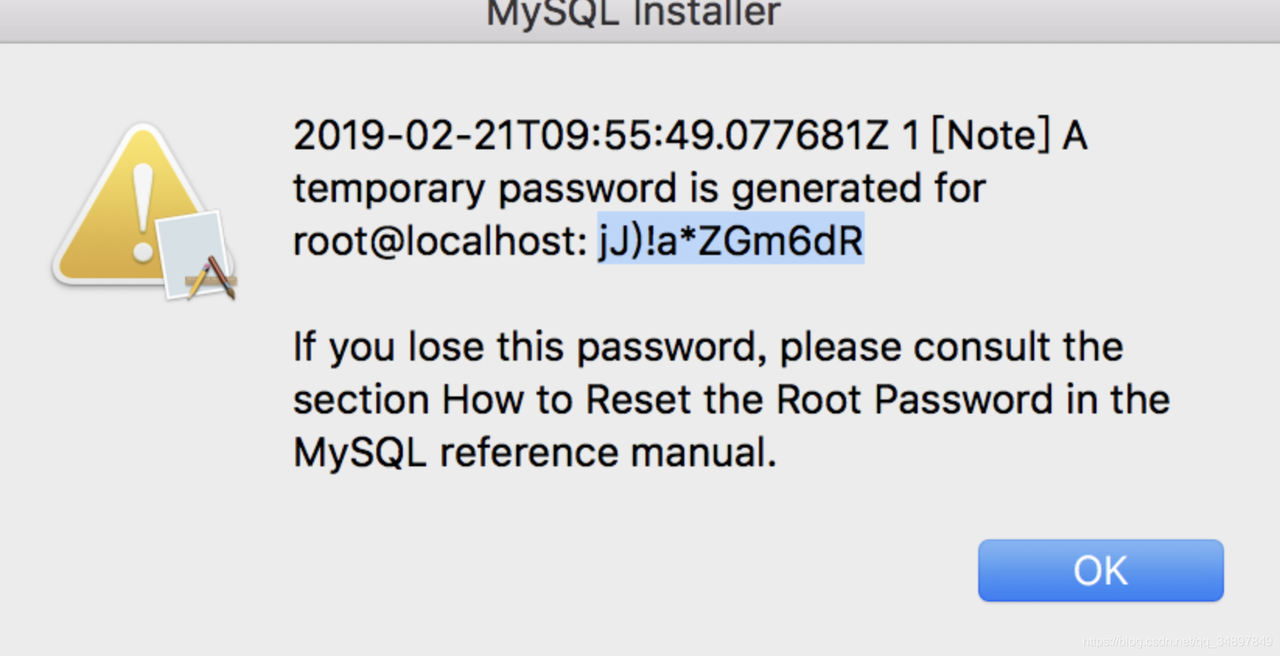
- 安装dmg安装包
需要注意在最后一步安装会生成一个root用户秘密,需要记录下来
![]()
- 设置环境变量
vim /etc/profile export PATH=$PATH:/usr/local/mysql/bin vim ~/.bash_profile export PATH=$PATH:/usr/local/mysql/bin source /etc/profile source ~/.bash_profile
- 启动MySQL
apple---系统便好设置---mysql----启动mysql
- 修改root用户密码+创建canal用户
mysql -u root -p’你刚才的密码’ alter user root@localhost identified by 'root'; GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' ; -- canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限 CREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; flush privileges; -- 针对已有的账户可通过grants查询权限: show grants for 'canal' ;
- 开启MySQL的binlog日志
-- canal的原理是基于mysql binlog技术,所以这里一定需要开启mysql的binlog写入功能,并且配置binlog模式为row. vim /etc/my.cnf [mysqld] default-storage-engine=INNODB character-set-server=utf8 log-bin = mysql-bin binlog-format = ROW server_id = 1 port = 3306 [client] default-character-set=utf8 -- 重启mysql--同启动步骤 -- 验证binlog是否开启 mysql> show variables like 'binlog_format'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ mysql> show variables like 'log_bin'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | log_bin | ON | +---------------+-------+
- 下载Mac版本MySQL安装包
-
单机部署Canal(Mac)
- 下载安装包
cd /data/app wget https://github.com/alibaba/canal/releases/download/canal-1.1.15/canal.deployer-1.1.15.tar.gz
- 解压安装包
cd /data/app mkdir canal-server-1.1.15 tar zxvf canal.deployer-$version.tar.gz -C canal-server-1.1.15
- 使用tcp模式-客户端主动拉取模式
- 配置文件
- conf.canal.properties
################################################# ######### common argument ############# ################################################# # tcp bind ip canal.ip = # register ip to zookeeper canal.register.ip = canal.port = 11111 canal.metrics.pull.port = 11112 # canal instance user/passwd # canal.user = canal # canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458 ################################################# ######### destinations ############# ################################################# canal.destinations = example # conf root dir canal.conf.dir = ../conf # auto scan instance dir add/remove and start/stop instance canal.auto.scan = true canal.auto.scan.interval = 5 # set this value to 'true' means that when binlog pos not found, skip to latest. # WARN: pls keep 'false' in production env, or if you know what you want. canal.auto.reset.latest.pos.mode = false # tcp, kafka, rocketMQ, rabbitMQ canal.serverMode = tcp
- conf/example/instance.properties
################################################# ## mysql serverId , v1.0.26+ will autoGen canal.instance.mysql.slaveId=1234 # position info canal.instance.master.address=127.0.0.1:3306 canal.instance.master.journal.name= canal.instance.master.position= canal.instance.master.timestamp= canal.instance.master.gtid= # username/password canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 # enable druid Decrypt database password canal.instance.enableDruid=false #canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ== # table regex #canal.instance.filter.regex=.*\\..* canal.instance.filter.regex=douc_0827\\..*,dosm_activiti_0827\\..*
- conf.canal.properties
- 启动canal
cd /data/app/canal-server-1.1.15 ./bin/startup.sh
- 查看日志
canal服务器日志文件目录 cd /data/app/canal-server-1.1.15/logs/canal example实例日志文件目录 cd /data/app/canal-server-1.1.15/logs/example
- 项目搭建与测试
- pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>spring-boot-cancal</artifactId> <groupId>com.example</groupId> <version>0.0.1-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>canal-use-demo</artifactId> <dependencies> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-to-slf4j</artifactId> <version>2.7</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.48</version> <scope>runtime</scope> </dependency> <!--引入canal依赖--> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.client</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.common</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.alibaba.otter</groupId> <artifactId>canal.protocol</artifactId> <version>1.1.5</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.2.6</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>1.1.1</version> </dependency> </dependencies> </project>
- 工具类
public class CanalUtils { /** * 获取canal连接器 */ public static CanalConnector getSingleCanalConnector(String host,int port,String desc,String user,String password){ CanalConnector connector = CanalConnectors.newSingleConnector( new InetSocketAddress(host,port), desc, user, password); return connector; } /** * 获取集群canal连接器 */ public static CanalConnector getClusterCanalConnector(List<? extends SocketAddress> addresses, String desc, String user, String password){ CanalConnector connector = CanalConnectors.newClusterConnector(addresses, desc, user, password); return connector; } public static CanalConnector getClusterCanalConnectorV2(List<Map<String,String>> adrs, String desc, String user, String password){ List<InetSocketAddress> addresses = new ArrayList<>(); adrs.forEach(en ->{ String host = en.get("host"); String port = en.get("port"); addresses.add(new InetSocketAddress(host,Integer.parseInt(port))); }); CanalConnector connector = CanalConnectors.newClusterConnector(addresses, desc, user, password); return connector; } /** * 获取由zookeeper组成的canal集群链接 */ public static CanalConnector getClusterCanalConnector(String zkHost, String desc, String user, String password){ CanalConnector connector = CanalConnectors.newClusterConnector(zkHost, desc, user, password); return connector; } public static CanalConnector getLocalCanalConnector(){ // return getCanalConnector(AddressUtils.getHostIp(), 11111, "example", "", ""); return getSingleCanalConnector("127.0.0.1", 11111, "example", "", ""); } /** * 获取MySQL连接 */ public static Connection getMySqlConnnection(String url,String userName,String password){ Connection connection = null; try{ Class.forName("com.mysql.jdbc.Driver"); connection = DriverManager.getConnection(url,userName,password); }catch (Exception e){ System.out.println(e.getLocalizedMessage()); } return connection; } public static boolean execute(Connection conn,String sql){ try(PreparedStatement statement = conn.prepareStatement(sql)){ return statement.execute(); }catch (Exception e){ System.out.println(e.getLocalizedMessage()); } return false; } /** * 获取数据连接池 */ public static DataSource getDataSource(String url,String user,String psd){ DruidDataSource dataSource = new DruidDataSource(); // 2、为数据源实例指定必须的属性 dataSource.setUsername(user); dataSource.setPassword(psd); dataSource.setUrl(url); dataSource.setDriverClassName("com.mysql.jdbc.Driver"); // 3、指定数据源的一些可选属性 // 3.1、指定数据库连接池中出使化连接数的个数 dataSource.setInitialSize(5); // 3.2、指定最大连接数:同意时刻可以同时向数据库申请的连接数 dataSource.setMaxActive(20); // 3.3、指定最小连接数:在数据库连接池中保存的最少的空闲连接的数量 dataSource.setMinIdle(2); // 3.4、等待数据库连接池分配连接的最长时间。单位为毫秒。超出时间将抛出异常 dataSource.setMaxWait(1000 * 5); // 4、从数据源中获取数据库连接 return dataSource; } /** * 数据连接池获取链接 */ public static Connection getConnFromPool(DataSource dataSource) throws Exception{ return dataSource.getConnection(); } }
- 测试类
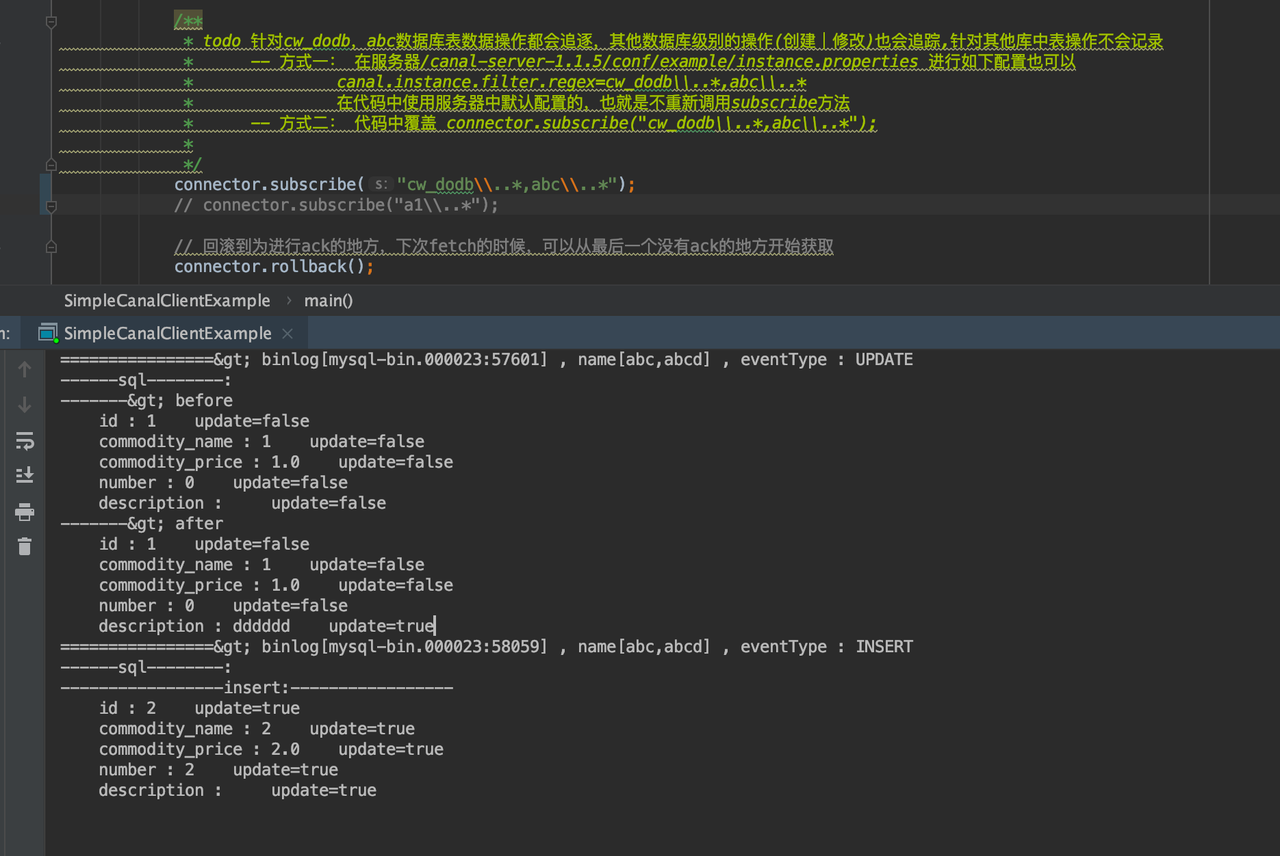
public class SimpleCanalClientExample { public static void main(String[] args) { // 创建链接 CanalConnector connector = CanalUtils.getLocalCanalConnector(); int batchSize = 1000; int emptyCount = 0; int dataCount = 0; try { // 打开链接 connector.connect(); // todo 订阅数据库表,全部表 // connector.subscribe(".*\\..*"); /** * todo 针对cw_dodb,abc数据库表数据操作都会追逐,其他数据库级别的操作(创建|修改)也会追踪,针对其他库中表操作不会记录 * -- 方式一: 在服务器/canal-server-1.1.5/conf/example/instance.properties 进行如下配置也可以 * canal.instance.filter.regex=cw_dodb\\..*,abc\\..* * 在代码中使用服务器中默认配置的,也就是不重新调用subscribe方法 * -- 方式二: 代码中覆盖 connector.subscribe("cw_dodb\\..*,abc\\..*"); * */ // connector.subscribe("cw_dodb\\..*,abc\\..*"); connector.subscribe("a1\\..*"); // 回滚到为进行ack的地方,下次fetch的时候,可以从最后一个没有ack的地方开始获取 connector.rollback(); while (true) { // 获取指定数量的数据 Message message = connector.getWithoutAck(batchSize); // 获取批量ID long batchId = message.getId(); // 获取批量的数量 int size = message.getEntries().size(); // 如果没有数据的处理逻辑 if (batchId == -1 || size == 0) { emptyCount++; // System.out.println("empty count : " + emptyCount); try { Thread.sleep(1000); } catch (InterruptedException e) { } } else { // 有数据的处理emptyCount = 0; dataCount++; // System.out.printf("message[batchId=%s,size=%s] \n", batchId, size); printEntry(message.getEntries()); } // 提交确认,标记ack connector.ack(batchId); System.out.println("---handled data counts: "+dataCount); // 处理失败, 回滚数据 // connector.rollback(batchId); } } finally { connector.disconnect(); } } /** * 打印canal server解析binlog获取的实体类信息 * @param entrys */ private static void printEntry(List<Entry> entrys) { for (Entry entry : entrys) { if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) { // 开启/关闭事务的实体类型,跳过 continue; } /** * RowChange对象,包含了一行数据变化的所有特征 * 比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等 */ RowChange rowChage = null; try { rowChage = RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e); } // 获取针对Mysql数据操作类型:insert/update/delete EventType eventType = rowChage.getEventType(); // 打印Header信息 System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType)); // 判断是否是DDL语句 if(rowChage.getIsDdl()){ System.out.println("================》;isDdl: true,sql: " + rowChage.getSql()); } List<RowData> rowDatasList = rowChage.getRowDatasList(); if(!CollectionUtils.isEmpty(rowDatasList)) { // todo 如果不是DDL的话获取不到原始sql语句,只能通过数据组装成SQL String sql = rowChage.getSql(); System.out.println("------sql--------: "+sql); // 获取RowChange对象里的每一行数据,打印出来 for (RowData rowData : rowChage.getRowDatasList()) { if (eventType == EventType.DELETE) { System.out.println("----------------delete:----------------"); printColumn(rowData.getBeforeColumnsList()); } else if (eventType == EventType.INSERT) { System.out.println("-----------------insert:-----------------"); printColumn(rowData.getAfterColumnsList()); } else { System.out.println("-------> before"); printColumn(rowData.getBeforeColumnsList()); System.out.println("-------> after"); printColumn(rowData.getAfterColumnsList()); } } } } } private static void printColumn(List<Column> columns) { for (Column column : columns) { System.out.println("\t"+column.getName() + " : " + column.getValue() + " update=" + column.getUpdated()); } } }
- pom.xml
- 项目运行与MySQL操作测试
![]()
- 配置文件
- 使用mq模式-服务端主动推送模式
![]()
- 配置文件
- conf/canal.propertie
# tcp, kafka, rocketMQ, rabbitMQ canal.serverMode = kafka ################################################## ######### Kafka ############# ################################################## kafka.bootstrap.servers = 127.0.0.1:9092 kafka.acks = all kafka.compression.type = none kafka.batch.size = 16384 kafka.linger.ms = 1 kafka.max.request.size = 1048576 kafka.buffer.memory = 33554432 kafka.max.in.flight.requests.per.connection = 1 kafka.retries = 0
-
conf/canal.properties
# mq config canal.mq.topic=canal-binlog # dynamic topic route by schema or table regex #canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..* canal.mq.dynamicTopic= canal.mq.partition=0 # hash partition config #canal.mq.partitionsNum=3 #canal.mq.partitionHash=test.table:id^name,.*\\..* #canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
- conf/canal.propertie
- 启动canal
cd /data/app/canal-server-1.1.15 ./bin/startup.sh
- MySQL操作+件套Kafka消息
![]()
- 配置文件
- 下载安装包
- 集群部署Canal(Linux-host01,host02)
- zookeeper安装
- canal集群部署与测试
- canal集群工作原理
一个canal服务器进程,每一个instance就是一个线程,单独对应一个mysql服务器的binlog。再起一个canal服务的话,对于同一个mysql服务器不能做负载均衡,数据分片等。有两个canal服务器 都监控一个或多个mysql服务器的binlog。 这两个canal服务同时只能有一个提供服务,当提供服务的这个宕机时,zookeeper能知道,zookeeper就通知另一个canal服务器让他提供服务。当原来宕机的那个再启动起来时,是抢占模式的, 谁抢到就谁上,没抢到就standy模式。 canal本身就是一个工具不存数据,宕机了就宕机,只有还有另外一个能提供服务就行,所以没有什么同步问题(不像数据库有同步问题)。因为启动canal服务是需要消耗资源的,不想redis高可用 占资源太少了。canal的standy资源也不能给少了,要双份资源,就看企业在意不在意,服务核心不核心。 maxwell和canal非常像,maxwell连高可用机制都没提供,倒了就再起。其实很多软件都是不提供高可用方案的,如果怕他倒的话,可以用Keepalived,这个机制很简单就是做心跳监测,可以给任何 进程做一个心跳检测,可以一直检测他在不在进程列表里,如果宕了进程没了他会有一系列触发操作,可以在他里面写一个shell,如还有一个备机,要是这个挂了就在备机启动。或者自己手工在restart, 这是一种通用型方案。Keepalived和maxwell是完全没有耦合关系的,maxwell完全不知道Keepalived的存在,Keepalived是从外围的观察者观察这个进程,不像zookeeper,是需要向它注册的。 注意:这里zookeeper为观察者监控的模式,只能实现高可用,而不是负载均衡, 即同一时点只有一个canal-server节点能够监控某个数据源,只要这个节点能够正常工作, 那么其他监控这个数据源的canal-server只能做stand-by,直到工作节点停掉,其他canal-server节点才能抢占。
- canal服务器配置文件修改
======= host01 # 修改配置信息 cd /data/app/canal-server-1.1.5 rm -rf conf/example/meta.dat rm -rf conf/example/h2* cd conf vim canal.properties ################################################# ######### common argument ############# ################################################# # tcp bind ip canal.ip = # register ip to zookeeper 每个实例推荐使用不同的ip canal.register.ip = 10.1.1.2 canal.port = 11111 canal.metrics.pull.port = 11112 canal.zkServers =127.0.0.1:2181 ====== host02 # 进行复制和修改 cd /data/app/canal-server-1.1.5 rm -rf conf/example/meta.dat rm -rf conf/example/h2* cd conf vim canal.properties ################################################# ######### common argument ############# ################################################# # tcp bind ip canal.ip = # register ip to zookeeper 每个实例推荐使用不同的ip canal.register.ip = 10.1.1.3 canal.port = 11111 canal.metrics.pull.port = 11112 canal.zkServers =127.0.0.1:2181 vim example/instance.properties canal.instance.mysql.slaveId=1235
- zookeeper启动+服务状态检查
1. 启动zookeeper [root@localhost data]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.13/bin/../conf/zoo.cfg Starting zookeeper ... STARTED 2. 启动状态检查 [root@VM-16-13-centos zookeeper-3.4.13]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.13/bin/../conf/zoo.cfg Mode: standalone
- canal集群启动
-- host01,host02上分别执行
cd /data/app/canal-server-1.1.5 ./bin/startup.sh![]()
![]()
![]() 结合如上截图中,两个canal服务器节点通过zookeeper组成集群,两个节点中的instance相同监听同一个MySQL的数据信息,当集群启动时发现最初启动节点的logs目录下存在实例日志文件夹 example,另外一个节点logs目录下却没有,符合canal集群高可用原则,一个处于active一个处于standy状态
结合如上截图中,两个canal服务器节点通过zookeeper组成集群,两个节点中的instance相同监听同一个MySQL的数据信息,当集群启动时发现最初启动节点的logs目录下存在实例日志文件夹 example,另外一个节点logs目录下却没有,符合canal集群高可用原则,一个处于active一个处于standy状态 - canal集群高可用验证
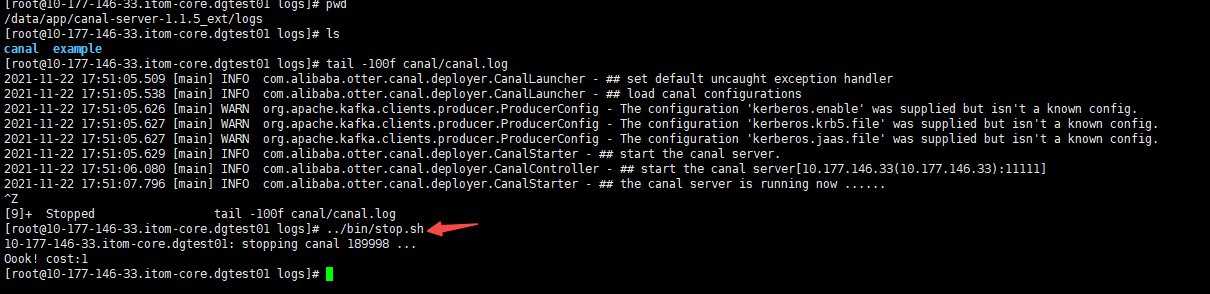
- 在节点10.177.146.33(active)上关闭canal
![]()
- 执行MySQL数据操作,发现canal的kafka依旧有数据写入
![]()
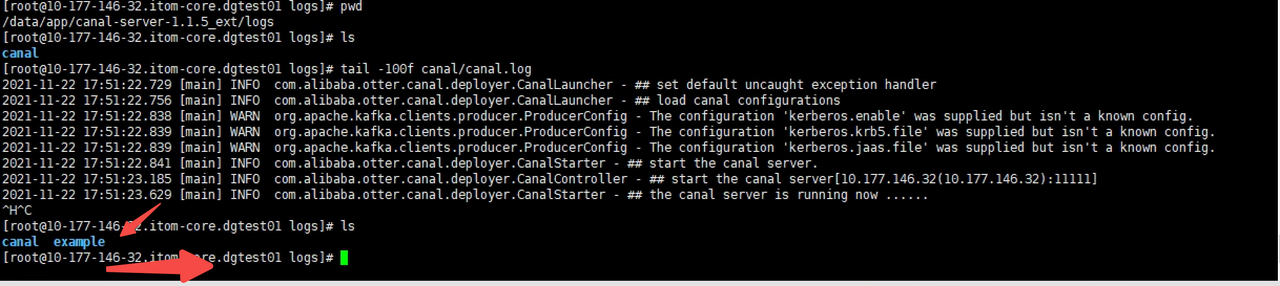
- 查看另外一个节点10.177.146.32(standy),发现logs下出现example实例日志
![]()
- 在节点10.177.146.33上删除logs下所有文件,重启canal之后发现logs目录下未生成example实例日志
![]()
- 总结: 该过程中,active状态节点流转为33-->32
- 在节点10.177.146.33(active)上关闭canal
- canal集群工作原理
- Canal扩展(业务需要)
- 需求说明
-- 使用canal转发收集到的binlog日志到kafka,使用的是canal自定义的JSON数据格式,如下所示 { "data":[ { "a":"ee" } ], "database":"abc", "es":1637578296000, "id":19, "isDdl":false, "mysqlType":{ "a":"varchar(100)" }, "old":null, "pkNames":null, "sql":"", "sqlType":{ "a":12 }, "table":"abc", "ts":1637578297135, "type":"INSERT" } -- 为了快速接入Dodb,考虑到Dodb有现有功能--Kafka数据源(带存储型),可以将kafka中数据映射到Dodb的数据表ClickHouse表中 -- 考虑到Clickhouse的update,delete性能比较低,将所有的update,delete操作转换为insert操作 新增俩个字段version(DateTime),sign(Int),version使用插入时间毫秒数,sign更新|插入时使用1,删除时使用-1,不过后期需要考虑clickhouse数据去重 { "number":"1", "commodity_price":"1.0", "sign":1, "description":"e8023b930e384692978af8a7af4ea6f6", "id":"d26eea16687a40e2be925cae162c9bd3", "version":1637560526296, "commodity_name":"2" } { "number":"1", "commodity_price":"1.0", "sign":-1, "description":"e8023b930e384692978af8a7af4ea6f6", "id":"d26eea16687a40e2be925cae162c9bd3", "version":1637560726488, "commodity_name":"2" } -- 将收集的不同表中binlog变更数据,分发到对应的各自topic中,之后在dodb中创建对应的Kafka存储型 数据源中,将数据写入Clickhouse数据表
- 扩展思路一
binlog(MySQL)->canal server->kafka producer(Canal内嵌)->kafka consumer(扩展)->kafka producer(扩展)->dodb kafka存储型数据源->ClickHouse -- kafka consumer(扩展项目程序中) 1. 过滤符合条件的数据,根据配置的数据库名称+数据表名称 2. 数据转换,将新增,删除,更新操作统一转换为新增操作,使用字段version-Long,sign—Int作为标识 3. 数据分发,针对采集的表数据,经过转换后每张表数据转发至对应的单个topic中 -- kafka producer(扩展项目程序中) 4. 完成数据转发操作
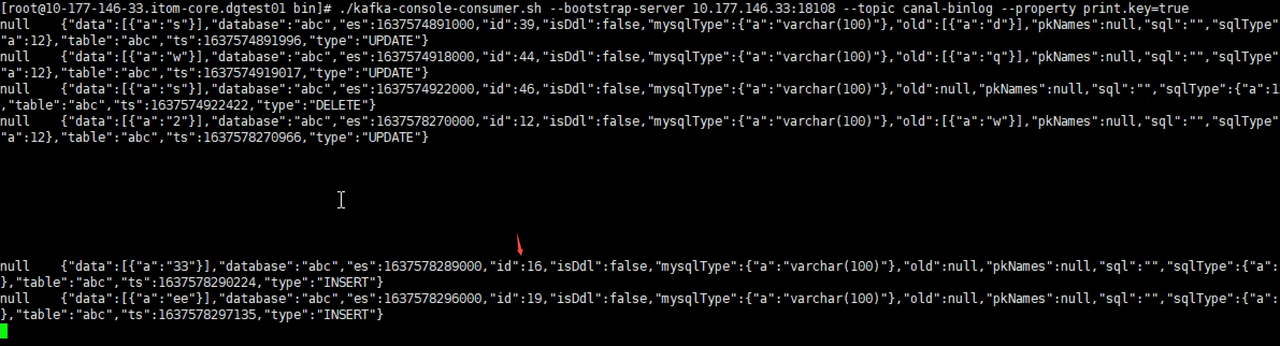
- canal原生内嵌kafka发送数据样例
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic canal-binlog --property print.key=true null {"data":[{"id":"aba1b95e24dd4434909177c2c14f3020","commodity_name":"1","commodity_price":"3.0","number":"3","description":"79d9782c3d174c918fe64ef66d1bc039"}],"database":"abc","es":1637560518000,"id":5,"isDdl":false,"mysqlType":{"id":"varchar(32)","commodity_name":"varchar(512)","commodity_price":"double","number":"int(10)","description":"varchar(2048)"},"old":[{"commodity_name":"desc1"}],"pkNames":["id"],"sql":"","sqlType":{"id":12,"commodity_name":12,"commodity_price":8,"number":4,"description":12},"table":"abc","ts":1637560518949,"type":"UPDATE"} null {"data":[{"id":"d26eea16687a40e2be925cae162c9bd3","commodity_name":"2","commodity_price":"1.0","number":"1","description":"e8023b930e384692978af8a7af4ea6f6"}],"database":"abc","es":1637560526000,"id":6,"isDdl":false,"mysqlType":{"id":"varchar(32)","commodity_name":"varchar(512)","commodity_price":"double","number":"int(10)","description":"varchar(2048)"},"old":[{"commodity_name":"desc1"}],"pkNames":["id"],"sql":"","sqlType":{"id":12,"commodity_name":12,"commodity_price":8,"number":4,"description":12},"table":"abc","ts":1637560526294,"type":"UPDATE"} null {"data":[{"id":"d26eea16687a40e2be925cae162c9bd3","commodity_name":"2","commodity_price":"1.0","number":"1","description":"e8023b930e384692978af8a7af4ea6f6"}],"database":"abc","es":1637560726000,"id":7,"isDdl":false,"mysqlType":{"id":"varchar(32)","commodity_name":"varchar(512)","commodity_price":"double","number":"int(10)","description":"varchar(2048)"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":12,"commodity_name":12,"commodity_price":8,"number":4,"description":12},"table":"abc","ts":1637560726484,"type":"DELETE"} null {"data":[{"id":"wwwwww","commodity_name":"1","commodity_price":"0.0","number":"0","description":"wwwww"}],"database":"abc","es":1637560787000,"id":8,"isDdl":false,"mysqlType":{"id":"varchar(32)","commodity_name":"varchar(512)","commodity_price":"double","number":"int(10)","description":"varchar(2048)"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":12,"commodity_name":12,"commodity_price":8,"number":4,"description":12},"table":"abc","ts":1637560787488,"type":"INSERT"}
- 添加扩展程序后kafka发送数据样例
-- topic 为指定表名称+特定配置的前后缀组成 kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic mysql_abc_topic --property print.key=true null {"number":"3","commodity_price":"3.0","sign":1,"description":"79d9782c3d174c918fe64ef66d1bc039","id":"aba1b95e24dd4434909177c2c14f3020","version":1637560518952,"commodity_name":"1"} null {"number":"1","commodity_price":"1.0","sign":1,"description":"e8023b930e384692978af8a7af4ea6f6","id":"d26eea16687a40e2be925cae162c9bd3","version":1637560526296,"commodity_name":"2"} null {"number":"1","commodity_price":"1.0","sign":-1,"description":"e8023b930e384692978af8a7af4ea6f6","id":"d26eea16687a40e2be925cae162c9bd3","version":1637560726488,"commodity_name":"2"} null {"number":"0","commodity_price":"0.0","sign":1,"description":"wwwww","id":"wwwwww","version":1637560787492,"commodity_name":"1"}
- 扩展代码开发
- pom.xml
<dependencies> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.15</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.20</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.0.2</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>utf-8</encoding> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> </plugin> </plugins> </build> - 静态变量类
public class Constants { /**标记字段 1-更新|新增 -1-删除*/ public static final String SIGN = "sign"; /** 聚合处理字段*/ public static final String VERSION = "version"; public static final Integer ADD_UPDATE = 1; public static final Integer DELETE = -1; /** * 目的数据topic * -- 数据处理完毕之后发送数据的topic * -- 采用每张表的一个topic */ public static final String TOPIC_PREFIX = "mysql_"; public static final String TOPIC_SUFFIX = "_topic"; /**canal转发的kafka消息消费组i*/ public static final String CONSUMER_GROUP_NAME = "from_canal_kafka"; }
- 配置文件
/** * @version 1.0.0 * @ClassName ReWrapperConfig.java * @Description TODO * canal.properties配置文件中添加如下参数 #此参数包含需要采集的数据库.数据表名 custom.async.mysql.db_table.list=douc.dosm_data_dictionary,douc.tab,abc.abc,abc.abcd # 消费canal转发至kafka的binlog消息,进行数据组装+拆分之后发送最终kafka的topic的>前后缀 # 注意: 处理后的每个张表的数据发送往 prefix_table_suffix topic且增删改操作都处>理为增,使用sign,version区分 custom.async.kafka.topic.prefix = mysql_ custom.async.kafka.topic.suffix = _topic */ @Data @Slf4j public class ReWrapperConfig { /**源数据topic -- 对标 canal.mq.topic*/ private String sourceTopic; /**kafka地址 -- 对标 kafka.bootstrap.servers*/ private String kafkaServer; private Thread thread; private KafkaConsumer<String,String> consumer; private KafkaProducer<String, String> producer; /** * 上面将数据库和数据库和数据表拆分为两个参数是有问题的 * -- 此参数包含数据库.数据表名 * -- canal.properties中 新增字段custom.async.mysql.db_table.list */ private String mysqlDbTables; private List<String> dbTables; /** * 解析之后每张表数据采集发送到一个topic中 * -- dodb创建kafka存储性的数据源,映射到对应的表中 * -- canal.properties中 新增字段custom.async.kafka.topic.prefix * -- canal.properties中 新增字段custom.async.kafka.topic.suffix */ private String topic_prefix; private String topic_suffix;
public void init(){ consumer = consumerFromCanalOrinal(); producer = kafkaProducer(); KafkaReWrapperHandler kafkaReWrapperHandler = new KafkaReWrapperHandler(consumer,producer,this); thread = new Thread(kafkaReWrapperHandler); thread.start(); } public void destory(){ if(null != consumer){ consumer.close();} if(null != producer){producer.close(); } if(null != null && !thread.isInterrupted()){ thread.interrupt();} } /** * canal转发的kafka消息消费者 * @return */ public KafkaConsumer<String,String> consumerFromCanalOrinal(){ Properties props = new Properties(); // 定义kakfa 服务的地址,不需要将所有broker指定上 props.put("bootstrap.servers", kafkaServer); // 制定consumer group props.put("group.id",CONSUMER_GROUP_NAME); // 是否自动确认offset props.put("enable.auto.commit", "false"); // 自动确认offset的时间间隔 props.put("auto.commit.interval.ms", "1000"); // key的反序列化类 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // value的反序列化类 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("session.timeout.ms", "60000"); props.put("max.poll.interval.ms", "50000"); props.put("max.poll.records", "5000"); props.put("auto.offset.reset", "latest"); props.put("key.deserializer.encoding", "UTF8"); props.put("value.deserializer.encoding", "UTF8"); props.put("max.partition.fetch.bytes", 209715200); props.put("receive.buffer.bytes", 1024 * 1024 * 10); props.put("fetch.min.bytes", 300); KafkaConsumer<String, String> stringStringKafkaConsumer = new KafkaConsumer<>(props); stringStringKafkaConsumer.subscribe(Arrays.asList(sourceTopic)); return stringStringKafkaConsumer; } /** * 重新处理之后发送Kafka的生产者 * -- 数据来源于初始canal转kafka的binlog数据 * -- 数据进行处理 * -- 发送给各个表对应的topic * @return */ public KafkaProducer<String, String> kafkaProducer() { Properties props = new Properties(); props.put("bootstrap.servers", kafkaServer); /*ack方式,all,会等所有的commit最慢的方式; 1:由Leader确认 如果不是集群部署模式需要将该行代码注释掉,否则报错找不到当前topic可用的Leader*/ //props.put("acks", "1"); // 失败是否重试,设置会有可能产生重复数据 props.put("retries", 0); // 对于每个partition的batch buffer大小 props.put("batch.size", 16384); // 等多久,如果buffer没满,比如设为1,即消息发送会多1ms的延迟,如果buffer没满 props.put("linger.ms", 1); // 整个producer可以用于buffer的内存大小 props.put("buffer.memory", 33554432); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); /*cananl内部存在一个kafka的生产者,需要额外配置该参数,否则将报错 WARN org.apache.kafka.common.utils.AppInfoParser - Error registering AppInfo mbean javax.management.InstanceAlreadyExistsException: kafka.producer:type=app-info,id=DemoProducer*/ props.put("client.id","9999"); return new KafkaProducer<>(props); } /** * 最终数据发送的topic * @param table * @return */ public String getKafkaTopic(String table){ if(Objects.nonNull(topic_prefix) && Objects.nonNull(topic_suffix)){ return topic_prefix+table+topic_suffix; } return TOPIC_PREFIX+table+TOPIC_SUFFIX; } /** * 最新的校验是否是采集的数据 * -- 所有的配置数据从配置文件canal.properties文件中获取 * -- 禁止从常量类Constants中获取 * @param db 数据库名 * @param table 数据表名 * @return */ public boolean isCollectedTable(String db,String table){ if(Objects.isNull(mysqlDbTables)){ return false; } String dt = db+"."+table; return getDbTables().contains(dt); } private List<String> getDbTables(){ if(Objects.isNull(dbTables)){ if(Objects.isNull(mysqlDbTables)){ return dbTables = new ArrayList<>(); } dbTables = Arrays.asList(mysqlDbTables.split(",")) .stream() .distinct() .collect(Collectors.toList()); } return dbTables; } } - 处理类
@Data @Slf4j public class KafkaReWrapperHandler implements Runnable{ private KafkaConsumer<String,String> consumer; private KafkaProducer<String,String> producer; private ReWrapperConfig config; public KafkaReWrapperHandler(KafkaConsumer<String,String> consumer,KafkaProducer<String,String> producer,ReWrapperConfig config){ this.consumer = consumer; this.producer = producer; this.config = config; } @Override public void run() { log.error("------启动KafkaConsumer2---------"); while (!Thread.currentThread().isInterrupted()) { ConsumerRecords<String, String> consumerRecords = consumer.poll(200); for (ConsumerRecord record : consumerRecords) { try{ log.debug("---kafkaConsumer2接收到 :" + record.topic() + "------" + record.key() + "---------" + record.value()); JSONObject jsonObject = JSONObject.parseObject(record.value().toString()); // 变更的数据 JSONArray data = jsonObject.getJSONArray("data"); int size = null == data ? 0 : data.size(); // 数据库信息 String database = jsonObject.getString("database"); Boolean isDdl = jsonObject.getBoolean("isDdl"); JSONArray old = jsonObject.getJSONArray("old"); // 主键信息 JSONArray pkNames = jsonObject.getJSONArray("pkNames"); // sql语句 String sql = jsonObject.getString("sql"); JSONObject sqlType = jsonObject.getJSONObject("sqlType"); // 表名 String table = jsonObject.getString("table"); // 操作类型 String type = jsonObject.getString("type"); log.debug("---当前操作类型:{}", type); log.debug("---当前表名称:{}", table); if(Objects.nonNull(database) && Objects.nonNull(table)){ if(!config.isCollectedTable(database,table)){ log.debug("-- 当前数据操作发生在数据表{}, 该表不属于采集范畴:[{}]",database+"."+table,config.getMysqlDbTables()); continue; } }else{ log.warn("未获取到表名信息,应该不是针对表数据的操作"); if (isDdl) { log.error("----DDL SQL : {}", sql); } continue; } log.warn("---kafkaConsumer2接收需要采集的数据 :" + record.topic() + "------" + record.key() + "---------" + record.value()); /** * -- Database 数据库级别 * drop |create database 都是QUERY类型,都属于ddl * * -- Table 表级别操作 * create table 属于CREATE类型,属于ddl,table为表名 * rename table 属于RENAME类型,属于ddl,table为表名 * drop table 属于ERASE操作类型 * * -- Field 表字段级别操作 * add column 属于ALTER类型,属于ddl * modify column name|type 属于ALTER类型,属于ddl * drop column 属于ALTER类型,属于ddl * * -- 表数据操作 * insert data 属于INSERT类型,(批量)单个insert操作在kafka中都是单独消息 * update data 属于UPDATE类型,单个更新每个update操作都在Kafka中都是单独消息 * 批量更新- 单个消息data和old都是多个数据-更新数数组数据 * delete data 属于DELETE类型,单个删除在kafka中都是一个单独消息 * 批量删除- 单个消息包含多个操作 */ String topic = config.getKafkaTopic(table); Long ts = jsonObject.getLong("ts"); if(null == ts){ ts = System.currentTimeMillis(); } if(null != data){ addFieldsAndSend(topic, data, type,ts); } }catch (Exception e){ log.error("---消费从canal转发kafka的消息失败{}/{}",e.getLocalizedMessage(),e); }finally { // 手动提交 consumer.commitAsync(); } } } } private void addFieldsAndSend(String topic, JSONArray data, String type,Long ts) { for (int i = 0; i < data.size(); i++) { JSONObject jsonObject = data.getJSONObject(i); // Long类型的数据比DateTime类型在后续Clickhouse中数据去重时辨识度更高 ts = ts +(i+1); jsonObject.put(VERSION,ts); switch (type){ case "INSERT": jsonObject.put(SIGN,ADD_UPDATE); break; case "UPDATE": jsonObject.put(SIGN,ADD_UPDATE); break; case "DELETE": jsonObject.put(SIGN,DELETE); break; } String message = jsonObject.toJSONString(); producer.send(new ProducerRecord<>(topic,message)); log.error("----发送Kafka消息 ,topic-{},message-{}",topic,message); } } }
- 扩展canal操作
- 将jar包放入canal的lib目录下
- 配置文件修改
- conf/canal.properties新增配置属性
################################################## ####### Custom ################# ################################################## # 需要采集的数据表--带数据库名 ,使用英文逗号分隔 custom.async.mysql.db_table.list=douc.sys_group,douc.sys_group_user,douc.sys_user,douc.sys_department # 注意: 处理后的每个张表的数据发送往 prefix_table_suffix topic且增删改操作都处理为增,使用sign,version区分 custom.async.kafka.topic.prefix = mysql_ custom.async.kafka.topic.suffix = _topic
- conf/spring/file-instance.xml中注入扩展程序中的组件
<bean id="ReWrapperConfig" class="com.canal.config.ReWrapperConfig" init-method="init" destroy-method="destory"> <property name="sourceTopic" value="${canal.mq.topic}"/> <property name="kafkaServer" value="${kafka.bootstrap.servers}"/> <property name="mysqlDbTables" value="${custom.async.mysql.db_table.list}" /> <property name="topic_prefix" value="${custom.async.kafka.topic.prefix}" /> <property name="topic_suffix" value="${custom.async.kafka.topic.suffix}" /> </bean>
- conf/canal.properties新增配置属性
- 不足|缺点
未处理好与canal内嵌kafka依赖的关系,导致打出来的jar包比较大
- pom.xml
- 扩展思路二
--直接针对canal内嵌的KafkaProducer进行处理,将数据处理和数据分发功能在源码中处理
- 待续。。。
- 需求说明
- Canal源码编译安装(待续。。。)








 浙公网安备 33010602011771号
浙公网安备 33010602011771号