Gradio简易界面实现文生图+chatgpt(流式输出) webui界面
demo预览
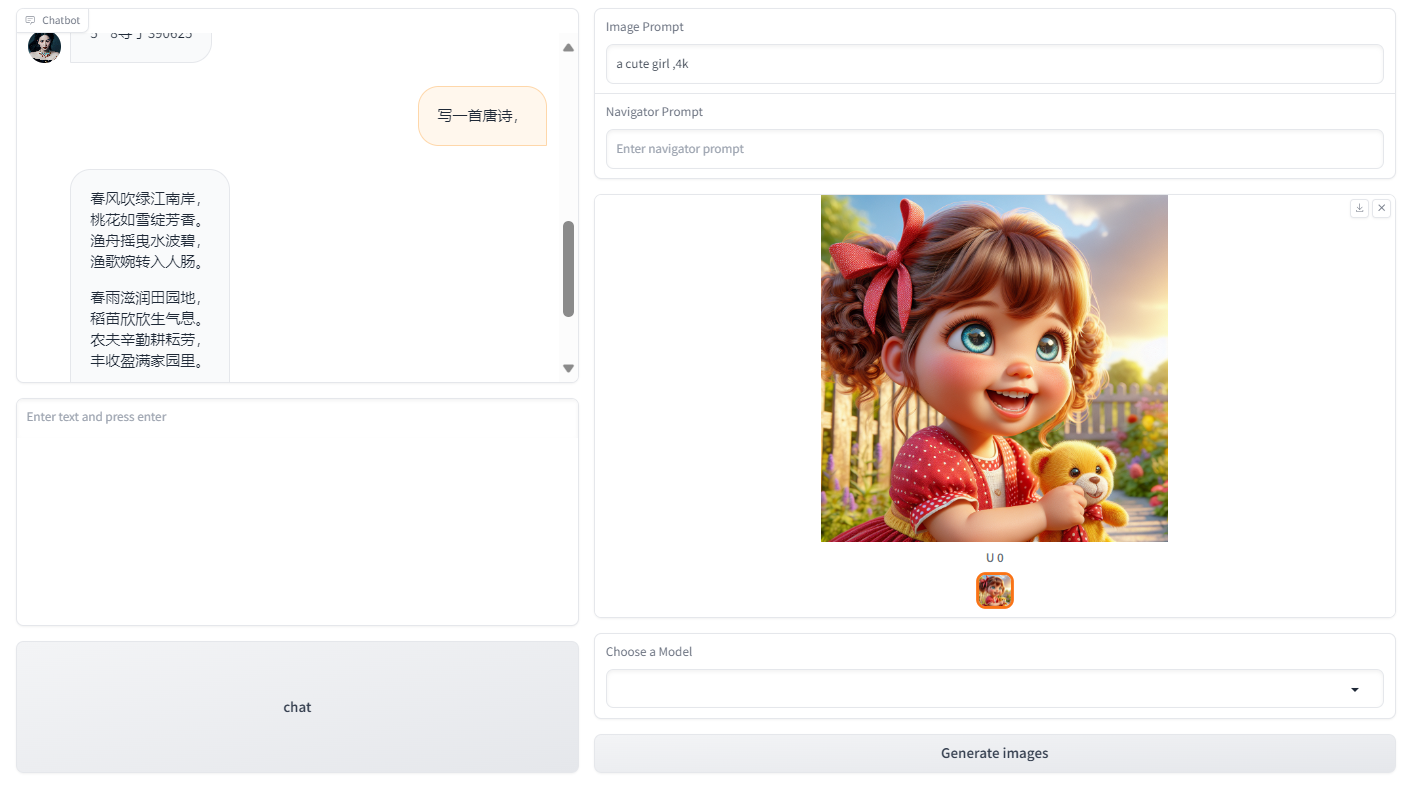
直接上code
import random
import gradio as gr
import os
import time
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
import requests
_ = load_dotenv(find_dotenv())
openai = OpenAI()
def fake_gan(prompt):
data['prompt'] = prompt
response = requests.post(url,headers=headers,json=data)
res = response.json()
images = [
(random.choice(res['result']['imageUrls']), f"U 0")
]
return images
def generate_images_with_prompts(prompt, navigator_prompt, model_choice):
return fake_gan(prompt)
def select_model(model_choice):
return fake_gan()
def add_text(history, text):
history = history + [(text, None)]
return history, gr.Textbox(value="", interactive=False)
def add_file(history, file):
history = history + [((file.name,), None)]
return history
def bot(history):
messages = [{"role": "user", "content": history[-1][0]}]
completion = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages,
stream=True,
temperature=0
)
history[-1][1] = ""
for chunk in completion:
for choice in chunk.choices:
content = choice.delta.content
if content:
history[-1][1] += content
time.sleep(0.05)
yield history
with gr.Blocks() as demo:
with gr.Row():
with gr.Column(scale=1, min_width=600):
chatbot = gr.Chatbot(
[],
elem_id="chatbot",
bubble_full_width=False,
avatar_images=(None, (os.path.join(os.path.dirname(__file__), "avatar.jpg"))),
)
txt = gr.Textbox(
scale=4,
show_label=False,
placeholder="Enter text and press enter",
container=False,
label="chat now",
)
commit_btn = gr.Button("chat",scale=2)
commit_btn.click(fn=add_text, inputs=[chatbot, txt], outputs=[chatbot, txt]).then(
bot, chatbot, chatbot, api_name="bot_response"
).then(lambda: gr.Textbox(interactive=True), None, [txt], queue=False)
txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=True).then(
bot, chatbot, chatbot, api_name="bot_response"
)
txt_msg.then(lambda: gr.Textbox(interactive=True), None, [txt], queue=False)
with gr.Column(scale=2, min_width=600):
prompt_input = gr.Textbox(placeholder="Enter prompt for image generation", label="Image Prompt")
navigator_prompt_input = gr.Textbox(placeholder="Enter navigator prompt", label="Navigator Prompt")
gallery = gr.Gallery(label="Generated images", show_label=False, elem_id="gallery", object_fit="contain",
height="auto")
model_select = gr.Dropdown(choices=["Model 1", "Model 2", "Model 3"], label="Choose a Model")
btn = gr.Button("Generate images")
btn.click(
generate_images_with_prompts,
[prompt_input, navigator_prompt_input, model_select],
gallery
)
demo.queue()
if __name__ == "__main__":
demo.launch()
需要自己配置下Openai的apikey 和 生产图片(api/stable diffussion)的那个路径即可


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)