垃圾回收机制/控制流程/分支结构/循环结构
今日内容详细
- 垃圾回收机制
- 流程控制理论/必备知识
- 分支结构
- 循环结构
- while 循环补充说明
- 控制流程之for循环(重点)
- range方法及实战
1.垃圾回收机制:
# 在一些编程语言中 内存的申请以及它的释放都需要程序员自己编写代码才可以实现
# 但是在Python中却不需要此操作,通过自带的垃圾回收机制帮助我们管理
垃圾回收机制分为三种:
1.引用计数:
例子:
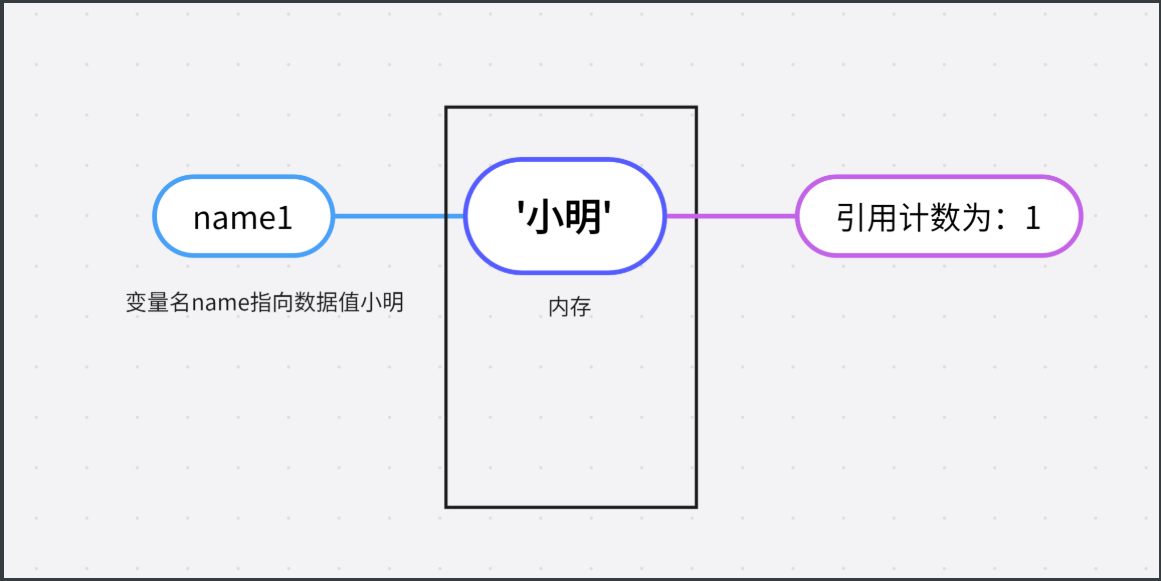
name = '小明' # 此时字符串小明已经绑定了变量名name,在内存中已经有了'小明'的位置 那么此时'小明'身上的引用计数为:1
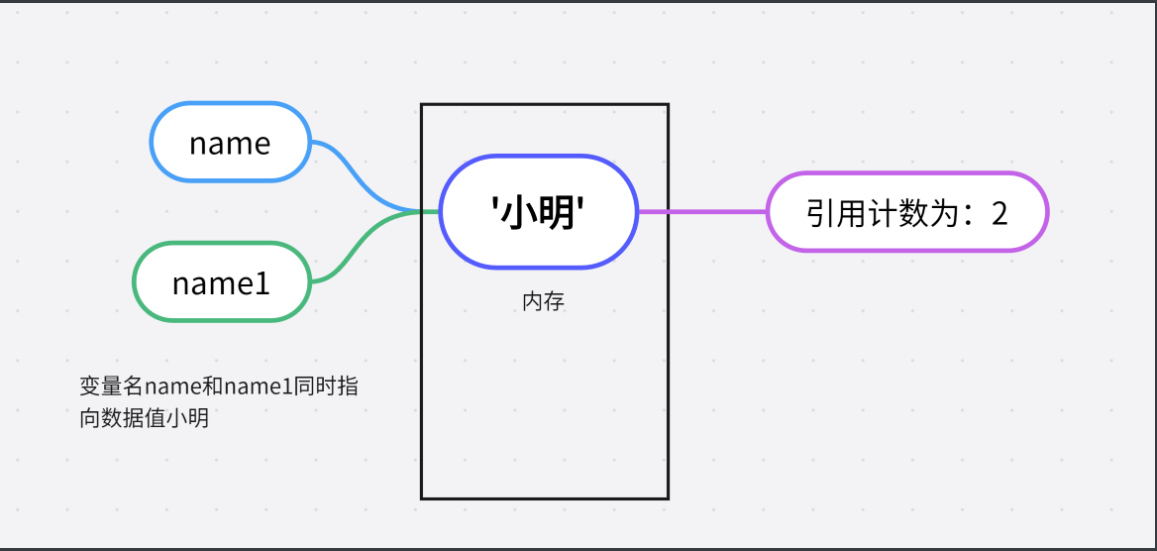
name1 = name # 此时name1 = name数据值'小明'身上的引用计数就为:2 因为 name1 与 name 变量名都指向数据值'小明'
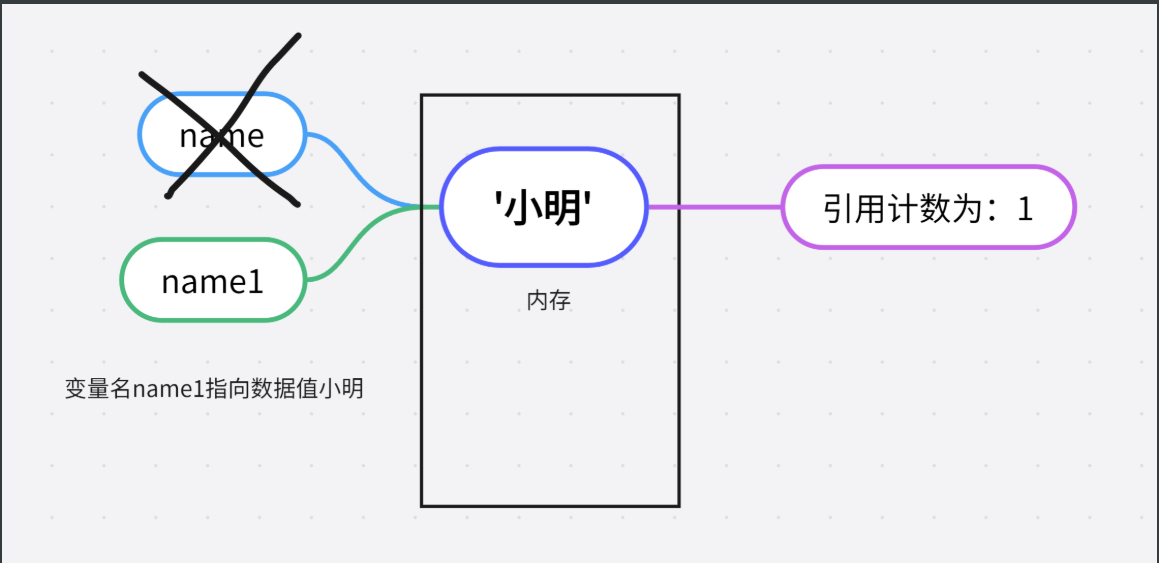
del name1 # 此时'小明'身上的引用计数就-1 为:1 del是删除的意思
由此垃圾回收机制的概念就显示出来了:
当数据值身上的引用计数为0时,就会被垃圾回收机制识别当作垃圾回收掉
当数据值身上的引用计数不为0时,就永远不会被垃圾机制回收掉
变量名指向数据值时,此时数据值引用计数为1
当两个变量名同时指向数据值时,此时数据值的引用计数为2
当del name 的时候,数据值的引用计数就会-1,但是只要它的引用计数不为零它就不会被识别为垃圾
2.标志清除
标志清除它主要针对与循环引用问题:
在此之前我们来介绍一下列表的方法: .append()
此方法是将()内的数据值添加到想要添加的地方
代码例子
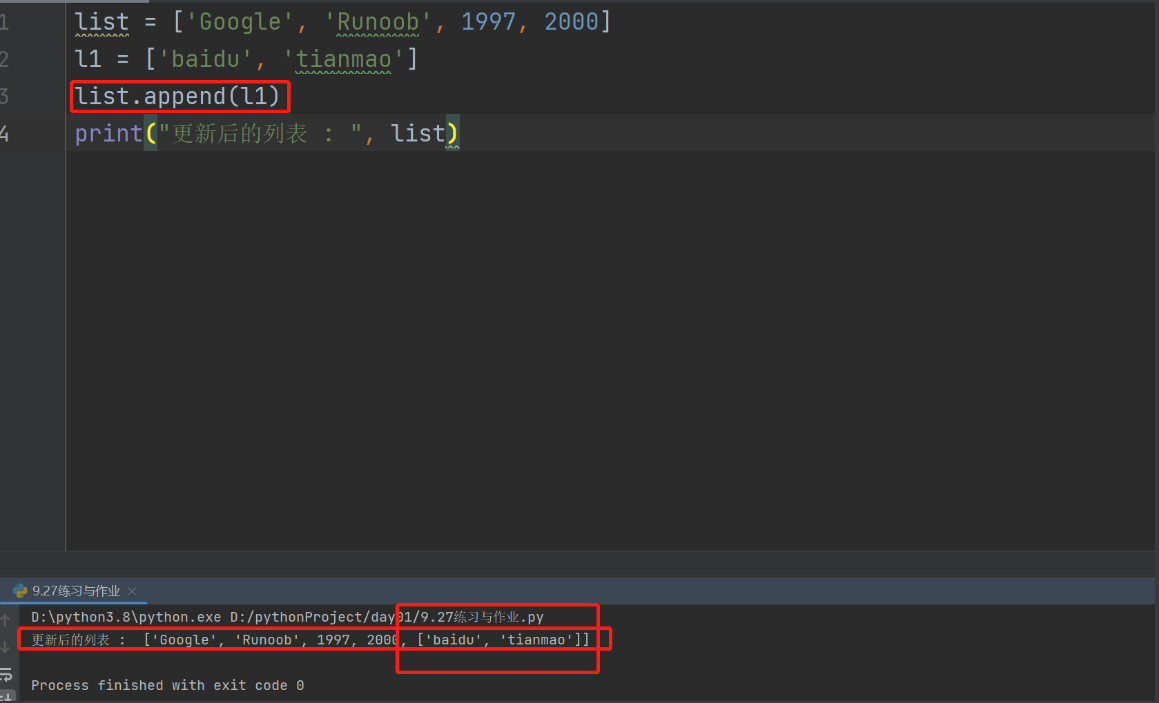
list = ['Google', 'Runoob', 1997, 2000]
l1 = ['baidu', 'tianmao']
list.append(l1)
print("更新后的列表 : ", list)
列表.apppend()方法 在列表中添加新的数据
# 我们回到标志清除部分:
例子:
l1 = [55,66] # 数据值引用计数为1
l2 = [77,88] # 数据值引用计数为1
l1.append(l2) # 此时 l1 = [55,66,[77,88]] 它的引用计数为:2
l2.append(l1) # 此时 l2 = [77,88,[55,66]] 它的引用计数为:2
del l1 # 断开变量名l1与列表的绑定关系 引用计数为1
del l2 # 断开变量名l2与列表的绑定关系 引用计数为1
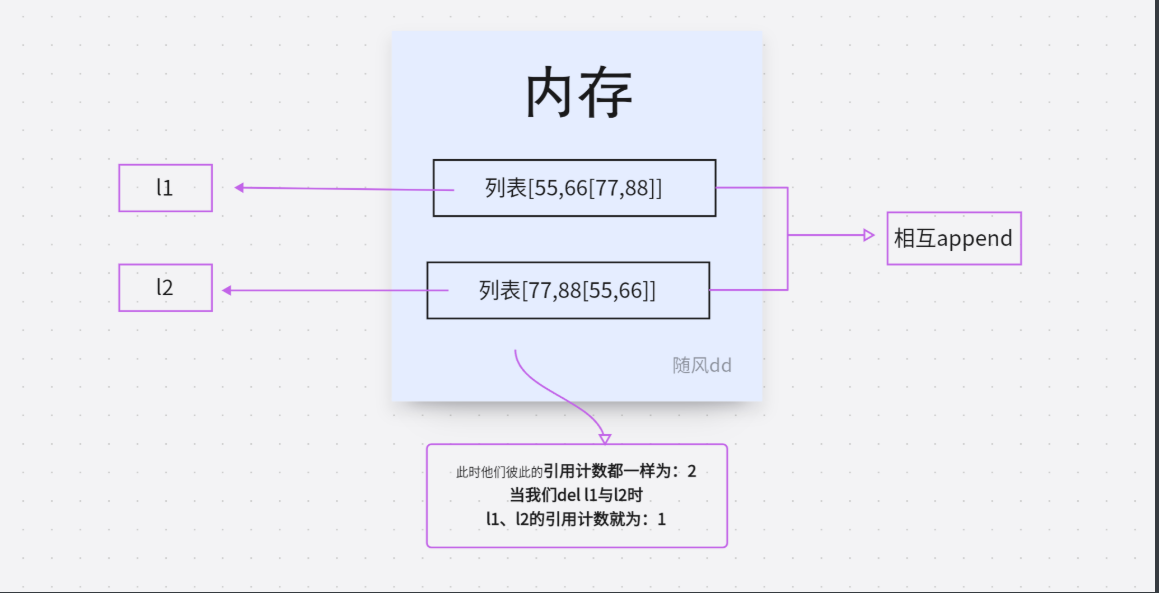
# 当内存占用达到临界值的时候 程序会自动停止 然后扫描程序中所有的数据
# 并给只产生循环引用的数据打上标记 之后一次性清除
3.分代回收:
垃圾回收机制的频繁运行也会损耗各项资源
它会将数据进行分类
如果变量名出现的频率占比很高,那么检测频率就低一些
如果变量名出现的频率占比中等,那么检测频率就变得中等
如果变量名出现的频率很低,那么检测频率就很高
差图片
2.流程控制理论
流程控制就是控制事物的执行流程
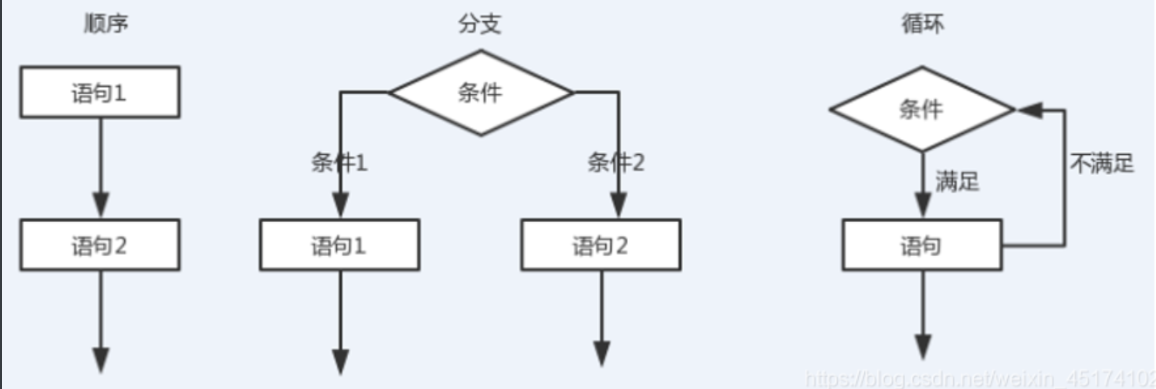
事物执行流程可以分为三种:
1.顺序结构:从上往下一行一行依次执行
2.分支结构:在从上往下的某一点,根据不同的条件做出不同的执行策略
3.循环结构:事物的执行会根据某个条件重复执行
# 我们在日后的代码世界中 很多时候可能会出现三者混合的情况
控制流程必备知识点:
1.python中使用缩进(空格)来表示代码的从属关系
从属关系:缩进的代码(子代码)是否执行取决于上层是否有缩进
2.并不是所有代码都可以拥有子代码:
可以拥有子代码的: if while else (待添加)
3.如果有多行子代码属于同一个父代码,那么这些子代码需要保证有相同的缩进量
4.python中针对缩进量没有具体的要求 但是推荐使用四个空格(windows中可以直接用tab键)
5.当某一行代码需要编写子代码的时候 那么这一行代码的结尾肯定需要冒号
6.相同缩进量的代码彼此之间平起平坐 按照顺序结构依次执行
3.分支结构
- 单if 分支结构
- if else 分支结构
- if elif else 分支结构
- if 嵌套
1.单if分支结构
if 条件
条件成立后执行代码块
例:
username = input('请输入用户名:')
if username == 'bot':
print('老师好')
print('结束程序')
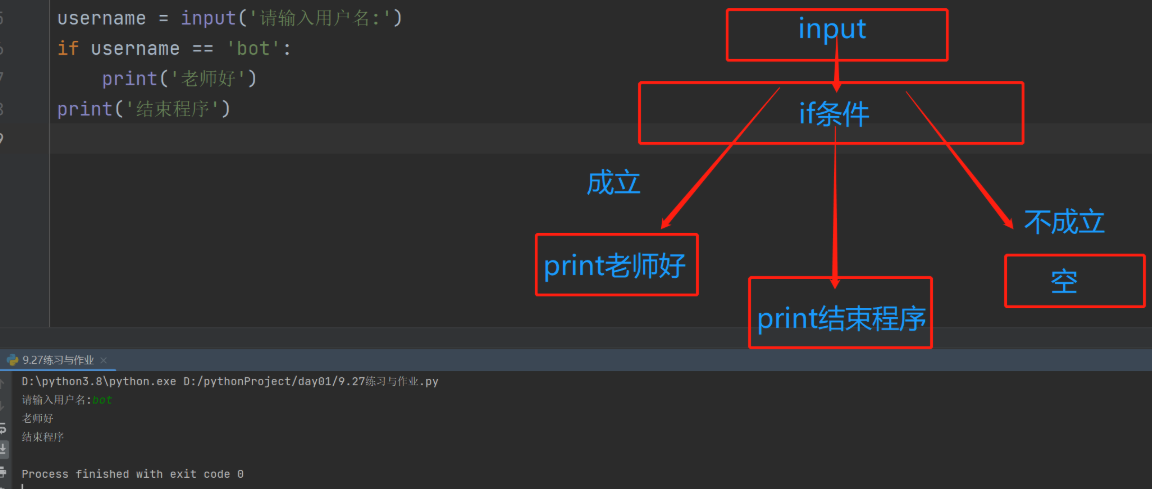
if 条件执行流程

2.if else 分支结构
if 条件:
条件成立后执行子代码
else:
条件不成立后执行子代码
例:
username = input('请输入用户名:')
if username == 'bot':
print('老师好')
else:
print('输入错误')
print('结束程序')
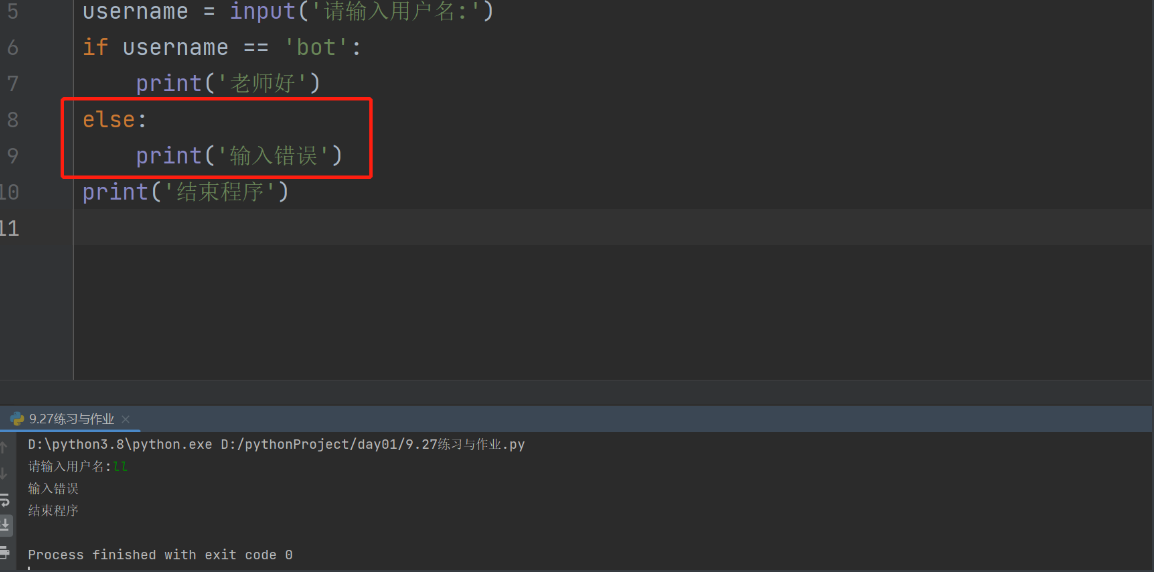
3.if elif else 分支结构:
if 条件1:
条件成立后执行子代码
elif 条件2:
条件成立后执行子代码(前提是条件1不成立)
elif 条件3:
条件成立后执行子代码(前提是条件1、2都不成立)
else:
上述条件不成立后执行子代码
# 如果其中有一个条件成立,那么就会往下运行,不会再与其他同级条件做判断。
例:
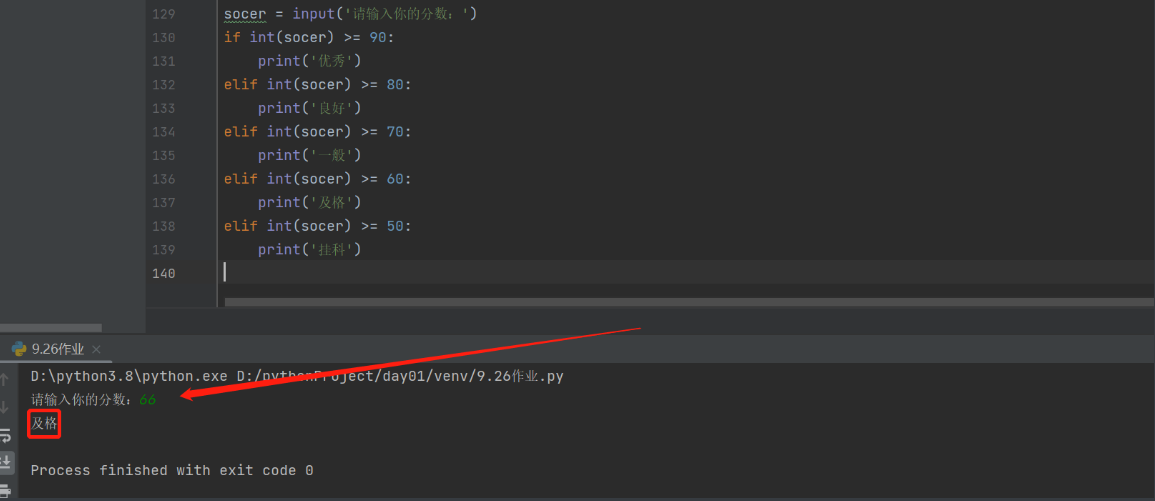
socer = input('请输入你的分数:')
# if int(socer) >= 90:
# print('优秀')
# elif int(socer) >= 80:
# print('良好')
# elif int(socer) >= 70:
# print('一般')
# elif int(socer) >= 60:
# print('及格')
# elif int(socer) >= 50:
# else:
# print('挂科')
int() 可以把input()获取到的字符串类型转换为整型(前提是数字)
顺序、分支、循环结构 图解
if 嵌套
if 嵌套就是if 下套 if 会有多种分支 根据条件的不同 做不同的判断,也会有不同的结果
例:
age = 28
height = 170
weight = 110
is_beautiful = True
is_success = False
username = 'tony'
if username == 'tony':
print('tony发现目标')
if age < 30 and height > 160 and weight < 150 and is_beautiful:
print('大妹纸 手机掏出来 让我加微信')
if is_success:
print('吃饭 看电影 天黑了...')
else:
print('去你妹的 流氓!!!')
else:
print('不好意思 认错人了')
else:
print('不是tony做不出来这件事')
4.循环结构
我们如果想让一些代码反复的执行可以用到:
while 条件:
条件成立之后执行子代码(循环体代码)
1.先判断条件是否成立
2.如果成立则执行循环体代码
3.循环体代码执行完毕后返回到条件判断处 判断调教是否成立
4.如果成立 则继续执行循环体代码
5.按照上述规律依次继续执行 直到条件不成立才会结束循环体代码的执行
while + else 结构
while 条件:
循环体代码
else:
循环体代码没有被强制结束的情况下 执行完毕就会执行else子代码
我在循环前面添加了一个变量 在打印后边添加一个变量+1的语句 这样在循环运行到3次时候就不满足条件了 不会一直运行下去
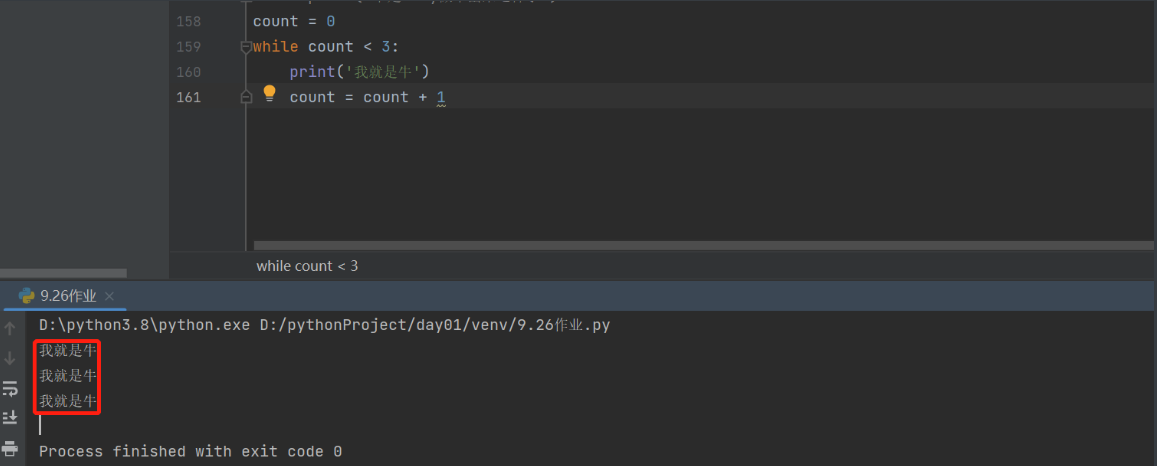
break # 强行结束循环体
while循环体代码一旦执行到break会直接结束循环
continue # 直接跳到条件判断处
while循环体代码一旦执行到continue会结束本次循环 开始下一次循环
5.while 循环补充说明
while 循环
1. 死循环 真正的死循环是一旦执行,会让cpu的占用率特变高,直到系统采取措施
我们学了for循环后 尽量就不要使用死循环了
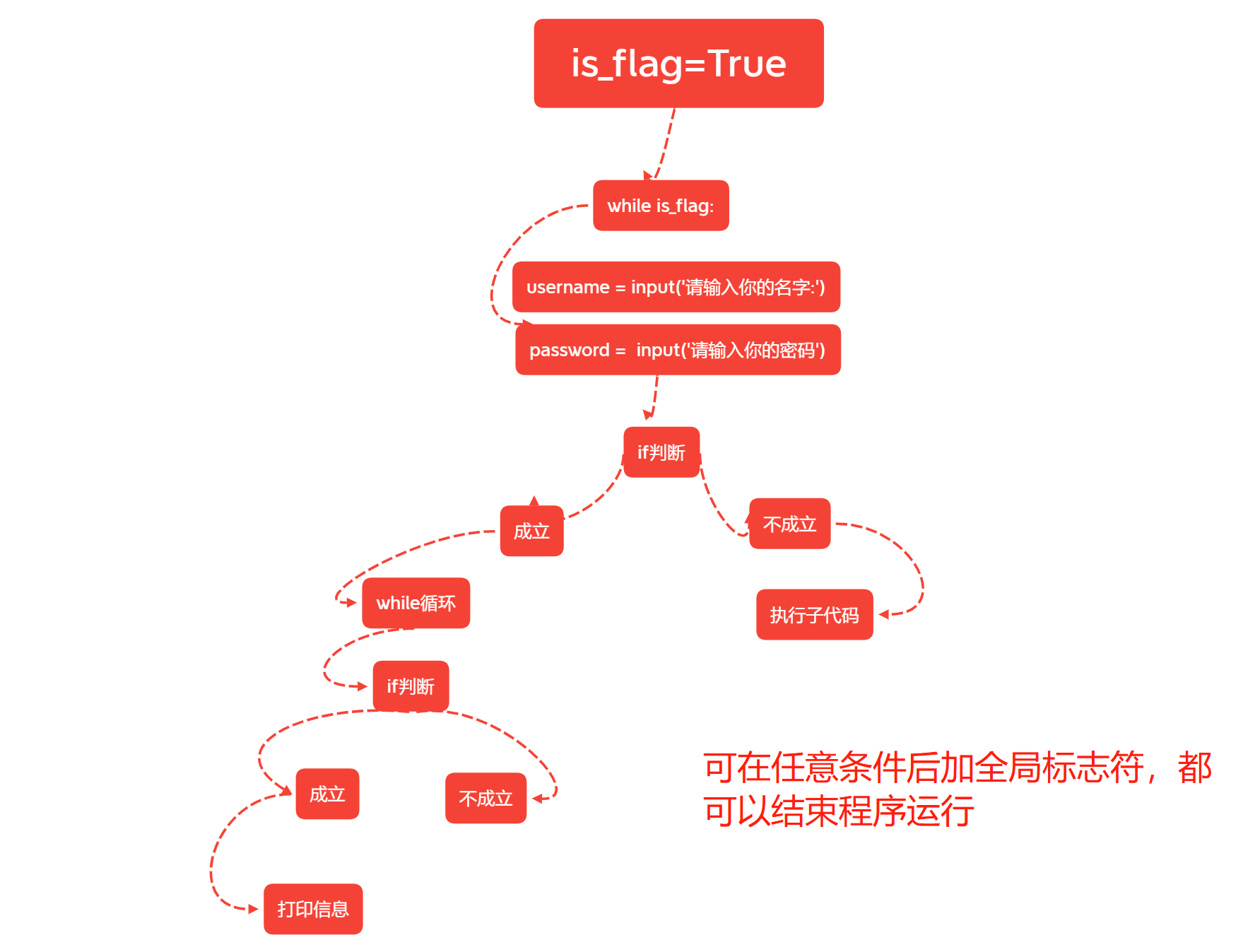
2.嵌套以及全局标志符:
break只能结束它在当前的那一层循环,与其他循环不发生关系
有几个while的嵌套,想要一次性结束的话就需要使用几个break
如果不想重复写break的话就需要使用全局标识符
is_flag = True
while is_flag:
username = input('username>>>:')
password = input('password>>>:')
if username == 'jason' and password == '123':
while is_flag:
cmd = input('请输入您的指令>>>:')
if cmd == 'q':
is_flag = False
print('正在执行您的指令:%s' % cmd)
else:
print('用户名或密码错误')
6.流程控制之for循环(重点)
for 循环 能够做到的事情,while循环也可以做到,但是再一些应用场景下面,for循环更加的简单一些。
for 循环主要用于获取存储多个数据值的数据内部数据值
for循环语法结构为:
for 变量名 in 数据值:
for 循环体代码
例:
l1 = [11,22,33,44,55]
for i in l1:
print(i) # 输出结果为 11,22,33,44,55
在这个for循环中,当他遍历了l1列表中的数据值时,i这个变量名会分别 先绑定到l1列表中的11,然后再绑定22,然后再绑定33,再绑定44....一直到没有能绑定的数据值,结束循环。
# 那么由此我们可以看到它的特点
1.for 循环它擅长遍历取值
2.不需要结束条件 在遍历完成后自动停止
它比while的好处就在于 while可能一不小心写成了死循环,但是for循环不会
for循环它主要遍历的常见数据类型有(字符串、列表、元组、字典、集合)
列表:
name = ['jason','tony','bob','jerry']
for i in name:
print(i) # 输出结果为jason tony bob jerry
字典:
name = {'jason':18, 'tony':55,'sam':666}
for i in name:
print(i) # 它的输出结果为 jason tony sam
for循环在取字典时,只跟键发生关系,不跟值发生关系
字符串:
name = 'jason'
for i in name:
print(i) # 它的输出结果为 j a s o n
字符串中单个字符也是数据值,所以会单独取单个字符
for循环变量名命名建议:
1.见名知意
2.如果遍历出来的数据没有特别具体的含义,可以用单个字母命名
如 i k v c...
# for 循环体代码如果执行到break 那么也会直接结束整个for循环
# for 循环体代码如果执行到continue 那么会结束当前循环,直接开始下次循环
break例:
name = [11, 22, 33, 555, 44]
for i in name:
if i == 33: # 添加一个条件判断,当条件成立的时候执行下面的代码 break 它会直接停止整个循环
break
print(i) # 结果为 11 22
continue例:
name = [11, 22, 33, 555, 44]
for i in name:
if i == 33:
continue
print(i) # 结果为: 11 22 555 44
# 添加一个条件判断,当条件成立的时候执行下面的代码 continue 它会直接停止当前的循环,直接开始下次循环
for 与 else 也可以一起使用
for 变量名 in 数据值:
执行for循环体代码
else:
如果循环体代码没有因为break强制结束的情况下运行完毕后,运行else的子代码
7.range方法及实战
range 我们可以理解为:帮我们产生一个内部含有多个数字的数据
主要用法:
for i in range(1,14):
print(i) # 打印数字1-13
# 我们的(1,14)就是给range 定位一个范围,让他在1-14这个范围取值并依次打印出来
for i in range(50)
print(i) # 打印数字0-50 它的其实位置没有定的话就默认为0开始,输入的数值-1结尾
for i in range(1, 20, 2):
# 第三个数为等差值 默认不写为1 它代表是打印出的第一个数字减去第二个为2 一直如此,直到结束
print(i)
穿插知识点:
在python2中 range 有两种
1. range()
直接生成一个列表内部有多个数据值
2.xrange()
如果你需要其中的数据值就会产出,如不需要它就暂时存储
python3中:
range()方法 = python2 中的 xrange()方法
接下来我们进入range方法的实战项目:
我们现在还没有学到爬虫部门,我们先理解一下它大体的逻辑部分
目的:使用代码爬取我们在网上所需要的数据
需求:爬取当前网站所有页面数据
我们可以先去某网站(豆瓣)看一下它的规律
首页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第四页:https://movie.douban.com/top250?start=75&filter=
....
共 10 页
我们需要通过代码先获取这250页的网页地址
我们就可以用到range方法获取
例:
# 我们知道每个页面和每个页面的等差值为25,那么一共250页我们就可计算出来它的值的范围
count = (25*10)
# 通过占位符 先写好模板准备替换关键数据
data = 'https://movie.douban.com/top250?start=%s&filter='
for i in range(0, count, 25): # 进入循环
print(data % i) # 输出数据内容
'''
分页的规律 不同的网址有所区别
1.在网址里面有规律
2.内部js文件动态加载
'''
8.练习题及答案:
1.根据用户输入内容打印其权限
'''
jason --> 超级管理员
tom --> 普通管理员
jack,rain --> 业务主管
其他 --> 普通用户
'''
job = input('请输入您的名字:')
if job == 'jason':
print('超级管理员')
elif job == 'tom':
print('普通管理员')
elif job == 'jack' and 'rain':
print('业务主管')
else:
print('普通用户')
2.编写用户登录程序
要求:有用户黑名单 如果用户名在黑名单内 则拒绝登录
eg:black_user_list = ['jason','kevin','tony']
如果用户名是黑名单以外的用户则允许登录(判断用户名和密码>>>:自定义)
eg: oscar 123
black_user_list = ['jason', 'kevin', 'tony']
name = input('请输入用户名:')
password = 123
pwd = input('请输入密码:')
if name in black_user_list:
print('您已经被拉黑')
elif int(pwd) == 123:
print('登录成功')
elif int(pwd) != 123:
print('密码输入错误')
3.编写用户登录程序
用户如果登录失败 则只能尝试三次
用户如果登录成功 则直接结束程序
4.猜年龄的游戏
假设用户的真实年龄是18 编写一个猜年龄的游戏 获取用户猜测的年龄
基本要求:可以无限制猜测 每次猜错给出提示(猜大了 猜小了) 猜对则结束程序
拔高练习:每次猜测只有三次机会 一旦用完则提示用户是否继续尝试 用户通过输入n或者y来表示是否继续尝试 如果是y则继续给用户三次猜测机会 否则结束程序
基本要求:
while True:
age = 18
choice = input('请输入您要猜测的年龄:')
choice1 = int(choice)
if choice1 < 18:
print('猜小了')
elif choice1 > 18:
print('猜大了')
elif choice1 == 18:
print('猜对了')
break
拔高练习:
count = 0
while count < 4:
age = 18
choice = input('请输入您要猜的年龄:')
choice1 = int(choice)
if choice1 == 18:
print('猜对了')
break
elif choice1 < 18:
print('猜小了')
count += 1
print('输入错误还剩%s次机会' % (3 - count))
elif choice1 > 18:
print('猜大了')
count += 1
print('输入错误还剩%s次机会' % (3 - count))
if (3-count) == 0:
choice2 = input('您的机会已经用完了,是由要继续? 输入y继续n退出')
if choice2 == 'y':
count = 0
continue
elif choice2 == 'n':
print('退出程序')
break
1.计算1-100所有的数之和
count = 0
for i in range(0, 101):
count = count + i
print(count)
2.l1 = [11,2,3,2,2,1,2,1,2,3,2,3,2,3,4,3,2,3,2,2,2,2,3,2]
判断列表中数字2出现的次数
l1 = [11, 2, 3, 2, 2, 1, 2, 1, 2, 3, 2, 3, 2, 3, 4, 3, 2, 3, 2, 2, 2, 2, 3, 2]
count = 0 # 定义一个计数器
for i in l1: # 遍历l1列表
if i == 2: # 增加条件判断
count += 1 # 如果等于2 那么count 加1
print('2出现的次数为%s' % count) 最后打印结果
3.
编写代码自动生成所有页网址(注意总共多少页)
https://movie.douban.com/top250
# 我们知道每个页面和每个页面的等差值为25,那么一共250页我们就可计算出来它的值的范围
count = (25*250)
# 通过占位符 先写好模板准备替换关键数据
data = 'https://movie.douban.com/top250?start=%s&filter='
for i in range(0, count, 25): # 进入循环
print(data % i) # 输出数据内容
4.编写代码打印出下列图形(ps:for循环嵌套)
*****
*****
*****
*****
for i in range(4): # 先做四次的列 用*号打印出来
for b in range(5): # 在做 5次的行 用 end='' 方法把换行符删除
print('*',end='')
print('*')
