python抓取在线m3u8视频实例
简单实现,未做伪装,未深度优化,仅供参考
基本步骤:
1. 准备好视频m3u8文件地址列表
使用F12记录视频m3u8文件请求地址
2. requests下载m3u8文件
r = requests.get(url) with open (file_path, 'wb') as f: f.write(r.content) f.close()
3. 读取m3u8文件内容,拼凑ts片段地址
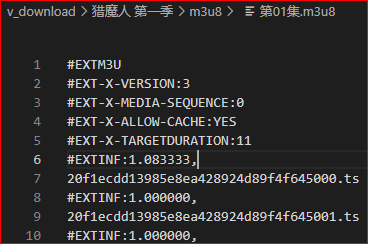
用文件内ts文件地址替换m3u8文件下载地址
1 m3u8_file_url = "https://xxx.com/xxx/xxx/xxx.m3u8" 2 f = open(m3u8_file_path,mode="r",encoding='UTF-8') 3 lines = f.read(os.path.getsize(file_path)).splitlines() 4 f.close() 5 for line in lines: 6 if not line.startswith("#"): 7 index = m3u8_file_url.rfind("/")+1 8 all_ts_path_list.append(m3u8_file_url[:index] + line)
4. requests下载拼凑好的ts文件
5. 调用cmd合并ts
copy /b "xx:/xx/xx_*.ts" "xx:/xx/yy.mp4"
示例代码
实现查找,自动下载整季剧集功能


1 import requests,os,pickle,urllib,sys,_thread,warnings 2 from bs4 import BeautifulSoup 3 warnings.filterwarnings('ignore') 4 5 data = {'wd': ''} 6 thread_num = 10 # 下载线程数 7 8 base_download_path = "v_download/" 9 base_url = "https://m.pangzitv.com" 10 proxies={'https':'127.0.0.1:10809'} 11 all_ts_path_list = [] 12 download_tmp = None 13 status = -1 14 download_file_path = "vdt/{}.vdt" 15 thread_ok = 0 16 17 def download_file(url,filename,parent_name = ''): 18 try: 19 r = requests.get(url,verify=False,proxies=proxies) 20 path_prev = base_download_path + data["wd"] + "/" + parent_name 21 if not os.path.exists(path_prev): 22 try: os.makedirs(path_prev) 23 except : pass 24 with open (path_prev + filename, 'wb') as f2: 25 f2.write(r.content) 26 f2.close() 27 except: 28 print(path_prev + filename + "失败!") 29 30 def go(name_prev): 31 global thread_ok 32 while len(all_ts_path_list) > 0: 33 url = all_ts_path_list.pop() 34 # 查找集数 35 download_file(url,name_prev +"_" + url[-7:],"ts/") 36 thread_ok += 1 37 38 def start_download_thread(name_prev): 39 i = 0 40 while i < thread_num: 41 _thread.start_new_thread(go,(name_prev,)) 42 i += 1 43 44 def save_tmp(): 45 if not os.path.exists("vdt") : os.makedirs("vdt") 46 f = open(vdt_file_path,mode='wb') 47 pickle.dump(download_tmp,f) 48 f.close() 49 50 while True: 51 print("输入查询内容:") 52 search_str = input() 53 # 查找缓存文件 54 data["wd"] = search_str 55 print("查询中...") 56 res = requests.post(base_url + "/index.php?m=vod-search", data,proxies=proxies) 57 bf = BeautifulSoup(res.content.decode('utf-8')) 58 search_res = bf.find_all("div",{"class":"list_info"}) 59 video_url = None 60 search_res_list = [] 61 if len(search_res) > 0: 62 # 整理提示文字 63 for sr in search_res: 64 search_res_list.append({ 65 "name":sr.find("a").text.replace("/","@").replace(":","-"),"loc":sr.find_all("p")[0].text, 66 "type":sr.find_all("p")[1].text,"href":sr.find("a").attrs['href']}) 67 # 展示搜索结果 68 index = 1 69 print("查询结果:") 70 for sr in search_res_list: 71 print("{}. {} - {} - {}".format(index,sr["name"],sr["loc"],sr["type"])) 72 index+=1 73 while True: 74 print("输入序号选择(0:退出重新搜索):") 75 try: 76 select_index = int(input()) - 1 77 except: 78 print("输入数字!") 79 continue 80 if select_index == -1: break 81 if len(search_res_list) - 1 < select_index or select_index < 0: 82 print("超范围") 83 else: 84 select_res = search_res_list[select_index] 85 data["wd"] = select_res['name'] 86 break 87 if select_index != -1: 88 # 查缓存 89 vdt_file_path = download_file_path.format(select_res['name']) 90 if os.path.exists(vdt_file_path): 91 f = open(vdt_file_path,mode='rb') 92 download_tmp = pickle.load(f) 93 f.close() 94 status = 0 95 if download_tmp: 96 # 0:保存了起始url 1:已保存播放集数m3u8列表 2:m3u8文件已下载 3:已经开始下载(d_nums[]为已经下载的集号) 97 status = download_tmp["status"] 98 else: 99 download_tmp = {} 100 101 # 起始位置 102 video_start_url = base_url + select_res['href'] 103 download_tmp['name'] = select_res['name'] 104 download_tmp['start_url'] = video_start_url 105 save_tmp() 106 break 107 else: 108 print("没有查询结果") 109 110 if status == 0: 111 # 获取保存播放集数列表 112 res = requests.get(download_tmp['start_url'],proxies=proxies) 113 bf = BeautifulSoup(res.content.decode('utf-8')) 114 text = bf.find_all("script")[6].text 115 url_start_index = text.find("unescape(") 116 url_end_index = text.find("');") 117 text = text[url_start_index+10 : url_end_index].replace("%23","#").replace("%2F",'/').replace("%3A",':').replace("%24",'$').replace("‘","") 118 result = eval(repr(text).replace("%",'\\')) 119 v_list = urllib.parse.unquote(result).split("#") 120 download_tmp['m3u8'] = {} 121 status = 1 122 download_tmp['status'] = status 123 download_tmp["d_nums"] = [] 124 for v in v_list: 125 v_split = v.split("$") 126 download_tmp['m3u8'][v_split[0]] = v_split[1] 127 # 保存完毕m3u8地址 128 save_tmp() 129 130 if status == 1: 131 # 下载m3u8 132 print("开始下载分集m3u8") 133 for v_num in download_tmp['m3u8']: 134 v_url = download_tmp['m3u8'][v_num] 135 filename = v_num + ".m3u8" 136 download_file(v_url, filename,"m3u8/") 137 print(filename) 138 status = 2 139 download_tmp['status'] = status 140 print("分集m3u8下载完成") 141 save_tmp() 142 143 if status == 2: 144 # 读取m3u8文件 145 for v_num in download_tmp['m3u8']: 146 v_url = download_tmp['m3u8'][v_num] 147 if v_num in download_tmp["d_nums"]: 148 continue 149 else: 150 # 开始下载 151 file_path = base_download_path + data["wd"] + "/m3u8/" + v_num + ".m3u8" 152 f = open(file_path,mode="r",encoding='UTF-8') 153 lines = f.read(os.path.getsize(file_path)).splitlines() 154 f.close() 155 for line in lines: 156 if line.startswith("#"): continue 157 else: all_ts_path_list.append(v_url[:v_url.rfind("/")+1] + line) 158 print("开始下载" + v_num) 159 start_download_thread(v_num) 160 while thread_ok != thread_num: pass 161 thread_ok = 0 162 download_tmp["d_nums"].append(v_num) 163 # 合并 164 cur_path = sys.argv[0][:sys.argv[0].rfind("\\") + 1] 165 ts_dir = cur_path + (base_download_path + data["wd"] + "/ts/").replace("/","\\") 166 out_dir = cur_path + (base_download_path + data["wd"] + "/video/").replace("/","\\") 167 168 if not os.path.exists(out_dir): os.makedirs(out_dir) 169 os.system('copy /b "{}{}_*.ts" "{}{}.mp4"'.format(ts_dir,v_num,out_dir,v_num)) 170 # 清理 171 os.system('del /Q "{}*.*"'.format(ts_dir)) 172 print(v_num + "下载结束") 173 save_tmp() 174 print("该剧下载结束")
截图
交互式查询,下载

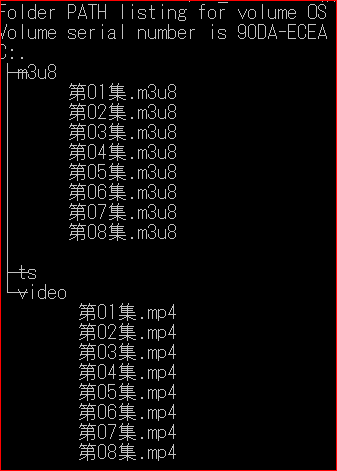
第一季下载完成后目录结构,ts目录即时清理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号