脉冲星PRESTO部署文档
高性能计算实战——PRESTO
概述
PRESTO 是一套大型脉冲星搜索和分析软件,PRESTO 已经发现了 1000 多颗脉冲星,其中包括大约 400 颗回收的
双脉冲星。
预备知识
部分名词解释
对文档中部分名词简要说明,如需要深入了解可查阅《计算机网络:自顶向下方法》、《计算机组成与设计:硬件/软件接口》等相关书籍。
- 节点:一台服务器。
- CPU:中央处理器(central processing unit,简称CPU)作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。
- GPU:图形处理器(graphics processing unit,缩写:GPU),又称显示核心、视觉处理器,是一种做图像和图形相关运算工作的微处理器。
- 多核CPU:多核处理器是指在一枚处理器中集成两个或多个完整的计算引擎(内核)。
- Infiniband:(直译为“无限带宽”技术,缩写为IB)是一个用于高性能计算的计算机网络通信标准,它具有极高的吞吐量和极低的延迟,用于计算机与计算机之间的数据互连。
- 带外管理网络:通过独立于数据网络之外专用管理通道进行管理。
部分基本命令解释
对文档中使用的一些命令简要说明,如需要详细了解可参照《LINUX命令行与SHELL脚本编程大全》等相关书籍。
tar可以解压特定格式的文件wget一个从网络上下载文件的工具cd切换工作目录make是一条计算机指令,是在安装有GNU Make的计算机上的可执行指令。该指令是读入一个名为makefile的文件,然后执行这个文件中指定的指令。使用make命令可以在不知道构建细节的情况下构建和安装软件,因为这些细节都记录在了makefile中ls显示文件夹内容gitGit 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。使用git clone可以拷贝一个项目到本地
软件及工具的简要说明
对于需要使用的软件简要介绍,但并不面面俱到,需要全面的了解可以查阅更多相关资料。
操作系统CentOS
CentOS是免费的、开源的、可以重新分发的开源操作系统是Linux发行版之一。官方网站
作业调度软件Slurm
SLURM 是一种可用于大型计算节点集群的高度可伸缩和容错的集群管理器和作业调度系统。SLURM 维护着一个待处理工作的队列并管理此工作的整体资源利用。
Slurm作业调度系统还有更为丰富的功能,如有需要可以参考相关使用手册。例如中国科大超级计算中心的Slurm作业调度系统使用指南,这里通过样例介绍一些基本使用方法。
编写作业提交脚本
使用 Slurm 时需要编辑已给作业调度提交脚本,一个基本的示例如下
#!/bin/bash
#SBATCH -J test # 作业名是 test
#SBATCH -p cpu-low # 提交到 cpu-low 分区
#SBATCH -N 1 # 使用一个节点
#SBATCH -n 1 # 使用一个进程(cpu 核)
#SBATCH -t 5:00 # 任务最大运行时间是 5 分钟
#SBATCH -o test.out # 将屏幕的输出结果保存到当前文件夹的 test.out
#SBATCH -e test.err # 将屏幕的输出结果保存到当前文件夹的 test.err
./helloworld # 执行我的 ./helloworld 程序
脚本的第一行指定了这个脚本的解释器为bash。每次编写脚本都必须写上这一行。之后有#开头的若干行表示SLURM作业的设置区域,它告诉工作站运行任务的详细设定,它被提交到cpu-low分区当中,申请1个节点的1个核心,限制任务最大运行时间是五分钟,将标准输出放在test.out中,标准错误输出放在test.err中。 它的主体内容就是在当前目录执行程序helloworld。
关于分区的类型,可以先使用 sinfo 查看可用资源情况(服务队列)。
[test@ln01 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpu-low up infinite 260 idle compute-[001-260]
cpu-low up infinite 260 idle compute-[001-260]
cpu-high up infinite 260 idle compute-[001-260]
cpu-quota up infinite 260 idle compute-[001-260]
gpu-low up infinite 10 idle gpu-[01-10]
gpu-normal up infinite 10 idle gpu-[01-10]
gpu-high up infinite 10 idle gpu-[01-10]
gpu-quota up infinite 10 idle gpu-[01-10]
其中 PARTITION 表示分区,NODES 表示结点数,NODELIST 为结点列表,STATE 表示结点运行状态。
提交作业
准备好 SLURM 脚本之后,可以使用 sbatch 提交作业:
[test@ln01 ~]$ sbatch run.slurm
Submitted batch job 85
[test@ln01 ~]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
85 cpu-low test test R 0:13 1 compute-001
在上面的输出中,sbatch 返回的信息是 “Submitted batch job 85”,这表示作业成功提交,作业号是 85。而 squeue 显示我提交的作业的具体信息,在这里看到作业被放到cpu-low 分区上运行,占用 1 个节点 comput-001,状态(ST)是运行状态(R),并且已经运行了 13秒钟。
Anaconda
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda包括Conda、Python以及许多安装好的工具包。
conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换。关于其中更多命令和使用方法可以在官网查询
Python
Python is a programming language that lets you work quickly and integrate systems more effectively
Python提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容。用Python开发,许多功能不必从零编写,直接使用现成的即可。
除了内置的库外,Python还有大量的第三方库。安装第三方库,可以使用pip。工程中有Python代码,所以需要相关Python环境的支持。关于Python的使用,在官方网站中选择Docs一栏查看不同版本的手册。
FFTW
FFTW ( the Faster Fourier Transform in the West) 是一个快速计算离散傅里叶变换的标准C语言程序集,其由MIT的M.Frigo 和S. Johnson 开发。可计算一维或多维实和复数据以及任意规模的离散傅里叶变换。FFTW 受到越来越多的科学研究和工程计算工作者的普遍青睐,并为量子物理、光谱分析、音视频流信号处理、石油勘探、地震预报、天气预报、概率论、编码理论、医学断层诊断等领域提供切实可行的大规模 FFT 计算。
PGPLOT
PGPLOT是一个不依赖于任何装置的数据绘图函式库。他是由加州理工学院的Tim Pearson从1983开始编写。对于大多数应用程序,程序可以独立于设备,并且可以在运行时将输出定向到适当的设备。
TEMPO
Tempo 是一个用于脉冲星计时数据分析的程序。
CFITSIO
CFITSIO 是一个独立于机器的例程库,用于读取和写入 FITS(灵活图像传输系统)数据格式的数据文件。它还可以通过将 IRAF 格式图像文件和原始二进制数据数组动态转换为虚拟 FITS 格式文件来读取它们。这个库是用 ANSI C 编写的,用于访问将在最常用的计算机和工作站上运行的 FITS 文件。CFITSIO 支持 FITS 格式官方定义中描述的所有功能,可以读写所有当前定义的扩展类型,包括 ASCII 表(TABLE)、二进制表(BINTABLE)和 IMAGE 扩展。
CFITSIO 还包含一组 Fortran 可调用包装例程,允许 Fortran 程序调用 CFITSIO 例程。
CFITSIO 软件包最初由 NASA 戈达德太空飞行中心的 HEASARC(高能天体物理学科学档案研究中心)开发,用于将各种现有和新获取的天文数据集转换为 FITS 格式,并进一步分析已经采用 FITS 格式的数据。
openmp
OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。官方网站
对基于数据分集的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以较容易的适应不同的并行系统配置。线程粒度和负载平衡等是传统多线程程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了部分这两方面的工作。但是,作为高层抽象,OpenMP并不适合需要复杂的线程间同步和互斥的场合。OpenMp的另一个缺点是不能在非共享内存系统(如计算机集群)上使用。在这样的系统上,MPI使用较多。
MPI
MPI是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。与OpenMP并行程序不同,MPI是一种基于信息传递的并行编程技术,详细使用方法可以参考官方文档。消息传递接口是一种编程接口标准,而不是一种具体的编程语言。简而言之,MPI标准定义了一组具有可移植性的编程接口。
实验环境
硬件配置
硬件环境系统配置了 3 个登录节点,260 个 CPU 计算节点,10 个 GPU 计算节点,一套 1.8P 共享存储。所有节点通过 100Gb/s EDR Infiniband 互联组成计算和存储网络。系统详细配置如下:
- 登录管理节点:共 3 个登录节点。
- GPU 计算节点:共 10 个 GPU 计算节点,每个节点配置 2 颗 Intel Golden 6240 系列处理器,共 36 个物理核,384GB 内存,8 个 NVIDIA V100 GPU 卡。 CPU 计算节点:共 260 个 CPU 计算节点,每个节点配置 2 颗 Intel Golden 6240 系列处理器,共 36 物理核,384GB 内存(根据 IB 网络配置,单个作业最多使用 160 个计算节点)。
- 并行存储系统:配置一套 DDN 并行存储系统,共配置 1.8PB 存储容量。
- 管理网络:配置一套千兆管理网。
- 带外管理网络:配置一套千兆带外管理网。
- 计算网络:配置一套 100Gb/s 高速 Infiniband 网。
软件配置
实验时,软件基本配置如下。
- 操作系统:采用 CentOS 7.6 版本操作系统。
- 作业调度软件:采用 Slurm 19.04 作业调度系统。
- 其他工具软件:Anaconda
Python3.9.6FFTW3.3.9PGPLOT5.2TEMPOCFITSIO4.0.0
软件配置步骤
基础准备
由于环境比较复杂,服务器中安装了各种版本的软件。大家可在同一软件的不同版本之间切换,也可以在同一功能的不同软件之间切换,以此来选择最合适的编程环境和运行环境。使用系统命令 module 可以快速地达到这一效果。
可以使用集群module中的Anaconda进行不同环境之间的隔离。可以使用下面这条命令先查看系统module
module avail
使用Anaconda
# 载入Anaconda模块
module load anaconda3/2019.10
# 创建新环境
conda create -n presto python=3.9.6
# 激活环境
conda activate presto
安装FFTW
FFTW官方网站
使用wget下载
wget www.fftw.org/fftw-3.3.9.tar.gz
下载完成之后,执行以下命令
tar -zxvf fftw-3.3.9.tar.gz
cd fftw-3.3.9/
ls
执行configure
./configure --enable-shared --enable-single --prefix='自定义为需要的安装目录'
部分输出信息如图所示
执行make
make
make install
安装PGPLOT
使用wget下载
wget ftp://ftp.astro.caltech.edu/pub/pgplot/pgplot5.2.tar.gz
等待下载完成后,执行
tar -zxvf pgplot5.2.tar.gz
进入pgplot目录下
cd pgplot/
ls
查看目录中的文件内容,并执行目录下的makemake
./makemake . linux g77_gcc
ls
发现文件夹中出现grexec.f grpckg1.inc pgplot.inc makefile pgplot.inc
如果编译报错,需要手动修改makefile文件,将其中的FCOMPL=g77修改为FCOMPL=gfortran
执行make
make
make cpg
make结果
注意到这里提示我们修改环境变量,部署环境章节也会提到。
安装TEMPO
Tempo下载地址
git clone git://git.code.sf.net/p/tempo/tempo
进入目录并查看
cd tempo/
ls
执行目录下prepare,为报错则执行成功
./prepare
修改相关配置
./configure --prefix='自定义为需要的安装目录'
执行make
make
make install
安装CFITSIO
CFITSIO下载地址
选择UNIX版本
实验时选择了4.0.0版本
wget http://heasarc.gsfc.nasa.gov/FTP/software/fitsio/c/cfitsio-4.0.0.tar.gz
tar -zxvf cfitsio-4.0.0.tar.gz
进入目录下并查看是否下载成功
调整配置
./configure --prefix='自定义为需要的路径'
执行make
make
make install
部署环境
从github上clone项目
git clone git://github.com/scottransom/presto.git
进入src文件夹,执行make相关操作
cd src/
make makewisdom
这一步时间消耗较长,等待执行完毕后,继续执行
make prep
如果没报错则成功,此时可以执行make命令
make
完成后,开始配置python相关环境
进入presto目录下
cd $PRESTO
pip install .
修改setup.py中的变量,根据安装的路径进行调整
修改ppgplot_libraries变量

进行build和install
python setup.py build
python setup.py install
至此,所有安装已经完成,可以进行下一步实验。
实验步骤
为测试直接执行与并行之间的效果对比,利用Slurm提交作业时,配置使用的节点数、使用的cpu核、每个节点启动的进程数,记录实验结果并绘制图像。
由于整体程序的流程执行较为复杂,并且有一部分程序不容易实现并行,所以只针对文档中提及的可以并行的程序进行实验。选择有代表性的两个程序,一个是predata,通过并行可以获得小幅度的性能提升;另一个为accelsearch,通过并行可以获得较大幅度的性能提升。
所以在测试之前,需要执行一些步骤以产生实验所需要的数据。其开源项目地址为https://github.com/scottransom/presto,在项目的文档中可以查看更详细的使用方法。
这里只写出实验的前两步,通过这两步即可生成实验所需的中间数据。首先进入$PRESTO/test文件夹下,并依次执行以下命令
readfile GBT_Lband_PSR.fil
rfifind -time 2.0 -o Lband GBT_Lband_PSR.fil
单节点运行
配置slurm文件,选择一个节点,并设置cpu核数为1
源代码
关于Slurm文件的编写
#!/bin/bash
#SBATCH -J presto
#SBATCH -p cpu-low
#SBATCH -N 1
#SBATCH -n 1
#SBATCH -t 5:00
#SBATCH -o single_test.out
#SBATCH -e single_test.err
cd $PRESTO/test/
accelsearch -numharm 4 -zmax 0 Lband_topo_DM0.00.dat
sbatch run.slurm # 提交作业(假设上述文件保存为run.slurm)
cat single_test.out # 查看结果
分别记录执行结果。
集群运行
调整节点数、cpu核数、每个节点进程数,进行性能测试。例如使用 2 个节点,使用 16 个cpu 核,每个节点启动 8 个进程。
源代码
Slurm文件的编写
#!/bin/bash
#SBATCH -J presto
#SBATCH -p cpu-low
#SBATCH -N 2
#SBATCH -n 16
#SBATCH --ntasks-per-node=8
#SBATCH -t 5:00
#SBATCH -o test.out
#SBATCH -e test.err
module load intel/18.0.3.222
cd $PRESTO/test/
mpirun -np 2 accelsearch -numharm 4 -zmax 0 Lband_topo_DM0.00.dat -ncpus 8
sbatch run.slurm # 提交作业(假设上述文件保存为run.slurm)
cat single_test.out # 查看结果
每次调整slurm文件中的参数配置,执行命令后记录结果。
实验结果
predata实验结果
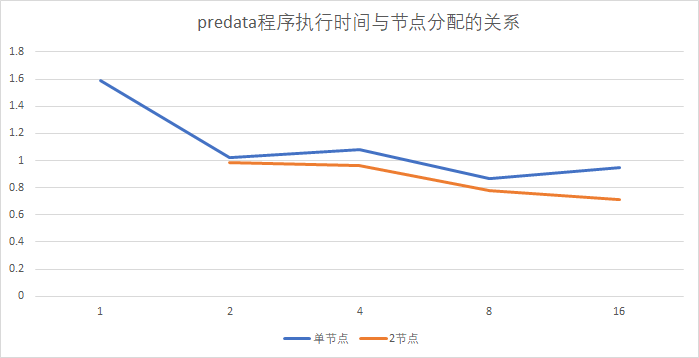
如图所示,蓝线为单节点运行,黄线为2个节点运行结果。下方横坐标代表每个节点使用的cpu核数,纵坐标为实验时predata的执行时间。可以看到,整体上有小幅度的性能提升,但正如文档中所说,也仅限于小幅度提升。
accelsearch实验结果
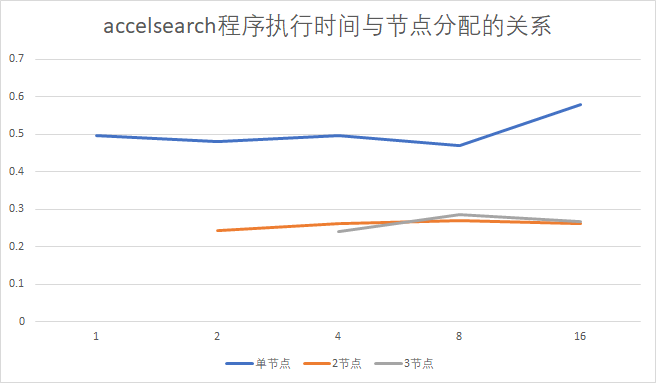
如图所示,蓝线为单节点运行,黄线为2个节点运行结果,灰线为3个节点运行结果。下方横坐标代表每个节点使用的cpu核数,纵坐标为实验时accelsearch的执行时间。可以发现在并行执行时有比较好的性能。
导入数据计算
以导入数据集http://www.cv.nrao.edu/~sransom/GBT_Lband_PSR.fil为例,整体计算步骤相同,只需要注意数据集存放的位置即可,在下载时可以新建$data目录,并将数据集命名为demo.fil,之后在特定命令时指定路径即可。
数据读入
主要有两步,指定对应数据集的路径,以生成中间数据用于并行计算
- readfile
- rfifind
readfile $data/demo.fil
rfifind -time 2.0 -o Lband $data/demo.fil
并行计算
编写slurm文件,并提交作业
#!/bin/bash
#SBATCH -J presto
#SBATCH -p cpu-low
#SBATCH -N 2
#SBATCH -n 16
#SBATCH --ntasks-per-node=8
#SBATCH -t 5:00
#SBATCH -o demo.out
#SBATCH -e demo.err
module load intel/18.0.3.222
mpirun -np 2 accelsearch -numharm 4 -zmax 0 $data/Lband_topo_DM0.00.dat -ncpus 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号