
BFS模型
Flood Fill
通过初始的一个位置,覆盖该位置周围有关联的格子,
可以在线性时间复杂度内,找到某个点所在的连通块
题目
最短路模型
计算到达某个位置需要的最短步数、最短路径
使用BFS第一次搜到目标的结果就是最短的,只要遍历从该点出发的所有情况,且进行标记判重,减少多余的重复计算
多源BFS
对于一般的BFS,只有单源的入口点,然后按照BFS套路,从而求出最短路之类的问题,多源BFS是含有多个入口节点,且求出最短路之类的问题
BFS的正确性
- 具有两段性:最多有两种状态,即当前状态和下一步的状态
- 单调性:值单调递增,所以最先更新的值是最小值、最短路
矩阵距离 :求矩阵中每个点到最近的1的距离,以距离矩阵形式输出结果
最小步数模型
与最短路模型的区别?
最短路模型:某个点到另一个点的最短距离(坐标与坐标之间)
最小步数模型:是状态到另一个状态的转变
技巧:在最小步数模型中状态中和状态的距离通常用哈希表进行存储(key-value映射关系),如map、unordered_map
思路:将初始状态加入队列,然后去搜索扩展,直到搜索到目标状态
注:搜索过程中可能有状态的转换,如一维到二维的变换,字符串到坐标的变换
双端BFS
链接:https://www.cnblogs.com/hoppz/p/15058725.html BFS双端 & A* & 双边BFS
适用范围
边权值可能有,也可能没有(BFS适用于权值为1的图,所以一般是0 or 1),或者能转化为这种权值的最短路问题,例如迷宫问题中,花1个金币走5步,不花金币走1步。
适用于解决图中边权只有
0和1的最短路问题
实现
一般情况下,把没有权值的边扩展到的点放到队首,有权值的边扩展到的点放到队尾。越靠近队首,权值越小,且权值0 1 之间有分割(两段性、单调性)
每次从队头取出元素,进行扩展元素
- 1、若扩展某一元素边权是0,则将该元素插入到队头
- 2、若扩展某一元素边权是1,则将该元素插入到队尾
与堆优化Dijkstra一样,必须在出队时才知道每个点最终的最小值
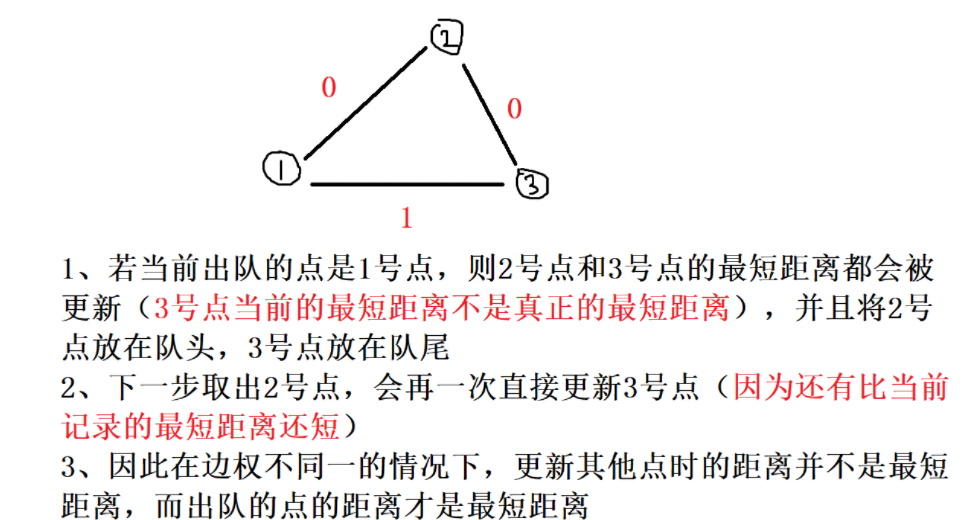
算法正确性
当我们更新到的点边权为0时,那么这个点一 定是到当前为止的最短路,所以可以直接将改点移至队首,如果这个点边权为1,那么这个点可能并不是到当前为止最短的,因此我们要将它移至队尾。
双向广搜|双端队列广搜
所谓双向广搜,就是初始节点向目标节点和目标节点向初始节点同时扩展,直至在两个扩展方向上出现同一个结点,搜索结束。双向广搜对单纯的广搜进行了改良或改造,加入了一定的“智能因数”,使搜索能尽快接近目标结点,减少了在空间和时间上的复杂度。---> 用在最小步数模型
双向扩展结点,在两个方向上的扩展顺序上,可以轮流交替进行,但由于大部分的解答树并不是完整的完全树,扩展完下一层后,下一层选择结点个数较少的那个方向先进行扩展,可以克服两个方向结点生成速度不平衡的状态,提高搜索效率
如果从起点和终点两个方向同时搜,会减少很多的无用的搜索范围
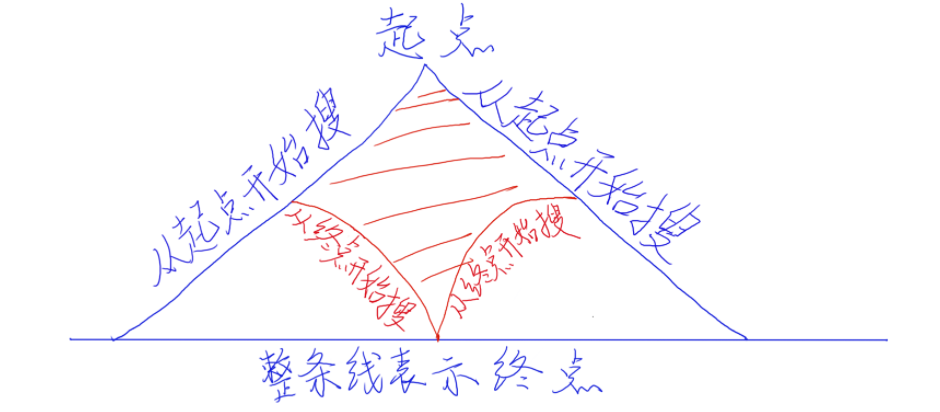
方法
1、使用两个队列,每个队列都对该方向搜索到的状态进行记录
2、注意两个队列搜索的扩展规则是相反的,每次只扩展一层(即到初始状态距离相同的一些结点)
3、当其中一个方向扩展到的状态在另一个方向已经出现的时,即两个方向相遇了
4、循环条件 (q1.size() && q2.size()) --- 两个队列都不空的情况,当其中一个队列为空,说明该方向的状态都遍历完了,此时表明两个方向没有交集
A*算法
形式类似与dijkstra算法, 可以处理任意边权问题(除了负权回路)
while(!q.empty()) {
t <---- 优先队列的队头(小根堆)
当终点第 1 次出队时, break
for (t的所有领边)
将领边入队
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号