Solr学习笔记---部署Solr到Tomcat上,可视化界面的介绍和使用,Solr的基本内容介绍,SolrJ的使用
学习Solr前需要有Lucene的基础
Lucene的一些简单用法:https://www.cnblogs.com/dddyyy/p/9842760.html
1.部署Solr到Tomcat(Windows)
Solr自带小型服务器jetty,但在我们开发环境中,习惯使用Tomcat,所以把Solr部署到Tomcat上(Tomcat 8.0以上,jdk 1.8以上)
其实步骤相同,但在windows配置要方便一些,所以第一次还是使用Windows来部署。
1.1 准备工作
Solr下载地址:http://archive.apache.org/dist/lucene/solr/
Tomcat下载地址:http://tomcat.apache.org/ 
1.2 把 solr-7.5.0\server\solr-webapp下的webapp文件夹移到apache-tomcat-9.0.12\webapps下并改名solr(这个名字随便起)

1.3 导入运行时候需要的依赖包,把solr-7.5.0\server\lib\ext下的包放到apache-tomcat-9.0.12\webapps\solr\WEB-INF\lib下,
把solr-7.5.0\server\lib下m开头的五个jar和gmetric4j-1.0.7.jar放到apache-tomcat-9.0.12\webapps\solr\WEB-INF\lib下
1.4 在任意地方创建一个solrHome,里面有一个solrCore,个人和我们的数据库类似,一个用户下可以创建很多个不同的数据库
1.5 把solr-7.5.0\server下的solr文件夹下的内容复制到solrHome下
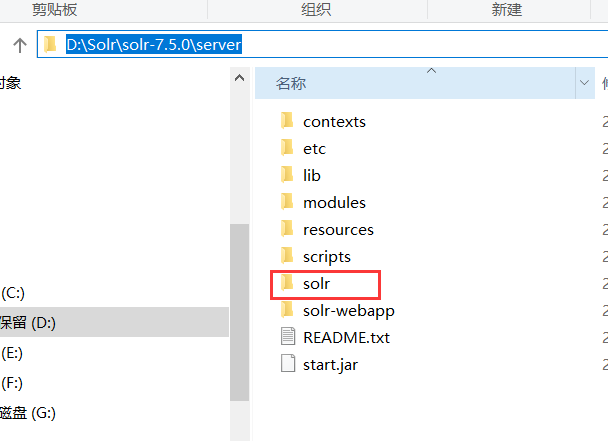
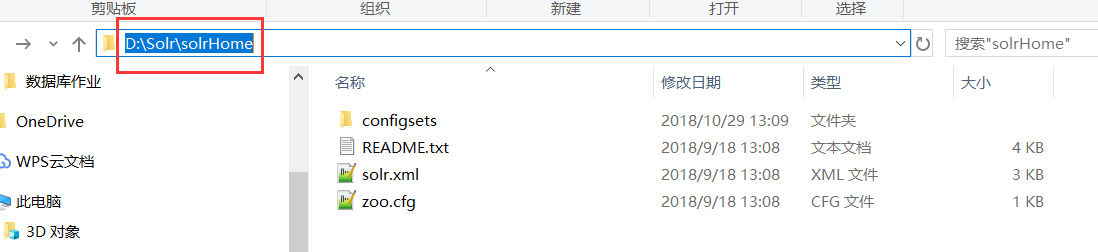
1.6 修改默认的solrHome,在apache-tomcat-9.0.12\webapps\solr\WEB-INF的web.xml修改 加上
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>D:\Solr\solrHome</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>
env-entry-value写自己的solrHome位置
并注释以下这段话,不然会报403
<!-- Get rid of error message --> <!--<security-constraint> <web-resource-collection> <web-resource-name>Disable TRACE</web-resource-name> <url-pattern>/</url-pattern> <http-method>TRACE</http-method> </web-resource-collection> <auth-constraint/> </security-constraint> <security-constraint> <web-resource-collection> <web-resource-name>Enable everything but TRACE</web-resource-name> <url-pattern>/</url-pattern> <http-method-omission>TRACE</http-method-omission> </web-resource-collection> </security-constraint>-->
1.7 把solr-7.5.0\server\resources的log4j2.xml放到apache-tomcat-9.0.12\webapps\solr\WEB-INF的classes文件夹下,classes文件刚开始没有,自己创建一个。
1.8 启动Tomcat
2.界面的简单介绍

2.1.Dashboard
仪表盘,显示了系统资源,jvm等信息
2.2.Logging
Solr运行的日志
2.3 Core Admin
Solr Core的管理页面
2.4 java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息
2.5 Thread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息
3.创建一个solrCore
既然之前说类似于数据库,使用数据库之前肯定就要先创建数据库,我们使用Solr就要先创建一个solrCore,直接使用可视化界面创建
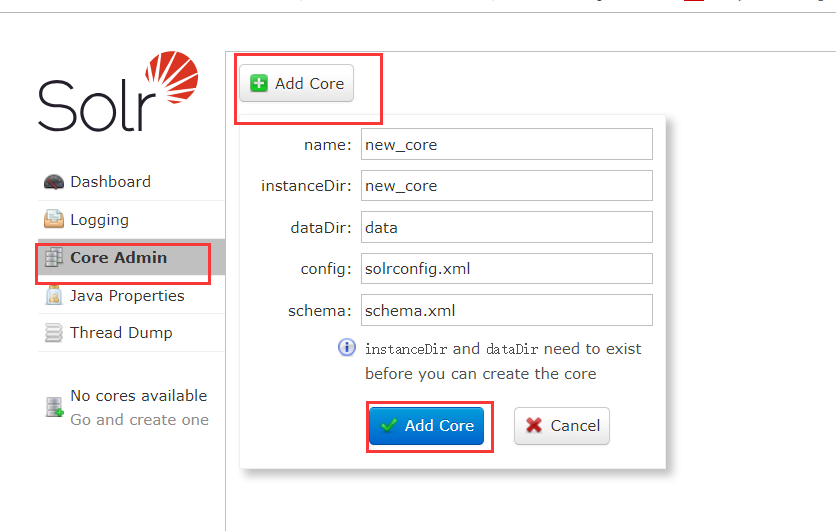

报错了,解决方法:solr-7.5.0\server\solr\configsets\_default下的config文件移到solrHome\new_core下
重启Tomcat
在点击下add core 就出现了

一个MySql实例可以创建多个数据库,所以我们当然可以创建多个solrCore啦
修改core.properties


重启Tomcat
4.Solr中的重要信息配置
在增删查改前,我们要先了解一点Solr的信息配置
在Lucenc中有域和索引的概念,域是由域名和域的内容构成的,域名经过分词,形成索引。
在Lucene中域是有类型的,比如StringField,LongField类型等,那么在Solr中域的类型由写在solrHome\new_core\conf\managed-schema中
4.1 fieldType 域类型
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <!-- in this example, we will only use synonyms at query time <filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/> <filter class="solr.FlattenGraphFilterFactory"/> --> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
name:类型名字
class:指定该域类型对应的solr类型
analyzer:指定分词器(中文使用ikanalyzer)属性type index,query表示在创建索引和查询索引时使用的分词器
tokenizer:分词器的类型
filter:过滤器的类型
4.2 fieldtype 域
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
name:域的名字
type:域的类型(自己定义的)
indexed:是否索引
stroed:是否存储
required:是否必须
multiValued:是否多值
4.3 dynamicField 动态域
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
例子:为文档增加域的时候,你可以用 “随便起的_i”当做域名, 凡是以_i结尾的 type都是pint,需要indexed,需要stored
4.4 uniqueKey 唯一键
<uniqueKey>id</uniqueKey>
表示id唯一
5.配置中文分词器 ikanalyzer
既然要添加索引,添加索引之前需要luncenc帮我们分词,而官方的分词器对中文的分词基本是稀烂的,所以我们需要使用第三方的分词器 ikanalyzer
5.1 下载ikanalyzer
下载地址:https://github.com/magese/ik-analyzer-solr7
5.2 配置ikanalyzer
首先把ik-analyzer-7.5.0.jar放到apache-tomcat-9.0.12\webapps\solr\WEB-INF\lib目录下
然后:

5.3 使用ikanalyzer
在solrHome\new_core\conf\managed-schema中自定义fieldtype和field,使用中文分词器来分词
<!--IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
5.4 测试一下
重启tomcat
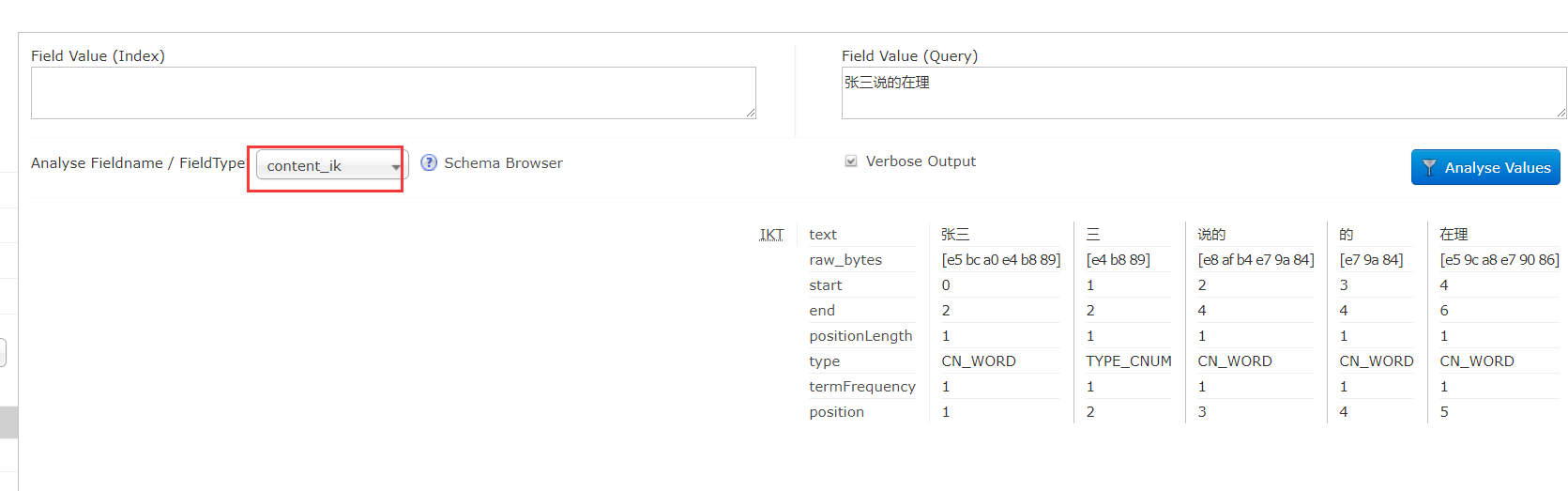
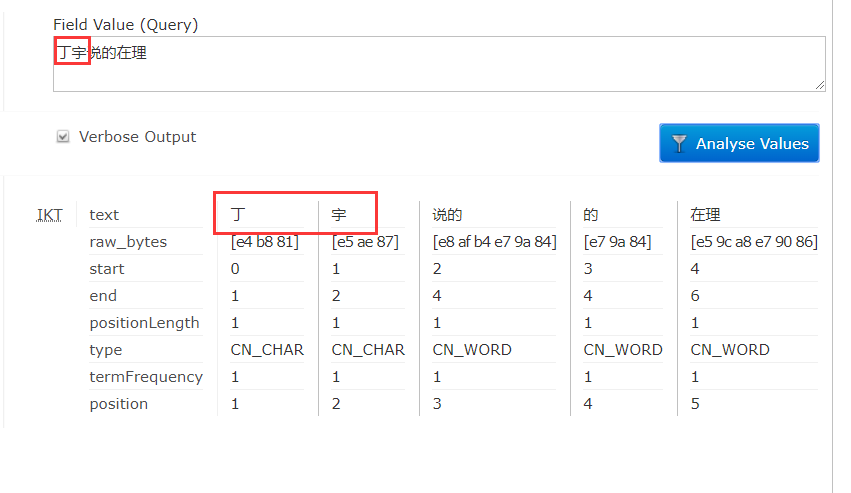
问题来了,我的名字没有加到词库,但是如果随着新的词语出现,我们就没办法分词了,ik分词器给我们提供了可以手动或自动加入词汇的方法
apache-tomcat-9.0.12\webapps\solr\WEB-INF\classes下的ext.dic加入自己的词汇,重启Tomcat


6.使用可视化界面增删查改文档
增加文档
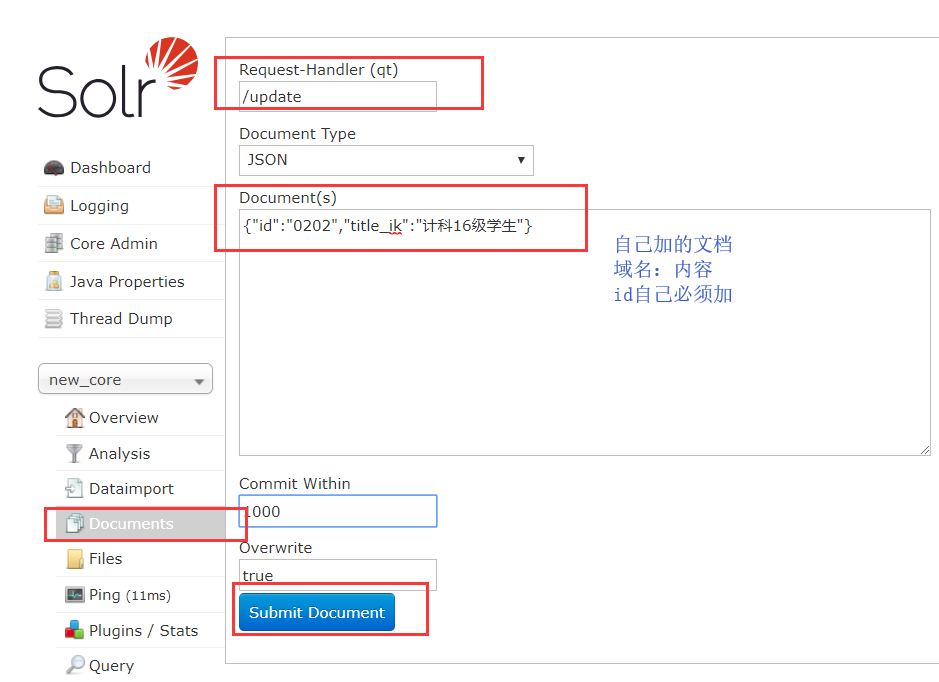
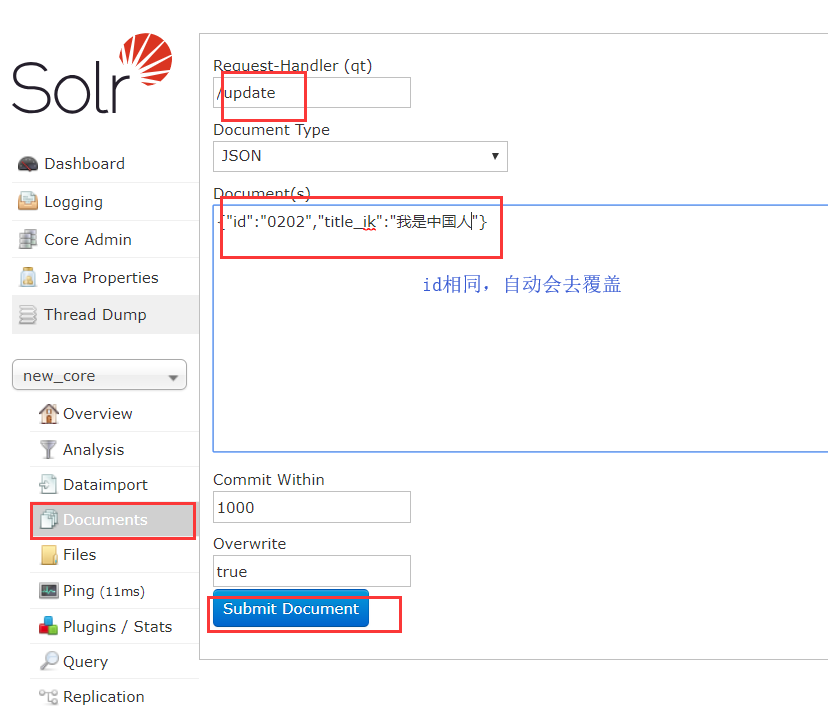
更新文档
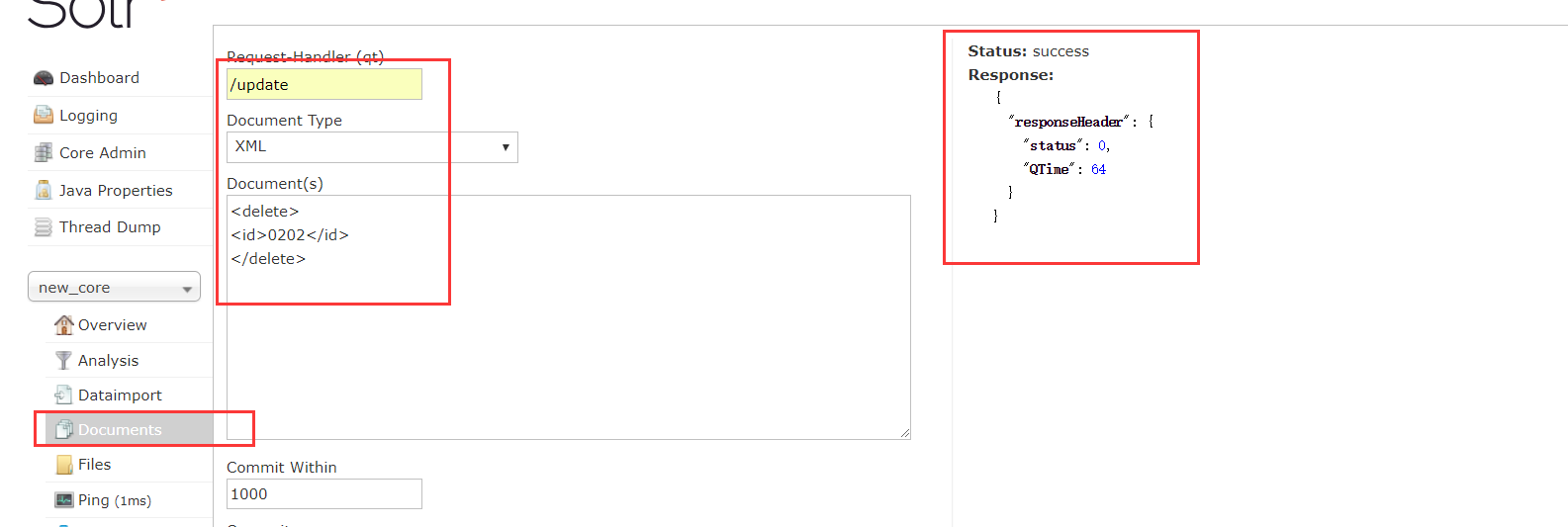
删除文档
查询文档
首先查询所有 *:*

加上过滤条件等一系列条件
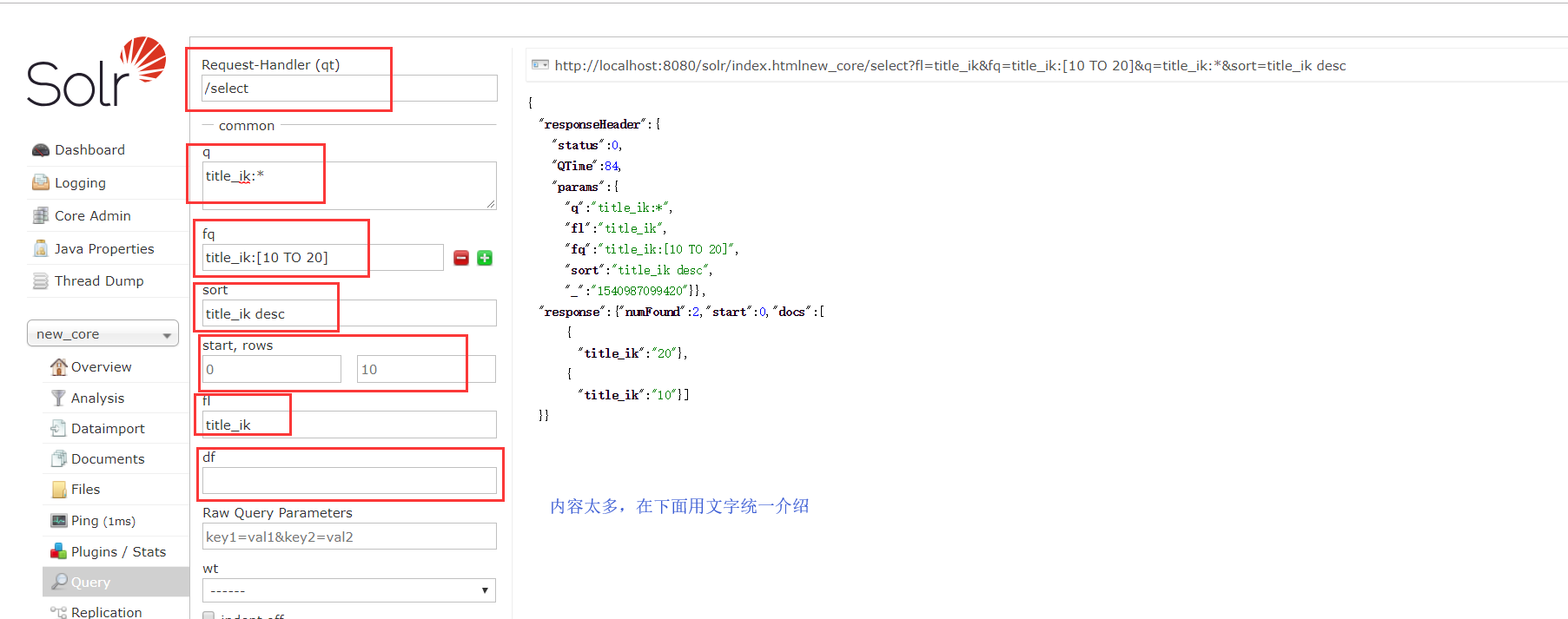

q: 查询关键字 查询所有*:* 查询固定的 就用 域名:域值
fq:过滤查询
sort:排序 格式 : 先写域名然后加升序或降序 ,不同域用逗号隔开 id desc,title_ik desc
start row : 用于分页
fl:返回指定的域和域值,不同域用逗号隔开
df:指定一个搜索域,用处:比如有的时候你在百度查 “Solr”,你输入的应该直接是Solr,不会输一个Content:Solr吧,那么我们就可以指定默认搜索域Content,你输入Solr就默认加上域值。
wt:指定输出格式
hi:是否高亮,在指定的域中,比如我搜索中国,经过分词,在title_ik域中找到了中国,那么在中国这两个字之前就加上pre前缀,在后面加上post后缀
7.使用SolrJ
Solr和SolrJ的关系类似于MySQL和JDBC,用java代码来完成文档的增加。
7.1坏境搭建
<dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-solrj</artifactId> <version>7.5.0</version> </dependency>
7.2 代码
package com.dingyu.sSolrJ; import java.io.IOException; import org.apache.commons.math3.geometry.partitioning.BSPTreeVisitor.Order; import org.apache.solr.client.solrj.SolrQuery; import org.apache.solr.client.solrj.SolrQuery.ORDER; import org.apache.solr.client.solrj.SolrServerException; import org.apache.solr.client.solrj.impl.HttpSolrClient; import org.apache.solr.client.solrj.response.QueryResponse; import org.apache.solr.common.SolrDocument; import org.apache.solr.common.SolrDocumentList; import org.apache.solr.common.SolrInputDocument; import org.junit.Test; /** * SolrJ的简单使用 * * @author 丁宇 * */ public class SolrJTest { /** * 获得连接 * * @return 连接对象 */ private HttpSolrClient getClient() { HttpSolrClient client = new HttpSolrClient.Builder("http://127.0.0.1:8080/solr/new_core").build(); return client; } /** * 增加/修改文档 * * @throws SolrServerException * @throws IOException */ @Test public void addOrUpdateDoc() throws SolrServerException, IOException { // 获得连接对象 HttpSolrClient client = getClient(); // 创建一个文档对象 SolrInputDocument document = new SolrInputDocument(); // 加域 document.addField("id", "521"); document.addField("title_ik", "张三说的在理"); // 提交 client.commit(); client.close(); } /** * 删除文档 * * @throws SolrServerException * @throws IOException */ @Test public void deleteDoc() throws SolrServerException, IOException { // 获得连接对象 HttpSolrClient client = getClient(); // 根据id删除 client.deleteById("521"); client.commit(); client.close(); } /** * 查询文档 * @throws SolrServerException * @throws IOException */ @Test public void selectDoc() throws SolrServerException, IOException { // 获得连接对象 HttpSolrClient client = getClient(); // 搜索条件 SolrQuery query = new SolrQuery("*:*"); //设置过滤条件 query.setFilterQueries("title_ik:[10 TO 20]"); //排序 query.setSort("title_ik",ORDER.asc); //分页 query.setStart(0); query.setRows(10); //要显示的域 query.setFields("id","title_ik"); // 设置默认搜索域 query.set("df", "product_name"); // 设置高亮 query.setHighlight(true); query.addHighlightField("title_ik"); query.setHighlightSimplePre("<em>"); query.setHighlightSimplePost("</em>"); //执行查询 QueryResponse response = client.query(query); //查询结果,一个文档集合 SolrDocumentList results = response.getResults(); //遍历 for (SolrDocument solrDocument : results) { //根据key 获得value System.out.println(solrDocument.get("id")); } client.close(); } }
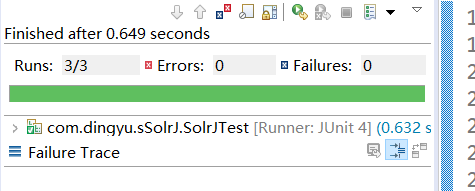
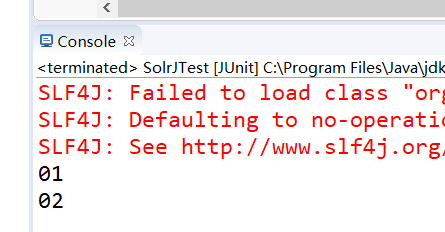
7.3测试结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号