Lucene的简单用法
1.创建索引
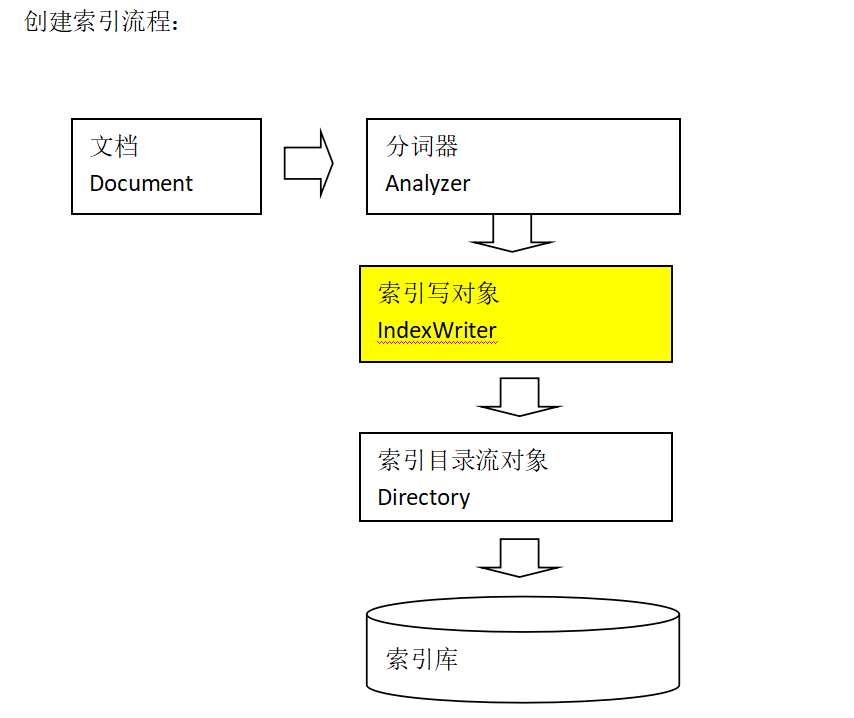
package com.DingYu.Test; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.UnsupportedEncodingException; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.StoredField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; /** * 我们的目标是把索引和文档存入索引库中, 所以首先我们需要创建一个索引库 然后创建一个IndexWrite对象把索引,和文档对象写入, * 文档对象中需要自己设置域,索引是通过分词器对域进行分词产生的, 所以我们需要分词器 * * @author 丁宇 * */ public class LuceneTest { /** * 创建索引 * @throws IOException */ @Test public void createIndex() throws IOException { // 标准分词器 Analyzer analyzer = new StandardAnalyzer(); // 创建一个索引 Directory directory = FSDirectory.open(Paths.get("D:\\LuceneIndex")); // 创建一个IndexWriteConfig对象 IndexWriterConfig config = new IndexWriterConfig(analyzer); // 创建一个IndexWrite对象 IndexWriter write = new IndexWriter(directory, config); // 获得所有文件下的文件 File[] files = new File("D:\\LuceneTest").listFiles(); for (File file : files) { // 创建一个文档对象 Document document = new Document(); // 增加一个filepath域,不分析 不索引 但会存储在索引库里 把文件路径放到域中 Field field1 = new StoredField("filepath", file.getPath()); // 增加一个filename域,会分词,会索引, Field field2 = new org.apache.lucene.document.TextField("filename", file.getName(), Store.YES); // 增加一个fileContent域,会分词,会索引,只放文件内容的索引 Field field3 = new org.apache.lucene.document.TextField("filecontent", fileContent(file), Store.NO); // 增加一个filesize域,不分析 不索引 但会存储在索引库里 把文件路径放到域中 Field field4 = new StoredField("filesize", file.length()); document.add(field1); document.add(field2); document.add(field3); document.add(field4); write.addDocument(document); } write.close(); } /** * 获得文件内容 * @param file * @return */ public String fileContent(File file) { byte[] fileContent = new byte[(int) file.length()]; FileInputStream in = null; try { in = new FileInputStream(file); } catch (FileNotFoundException e2) { e2.printStackTrace(); } try { in.read(fileContent); } catch (IOException e1) { e1.printStackTrace(); } try { in.close(); } catch (IOException e) { e.printStackTrace(); } try { return new String(fileContent, "UTF-8"); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } return null; } }

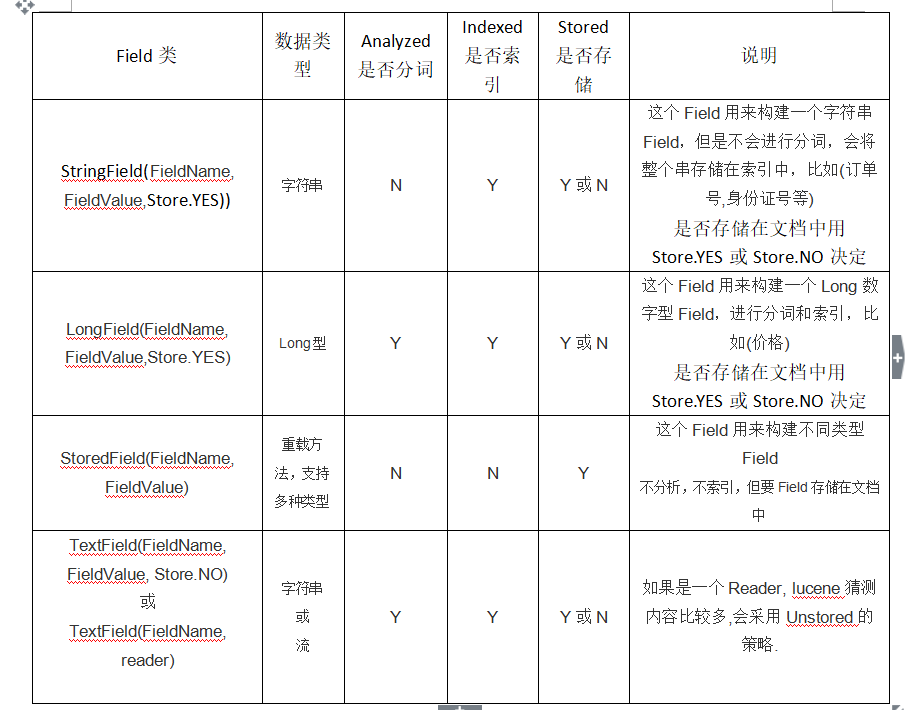
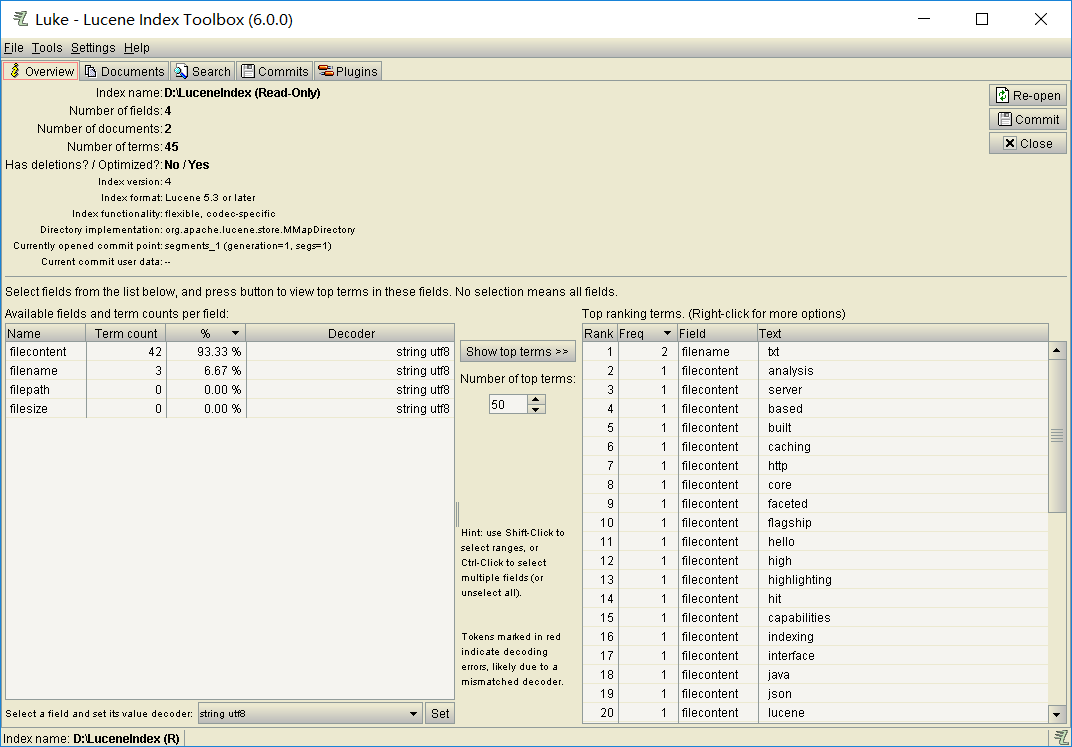
2.查询索引
package com.DingYu.Test; import java.io.IOException; import java.nio.file.Path; import java.nio.file.Paths; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.Term; import org.apache.lucene.search.BooleanClause.Occur; import org.apache.lucene.search.BooleanQuery; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.NumericRangeQuery; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; /** * 查询索引 * * @author 丁宇 * */ public class LuceneTest1 { // 获得IndexSearcher对象 private IndexSearcher getIndexSearcher() throws IOException { // 指定索引库 Directory directory = FSDirectory.open(Paths.get("D:\\LuceneIndex")); // 打开索引库 IndexReader reader = DirectoryReader.open(directory); // 创建查询的对象 IndexSearcher searcher = new IndexSearcher(reader); return searcher; } // 输出查到的内容 private void printIndex(TopDocs docs,IndexSearcher searcher) throws IOException { // 获得顶部匹配记录 ScoreDoc[] scoreDocs = docs.scoreDocs; // 获得在索引库中存着的文档的id,利用id去寻找文档 for (ScoreDoc scoreDoc : scoreDocs) { // 获得id int doc = scoreDoc.doc; // 获得文档 Document document = searcher.doc(doc); // 获得这个文档的域 System.out.println(document.get("filename")); System.out.println(document.get("filecontent")); System.out.println(document.get("filepath")); System.out.println(document.get("filesize")); System.out.println("------------------------"); } } /** * 精准查询 * @throws IOException */ @Test public void termQueryIndex() throws IOException { IndexSearcher searcher = getIndexSearcher(); // 选择合适的查询方法,这里用最简单的,具体的看下图 Query query = new TermQuery(new Term("filename", "txt")); // 执行查询 TopDocs docs = searcher.search(query, 2); //输出查询内容 printIndex(docs, searcher); // 关闭索引库 searcher.getIndexReader().close(); } /** * 范围查询 五个参数 第一个域名,第二个第三个表示范围,第四个第五个表示是否包含最小值和最大值。 * @throws IOException */ @Test public void numRangeQueryIndex() throws IOException { IndexSearcher searcher = getIndexSearcher(); // 选择合适的查询方法,这里用最简单的,具体的看下图 Query query = NumericRangeQuery.newLongRange("filesize", 0L, 1000L, true, true); // 执行查询 TopDocs docs = searcher.search(query, 2); //输出查询内容 printIndex(docs, searcher); // 关闭索引库 searcher.getIndexReader().close(); } /** * 组合查询 * @throws IOException */ @Test public void booleanQueryIndex() throws IOException { IndexSearcher searcher = getIndexSearcher(); BooleanQuery booleanQuery = new BooleanQuery(); Query query = new TermQuery(new Term("filename","txt")); Query query2 = NumericRangeQuery.newLongRange("filesize", 0L, 1000L, true, true); //表示query是必须的 query2也是必须 相当于并集 booleanQuery.add(query,Occur.MUST); booleanQuery.add(query2, Occur.MUST); // 执行查询 TopDocs docs = searcher.search(query, 2); //输出查询内容 printIndex(docs, searcher); // 关闭索引库 searcher.getIndexReader().close(); } }
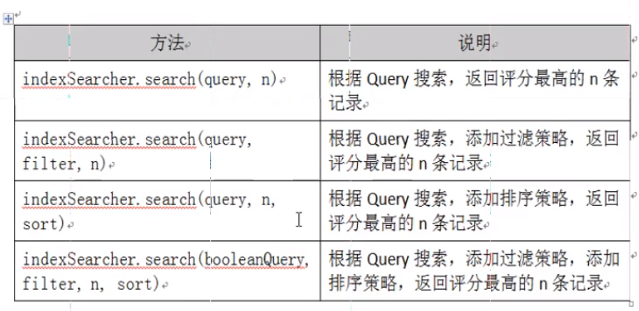

3.删除索引
package com.DingYu.Test; import java.io.IOException; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.Term; import org.apache.lucene.search.Query; import org.apache.lucene.search.TermQuery; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; /** * 删除索引 一般增删改都是同一个操作对象 这里使用IndexWriter对象 * * @author 丁宇 * */ public class LuceneTest3 { /** * 获得IndexWrite对象 * @return * @throws IOException */ public IndexWriter getIndexWrite() throws IOException { Analyzer analyzer = new StandardAnalyzer(); Directory directory = FSDirectory.open(Paths.get("D:\\LuceneIndex")); IndexWriterConfig config = new IndexWriterConfig(analyzer); return new IndexWriter(directory, config); } /** * 删除所有的索引 * * @throws IOException */ @Test public void deleteAllIndex() throws IOException { IndexWriter indexWrite = getIndexWrite(); indexWrite.deleteAll(); indexWrite.close(); } /** * 根据条件删除索引,同时删除文档 * @throws IOException */ @Test public void deleteSomeIndex() throws IOException { IndexWriter indexWrite = getIndexWrite(); Query query = new TermQuery(new Term("filename","txt")); indexWrite.deleteDocuments(query); indexWrite.close(); } }
4.修改索引
package com.DingYu.Test; import java.io.IOException; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.Field.Store; import org.apache.lucene.document.StringField; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexableField; import org.apache.lucene.index.Term; import org.apache.lucene.store.Directory; import org.apache.lucene.store.FSDirectory; import org.junit.Test; /** * 索引的修改 * @author 丁宇 * */ public class LuceneTest2 { private IndexWriter getIndexWriter() throws IOException { Analyzer analyzer = new StandardAnalyzer(); Directory directory = FSDirectory.open(Paths.get("D:\\LuceneIndex")); IndexWriterConfig config = new IndexWriterConfig(analyzer); return new IndexWriter(directory, config); } @Test public void updateIndex() throws IOException { IndexWriter indexWriter = getIndexWriter(); Document document = new Document(); document.add(new StringField("filename", "think in java", Store.YES)); //update 就是删除一个你指定的 创建一个你想要的 。 indexWriter.updateDocument(new Term("filecontent","txt"), document); indexWriter.close(); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号