
使用Java解析XML
一.解析的对象
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="1">
<username>小丁</username>
<password>123</password>
</user>
<user id="2">
<username>小彭</username>
<password>123</password>
</user>
</users>
二.解析的方法介绍
1.DOM(docuement object model)解析
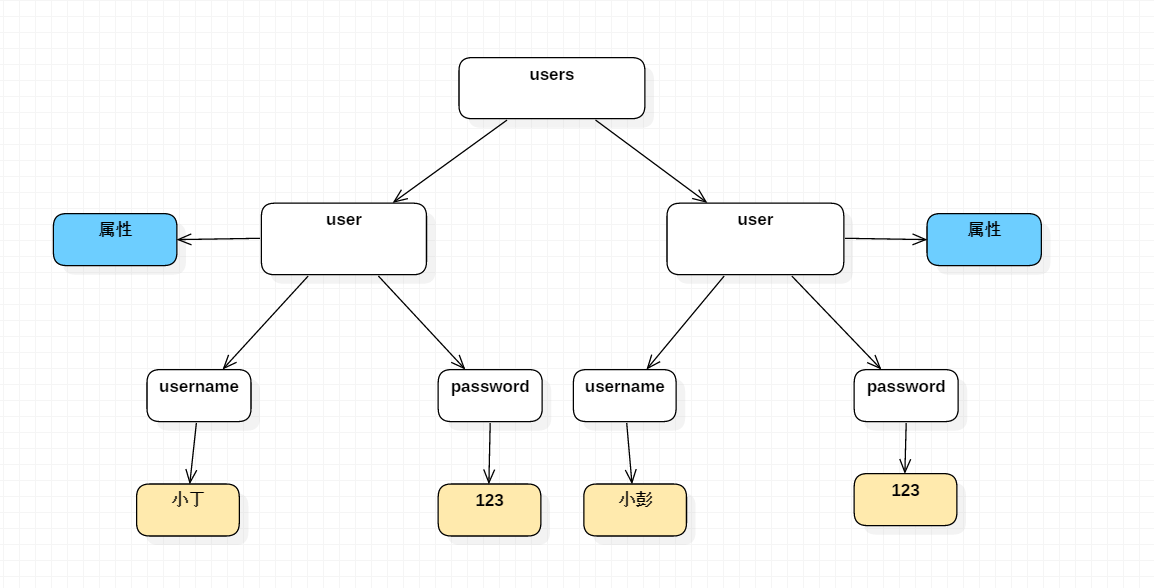
把所有的XML内容读到内存中,形成树状结构。这个树状结构是一个对象,名字叫docuement
DOM解析中的一些术语
Doucment:整个对象(整颗数)
Element:元素,就是标签,上面的users,user,username,password四个标签
Attribute:属性,user标签中的id属性
Text:文本,标签中的内容,上图最下面的叶子节点。
Node:上面四个都可以叫Node
2.SAX(simple API for XML)
SAX一条条读到内存并解析
三.代码实现
使用dom4j(一个API,封装了我们需要的方法)
第一种实现 导入dom4j的jar:
package xmlDemo;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
public class UserTest {
@Test
public void DOMTest() {
try {
SAXReader reader = new SAXReader();
// 读取要解析的xml文件
Document document = reader.read(new File("src/User.xml"));
// 获得根元素
Element rootElement = document.getRootElement();
// 获取根元素下的所有子元素
List<Element> elements = rootElement.elements();
for (Element element : elements) {
String username = element.element("username").getText();
String password = element.element("password").getText();
System.out.println("username=" + username + " password=" + password);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
结果:
第二种XPath: 导入dom4j jar 包外还需导入![]()
package xmlDemo;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
public class UserTest {
@Test
public void XPathTest() {
try {
SAXReader reader = new SAXReader();
// 读取要解析的xml文件
Document document = reader.read(new File("src/User.xml"));
// 获得根元素
Element rootElement = document.getRootElement();
//选择所有的username元素对象
List<Element> nodes = rootElement.selectNodes("//username");
for (Element element : nodes) {
System.out.println("username="+element.getText());
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
结果: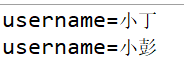

 浙公网安备 33010602011771号
浙公网安备 33010602011771号