
实验5
实验任务3:
with open('data3.txt','r',encoding='utf-8')as f: t=f.readlines() p=[] for i in t: if t[0]==i: y='原始数据'+'\t'+'四舍五入后数据'+'\n' p.append(y) else: y=i.strip('\n')+'\t'+str(round(eval(i)))+'\n' p.append(y) with open('data_process.txt','w',encoding='utf-8')as f: x=''.join(p) f.write(x) with open('data_process.txt','r',encoding='utf-8')as f: t=f.readlines() a=[] b=[] for i in t: if t[0]!=i: y=i.strip('\n') z=y.split('\t') a.append(eval(z[0])) b.append(eval(z[1])) print('原始数据:','\n',a) print('四舍五入后数据:','\n',b)
截图:


实验任务4:
with open('data4.txt', 'r+', encoding='utf-8') as f: str = [i.strip('\n').split('\t') for i in f] a = str.pop(0) str.sort(key=lambda x: (x[2], -int(x[-1]))) print('\t'.join(a)) for i in str: print('\t'.join(i)) with open('data4_progressed.txt', 'w') as f: f.write('\t'.join(a)) f.write('\n') for i in str: f.write('\t'.join(i)) f.write('\n')
截图:

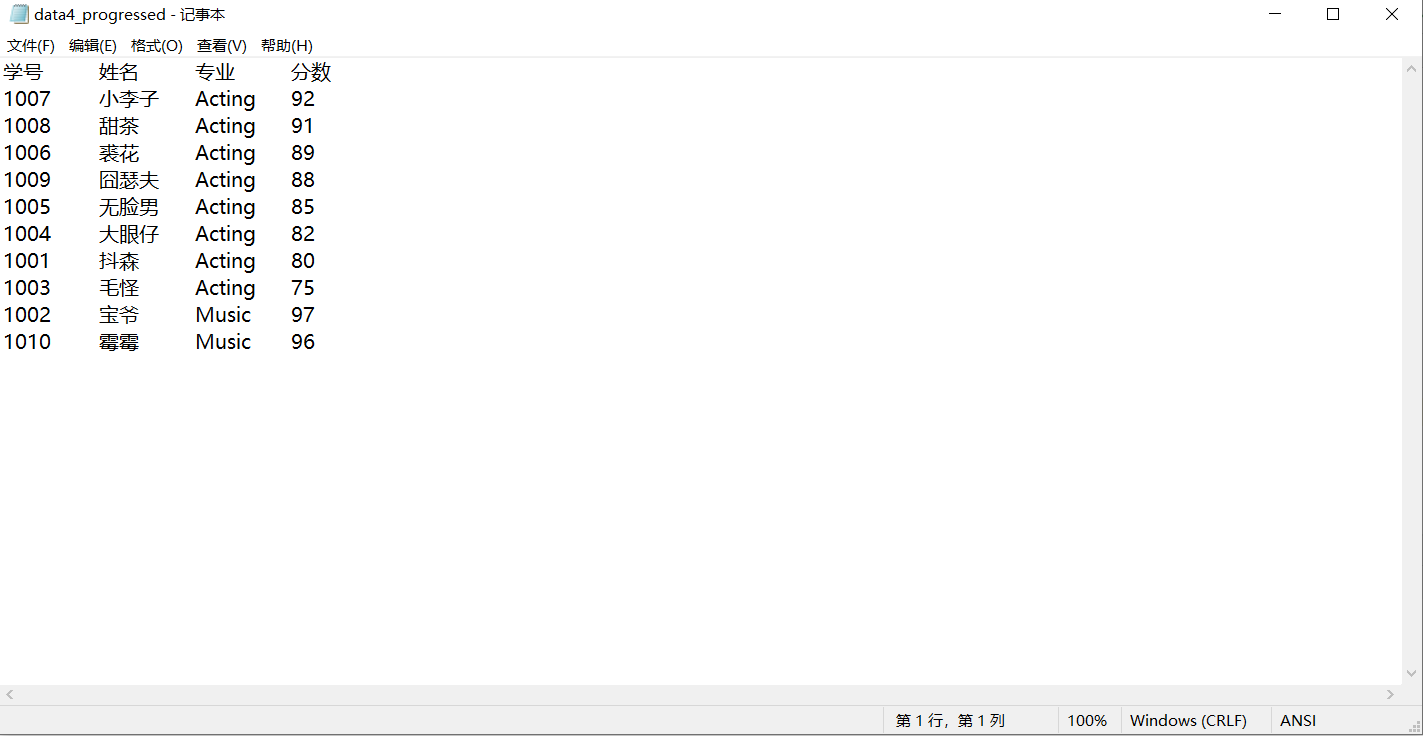
实验任务5:
with open('data5.txt','r',encoding='utf-8') as f: list = ''.join([i for i in f]) print(f'行数:{len(list.splitlines())}') print(f'单词数:{len(list.split())}') print(f'空格数:{list.count(" ")}') print(f'字符数:{len(list)}') with open('data5_with-line.txt','w',encoding='utf-8') as f: for i in range(len(list.splitlines())): f.write('{} {}'.format(i + 1, list.split('\n')[i])) f.write('\n')
截图:



