
图论
拓扑排序
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
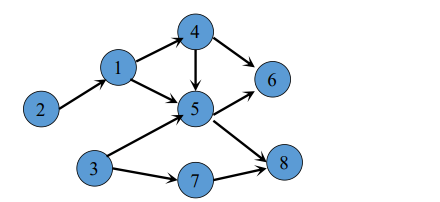
• 拓扑图,就是一张有向联通无环图
• 拓扑序就是一张有向图遍历的点的顺序.
• 拓扑排序就是考虑这个有向无环连通图中,有一条边(x,y),当选了x点之后才能 选y点,那么在拓扑序中x点一定要在y点之前.
• 具体求拓扑序的方法就是每次在图中找到入度为0的点,加入到队列中,同时不 断地扩展.
• 这张图的拓扑序就是21435678......
最小生成树
一般使用kruskal。
例题:cf76A gift
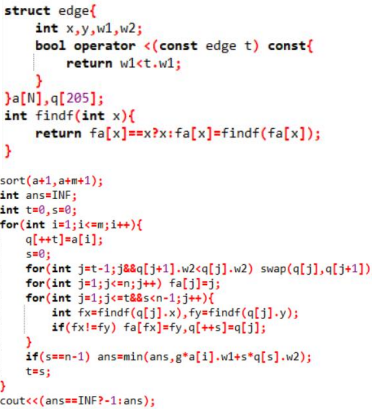
给你 n 个点, m 条边, (x, y, w1 , w2) 表示连接 x, y 的边有两个数 w1 ,w2,
又给你一对数(g,s), 要你求一个生成树,使得 g*max(w1 ) + s*max(w2) 最小. n<=200,m<=1 00000
in: 3 3 2 1 1 2 1 0 1 5 1 2 4 20 1 3 5 1
out: 30
解题思路:
• 考虑一个暴力,枚举w1的最大值x,然后把第一维<=x的边拿出来建第二维的最 小生成树.
• 那么把这个暴力改成按照第一维排序,容易发现,随着第一维的最大值增加, 可选得第二维最小值会不但减少,因此相当于可以不断加入边,然后每次删掉 树上环上第二维最大的边即可。删边可以暴力dfs.
• 复杂度是 O(m*n+mlogm).
核心代码:
最小生成树的唯一性
思考怎么判定一个图只有一个最小生成树?
只需要判定权值相等的边能用和实际用的数量相等即可。
次小生成树
一种思想是先求出最小生成树。 然后枚举删去最小生成树中的边,再求最小生成树。 时间复杂度O(nmlogm)。
注意到次小生成树一定是最小生成树进行一次加边删边操作得到的。 即加入非树边 (u,v), 然后一定会形成由树上 u, v 路径再加上该边的环。这样只需要删除 环中除此边外的最大边即形成新的生成树。然后依次枚举非树边找最小值即可。
具体操作:
1、 O(n^2)预处理出最小生成树上任意两点形成的路径的最大边权。
2、枚举非树边加入并删边,更新生成树权值和 ans=ans+w[u][v]-maxw[u][v]。
3、求最小权值和。 时间复杂度O(n^2+m)。 更进一步,任意两点最大边权可以倍增来维护。时间复杂度O(nlogn+m).
更进一步,我们发现刚刚求解的过程求出来的为 “非严格” 次小生出树。 当加的边和删的边权值相等时出现。
思考怎么解决?
倍增求解时维护一个严格次大值,当加的边和删的边权值相等时,删次大边 即可。 设 max[i][j], max2[i][j] 维护的是 i 到 2^j 祖先的最大值和次大值。 更新时从 max[i][j-1 ], max[fa[i][j-1 ]][j-1 ], max2[i][j-1 ], max2[fa[i][j-1 ]][j-1 ] 四个值 中选最大和次大值分别更新即可。
最小斯坦纳树
最小生成树是在给定点集和边中找最短网络使所有点联通。 而最小斯坦纳树解决的是可以增加额外的点使最短网络最小。 一般情况是给你一个图,然后要你求包含给定点集的最短网络。
最短路以及差分约束
知识点回顾:
• floyd,就是三重循环枚举三个点复杂度n^3, f[i][j]=min(f[i][k]+f[k][j]).
• floyd其实是基于一种dp的思想.
• spfa,就是每次扩展一个点,把扩展到的能更新的点看是否在队列里,不在就加 进去继续更新,复杂度玄学,x*(n+m)
• dijkstra就是把每个点按最短路长度扔到堆里然后更新,每个点只会扩展一次,
复杂度nlog+m,注意这个log是带在n上的.
• 对于边比较多的图跑dijkstra比较优秀.
• 并且dijkstra永远也不会被卡,永远不会.
Johonson重赋值
1、目的: O(nmlogm)求多源最短路。
2、思路:对每个顶点跑堆优化的djk。
3、错误思路:每个边加一个最小负值的绝对值。
4、核心:解决djk没法解决的负权边问题。
5、步骤: 新建一个虚拟的点,将该点向图的所有顶点连权值为0的边。 将该点当源点跑次spfa或bellman,记录每个点i的最短路hi。 将图的所有边重赋值:如果u->v有权值w的边,则w’=w+hu-hv.
然后对原图跑n次djk即可。(答案记得还原)
6、正确性及证明
blabla。。。
7、练习请参考P5905 johnson模板
分层图最短路问题
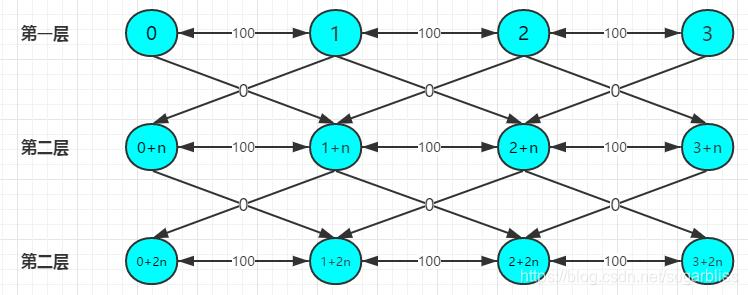
一般有两种方法解决分层图最短路问题:
1、拆点法: 建图时直接建成k+1层。
1、建k+1层图。
2、然后有边的两个点,多建一条到下一层边权为0的单向边,如果走了这条 边就表示用了一次机会。
3、有N个点时, 1 ~n表示第一层,(1 +n) ~(n+n)代表第二层,(1 +2*n)
~(n+2*n)代表第三层,(1 +i*n) ~(n+i*n)代表第i+1层。 因为要建K+1层图,数组要开到n * ( k + 1 ),点的个数也为n * ( k + 1 ) 。
4、最后跑最短路,答案为min(dis[n],dis[n+n]…dis[n+kn])
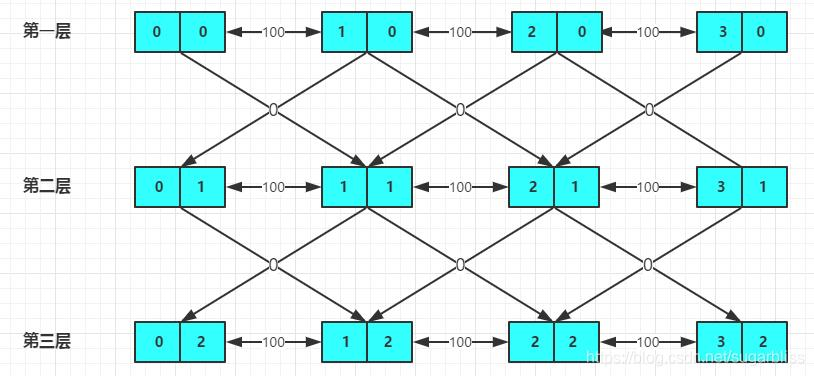
2、 DP法: 多开一维记录机会信息。
我们把dis数组和vis数组多开一维记录k次机会的信息。
dis[ i ][ j ] 代表到达 i 用了 j 次免费机会的最小花费. vis[ i ][ j ] 代表到达 i 用了 j 次免费机会的情况是否出现过.
更新:先更新同层之间(即花费免费机会相同)的最短路,然后更新从该层到 下一层(即再花费一次免费机会)的最短路。
不使用机会 dis[v][c] = min(dis[v][c], dis[now][c] + edge[i].w) ;
使用机会 dis[v][c+1 ] = min(dis[v][c+1 ], dis[now][c]) ;
最小瓶颈路
首先,有个瓶颈生成树的概念:即在所有生成树中,最大边权最小。 很显然,最小生成树一定是瓶颈生产树,瓶颈生成树不一定是最小生成树。 更进一步, x 到 y 最小瓶颈路上的最大边权一定是最小生成树上 x 到 y 路径上的最大边权。 证:虽然最小生成树不唯一,但是每种最小生成树 x 到 y 路径的最大边权相同且为最小值。也就是 说,每种最小生成树上的 x 到 y 的路径均为最小瓶颈路。 但是,并不是所有最小瓶颈路都存在一棵最小生成树满足其为树上 x 到 y 的简单路径。所以一般 题目只会询问最小瓶颈路上的最大边权的值。 因此我们只需要维护最小生成树树链上的max即可。(树上倍增、树剖) 我们还可以用 Kruskal 重构树来解决该问题。
kruskal 重构树
在 kruskal 算法过程中,每次找到一条边去合并两个集合时,我们可以新建一个点,该点点权即为 加边的边权,然后左右儿子分别为要合并的两个集合的根节点。 这样进行 n-1 轮之后我们得到了一棵恰有 n 个叶子的二叉树,同时每个非叶子节点恰好有两个儿 子。这棵树就叫 Kruskal 重构树。 例子如下图所示:
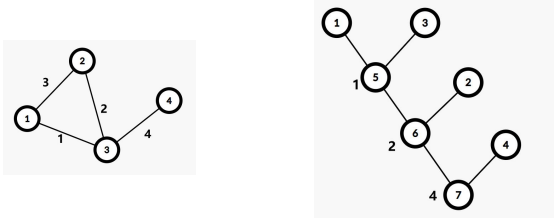
性质: 两点最小瓶颈路上最大边权最小值=最小生成树两点路径最大边权=kruskal重构树上两点之间的
LCA的点权值。 因此,到点 x 的简单路径上最大边权的最小值 <=val 的所有点 均在 Kruskal 重构树上的某一棵子 树内,且恰好为该子树的所有叶子节点。 我们在 kruskal 重构树上从 x 往上找点权<=val 的最浅的节点,该点即所有满足条件的节点所在的 子树的根节点。 如果需要求原图中两个点之间的所有简单路径上最小边权的最大值,则在跑 Kruskal 的过程中按 边权大到小的顺序加边。
差分约束系统
差分约束是解决这么一类问题的:
有 n 个变量 x[i] 每个变量不确定是多少.
有 m 个约束,每个限制形如 (a, b, c) 表示 x[a]– x[b] <= c 或者 >= c.
然后让你求一组 x 的解使得满足所有约束或者给你 x[1 ], 让你最小/大化 x[n].
对于每个约束条件 x[a] – x[b] <= c,可以变形为 x[a] <= x[b] +c.
我们发现即 x[a] 要比所有 x[b]+c 的最小值还要小,这和最短路问题中求最短 路的松弛式子特别相似: dis[v]<=dis[u]+w.
因此,对于约束条件 x[a] – x[b] <= c,我们只需要从 b 向 a 连一条长度为 c
的边,然后建图跑最短路即可。
需要注意的是:
1、图中存在负环,则差分约束系统无解。
2、若没有确定的源点,可设虚点 0 为起点, dis[0] = 0, 以 0 为起点向每个点 连一条为 0 的边,跑单源最短路, dis[i] 即为 xi 的一组解。
3、若 {x1 , x2, …, xn} 是以一组解,则对于任意常数 d, {x1 +d, x2+d, …, xn+d} 也是差分约束系统的一组解。
4、若约束形容 x[a] – x[b] >=c, 即 x[a] >= x[b]+c. 我们也可由 b 向 a 连长度为 c 的边然后跑单源最长路即可,同理若存在正环则无解。也可以变形为 x[b]<= x[a] + (-c), 由 a 向 b 连一条 -c 的边,跑最短路。
5、最后差分约束系统解法从来不是难点,难点在于发现题目中的差分约束。
强连通分量
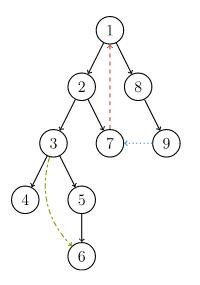
强连通分量就是一个点集,点集中的任意两个点都是可以互相到达的。 强连通分量是有向图算法,无向图不能跑的.、 首先要知道什么是dfs树
dfs树
dfs树就是遍历一个图的时候走过一个点就把这个点标记,标记的点不能走,这样dfs出一颗树来就叫
dfs树.
以右侧有向图为例, dfs树有: • 树枝边:图中以黑色边表示 搜索时找到一个未访问的节点形成。
• 前向边:图中以绿色边表示 搜索时遇到子树的节点形成。
• 后向边(返祖边):图中以红色边表示 搜索时发现有指向祖先节点的边。
• 横叉边:图中以蓝色边表示 搜索时遇到已访问的节点,且该节点不是当前节点的祖先。
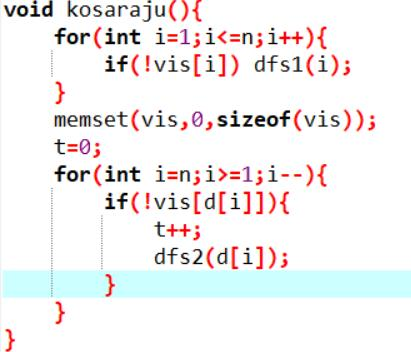
kosaraju算法求SCC
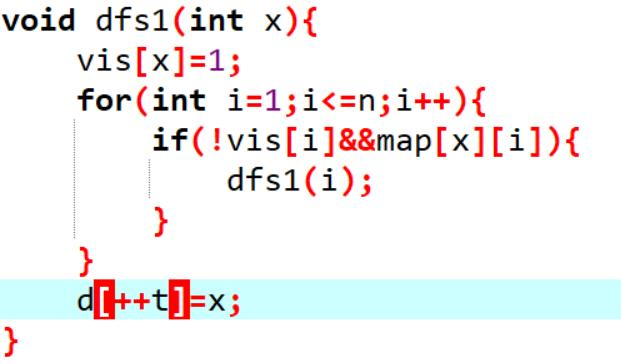
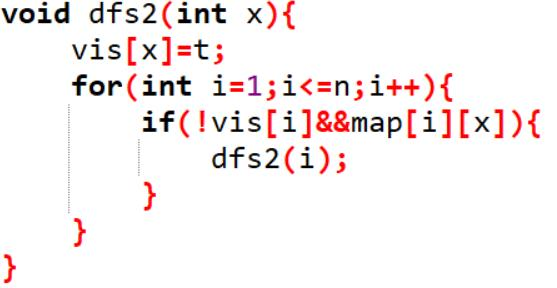
算法思路:
1、对原图跑 dfs,记录节点访问完成的顺序 d[i], d[i] 表示第 i 个访问完成的节点。
2、对反图 G’ 和 d[i] 的倒序再跑一次dfs,记录并删除遍历到的顶点,这些点构成一 个强连通分量。继续直到所有顶点删除为止。 换言之,其实就是原图跑dfs后得到dfs树的后序序列,然后每次在反图上对后序序列 的根节点跑dfs。
代码实现:
tarjan算法求SCC
tarjan算法指的是一系列算法,如求SCC、双连通分量、离线求LCA等。
tarjan算法在搜索时,把当前搜索树中未处理的节点加入一个堆栈,回溯时则 可以判断栈顶到栈中的节点是否为一个强连通分量。 因此算法过程中每个节点维护两个值,分别定义为:
dfn[u]: dfs遍历到该点的时间戳。
low[u]: u号点或以其为根的子树中的节点能返回的最早的栈中点的dfn值。
算法思路:
1、首次搜索到 u, 初始化 dfn[u], low[u].
2、将 u 入栈,递归子节点 v。
3、每次递归回溯回来根据不同情况更新 low[u]: 如果 (u, v) 为树枝边(不在栈中),则 low[u] = min(low[u], low[v])
如果 (u, v) 为返祖边或在栈中,则 low[u] = min(low[u], dfn[v]) 4、最后如果 low[u]==dfn[u],则 u 为强连通分量根节点,栈顶到 u 的所有节点都在 该连通分量中。 时间复杂度O(n+m).
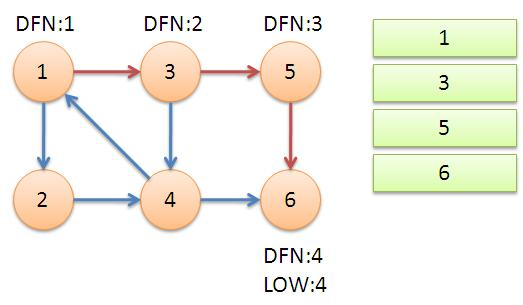
算法图示:
1、从节点1开始DFS,把遍历到的节点加入栈中。搜索到节点u=6时,
DFN[6]=LOW[6],找到了一个强连通分量。退栈到u=v为止, {6}为一个强连 通分量。
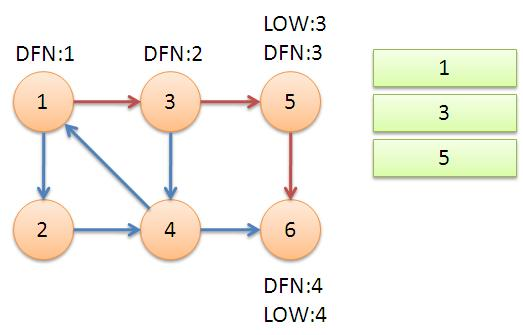
2、返回节点5,发现DFN[5]=LOW[5],退栈后{5}为一个强连通分量。
3、返回节点3,继续搜索到节点4,把4加入堆栈。发现节点4向节点1有后向 边,节点1还在栈中,所以LOW[4]=1。节点6已经出栈, (4,6)是横叉边,返回3,(3,4)为树枝边,所以LOW[3]=LOW[4]=1。
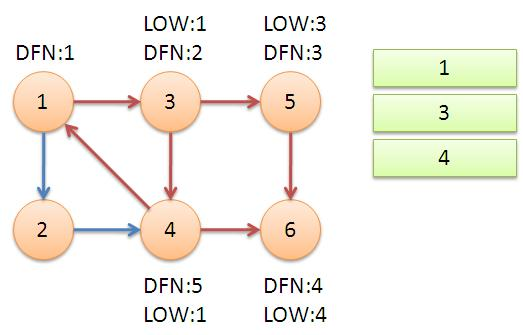
4、继续回到节点1,最后访问节点2。访问边(2,4), 4还在栈中,所以
LOW[2]=DFN[4]=5。返回1后,发现DFN[1 ]=LOW[1 ],把栈中节点全部取出 ,组成一个连通分量{1 ,3,4,2}。
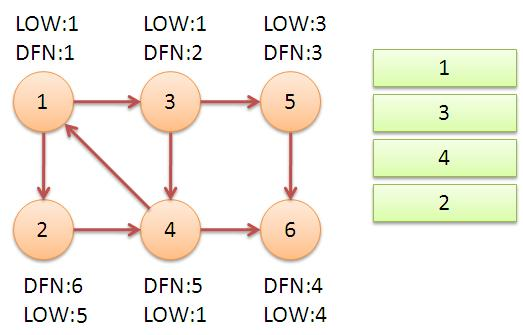
至此,算法结束。经过该算法,求出了图中全部的三个强连通分量 {1 ,3,4,2}, {5}, {6}
。 可以发现,运行Tarjan算法的过程中,每个顶点都被访问了一次,且只进出了一次堆 栈,每条边也只被访问了一次,所以该算法的时间复杂度为O(N+M)。 与 Kosaraju 算法相比, Tarjan 只用对原图进行一次 DFS,且不用建立逆图,更简洁 。在实际的测试中, Tarjan 算法的运行效率也比 Kosaraju 算法高30%左右。此外求
SCC 的 Tarjan 算法与求无向图的双连通分量(割点、桥)的 Tarjan 算法也有着很深的 联系。因此一般情况下只需要掌握 Tarjan 就行。(kosaraju 在顺带求拓扑排序更有 优势)
代码实现:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号