python爬取cvpr2018论文
摘要:爬取CVPR2018论文的标题、摘要、关键字、文章链接。
一、数据库建表

最好加id,方便管理,注意abstract(摘要)的类型为text。(原因:varchar默认长度255,摘要可能会溢出)
二、代码部分


import requests from bs4 import BeautifulSoup import pymysql headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息 url='http://openaccess.thecvf.com/CVPR2018.py' r=requests.get(url,headers=headers) content=r.content.decode('utf-8') soup = BeautifulSoup(content, 'html.parser') dts=soup.find_all('dt',class_='ptitle') hts='http://openaccess.thecvf.com/' #数据爬取 alllist=[] for i in range(len(dts)): print('这是第'+str(i)+'个') title=dts[i].a.text.strip() href=hts+dts[i].a['href'] r = requests.get(href, headers=headers) content = r.content.decode('utf-8') soup = BeautifulSoup(content, 'html.parser') #print(title,href) divabstract=soup.find(name='div',attrs={"id":"abstract"}) abstract=divabstract.text.strip() #print('第'+str(i)+'个:',abstract) alllink=soup.select('a') link=hts+alllink[4]['href'][6:] keyword=str(title).split(' ') keywords='' for k in range(len(keyword)): if(k==0): keywords+=keyword[k] else: keywords+=','+keyword[k] value=(title,abstract,link,keywords) alllist.append(value) print(alllist) tuplist=tuple(alllist) #数据保存 db = pymysql.connect("localhost", "root", "0000", "cvpr", charset='utf8') cursor = db.cursor() sql_cvpr = "INSERT INTO cvpr values (%s,%s,%s,%s)" try: cursor.executemany(sql_cvpr,tuplist) db.commit() except: print('执行失败,进入回调3') db.rollback() db.close()
三、爬取结果
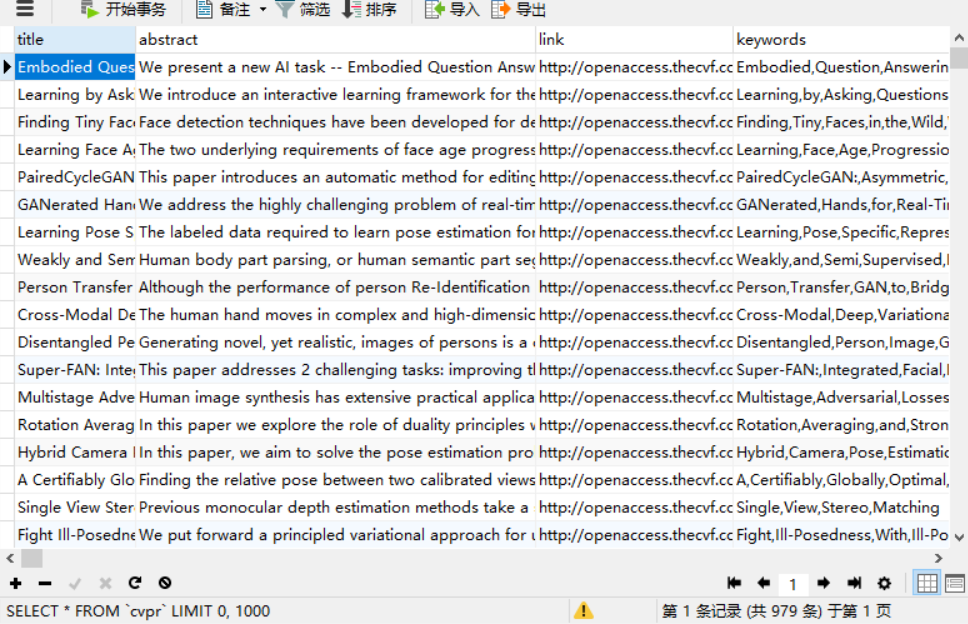

 浙公网安备 33010602011771号
浙公网安备 33010602011771号