[SNOI2019]通信
题面

样例
输入 #1
6 7
8 4 6 1 3 0
输出 #1
23
输入 #2
8 4
0 4 2 6 1 5 3 7
输出 #2
18

题解
先说明了,应该可以不难看出这是一道 有源汇 有上下界 最小费用可行流 的题。
网络流不会的自行学习一下:OID的神仙博客,以及费用流:
万能WIKI
还有这题必要的,上下界网络流和费用流:不亚于OID的学长博客
不多说,咱们进入正题,先说如何建图。
初步建图
第一行题面暗含的意思告诉我们第一个条件,每个哨站都得且仅能被通信一次
咱们先建一条上下界均为 1 的边来表示每个哨站,并没有显示来源,其代价为零
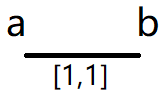
第二个条件,这一单位的流量可以从控制中心
s
s
s 流过来,代价为
W
W
W
然后,这个哨站的频段可以不分享出去,当作分享给了空气吧,连向
t
t
t 来回收流量,自然无代价。
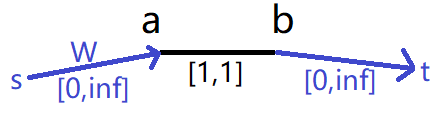
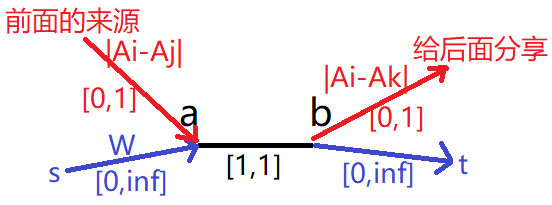
第三个条件,这一单位的流量可以从前面哨站的分享得来,
由于自己肯定会有这一份流量,所以可以当作是这份流量分享给了后面的一个哨站,上界是 1 ,代价如题,把所有的贡献关系连成边。
好,我们基本的建图思路已经理清了,
接下来就是有上下界有源汇的套路,建超极原点超级汇点,从尾向头连成个环,跑EK…

但是我们发现会 T ,原因是它的边数达到了
n
2
n^2
n2 级别,再加上 E_K 算法本身不如 dinic 优,跑不过难道不是必然的结果吗?
限于我们没有找到更优的费用流算法,我们选择优化建图。
优化建图
其实之前我们做最大流时以及一些其它图论题时用到过这种思路,就是利用边之间的规律,把它们拍在数据结构上,利用数据结构点数边数的双优性优化建图。
但是这道题不简单,每条边的代价跟两个点都有关,而且怕过于简单还给你加了个绝对值符号(其实这应该是为了防止产生负环,毕竟最终要把原图拼成个强连通分量),我们只好分情况把这个贡献拆开。
令 j < i j < i j<i
- a i < a j a_i<a_j ai<aj,即 ∣ a i − a j ∣ = a j − a i |a_i-a_j|=a_j-a_i ∣ai−aj∣=aj−ai ,那么 j 向后连出一条上界为 1 ,代价为 a j a_j aj 的边,i 向前连出一条上界为 1 ,代价为 − a i -a_i −ai 的边。
- a i > a j a_i>a_j ai>aj,即 ∣ a i − a j ∣ = a i − a j |a_i-a_j|=a_i-a_j ∣ai−aj∣=ai−aj ,那么 j 向后连出一条上界为 1 ,代价为 − a j -a_j −aj 的边,i 向前连出一条上界为 1 ,代价为 a i a_i ai 的边。
由于每个点可能向前连到很多前驱,也有很多后继自己可以分享,因此我们先把上述四条边都建出来再说(哪四条边?)
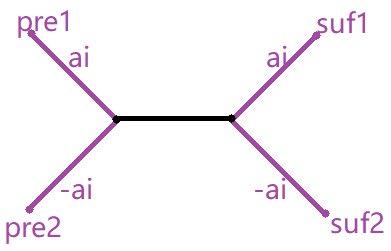
于是现在,有很多 suf1 要连向 pre2,有很多 suf2 要连向 pre1 ,它们的
a
a
a 值都在一段连续的区间内,因此,我们不妨建一个数据结构,以分块为例。
可持久化分块
把 a a a 值离散化后,根据 a a a 值来值域分块, n \sqrt{n} n 个区间分别存当前的这个块统领块内节点的点编号(有点抽象),即把当前版本(可持久化,懂?)加到这个块内的所有 suf 点都向这个节点连一条流量无穷、代价为零的边,这个点可以代表这些节点跟后面的 pre 连一条边。
可持久化也很简单,每次新加入一个点时把所在的块连向新建的该块的代表点,再把加入的点连向该新点。
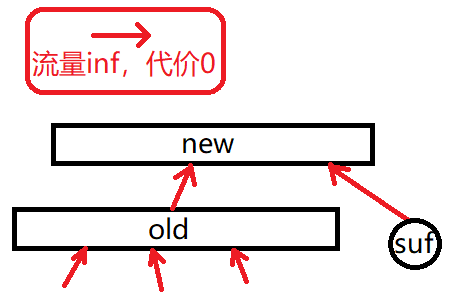
由于是有向图,所以不影响
[
o
l
d
]
[old]
[old] 连出去的其他边。
然后针对 suf1[] 和 suf2[] 分别建两个分块数组维护,再连向 pre2[] 和 pre1[] 就类似分块的区间查询了。
CODE
具体详见代码吧,可能解释的不是很清楚。
#include<ctime>
#include<cmath>
#include<queue>
#include<cstdio>
#include<vector>
#include<cstring>
#include<iostream>
#include<algorithm>
using namespace std;
#define LL long long
#define MAXN 1000005
#define MAXM 1000005
#define DB double
#define ENDL putchar('\n')
#define INF ((LL)1e18)
LL read() {
LL f=1,x=0;char s = getchar();
while(s < '0' || s > '9') {if(s=='-')f = -f;s = getchar();}
while(s >= '0' && s <= '9') {x=x*10+(s-'0');s = getchar();}
return f * x;
}
const int MOD = 1000000007;
int n,m,s,i,j,o,k;
int hd[MAXN],vv[MAXM<<1],ne[MAXM<<1],ni[MAXM<<1],ce;
LL w[MAXM<<1],co[MAXM<<1];
int addedge(int x,int y,LL w1,LL cos) {
vv[++ ce] = y; w[ce] = w1; ne[ce] = hd[x]; hd[x] = ce;
vv[++ ce] = x; w[ce] = 0; ne[ce] = hd[y]; hd[y] = ce;
co[ce-1] = cos; co[ce] = -cos;
ni[ce] = ce-1; ni[ce-1] = ce; return ce-1;
}
int S,T,cn;
LL d[MAXN],fl[MAXN];
int pre[MAXN],pe[MAXN];
bool vis[MAXN];
int b[1000005],hed,tal;
void RAND() {
int x = rand()%(tal - hed + 1) + hed;
int y = rand()%(tal - hed + 1) + hed;
swap(b[x],b[y]); return ;
}
bool bfs_EK() {
hed = 1;tal = 0;
for(int i = 1;i <= cn;i ++) d[i] = INF,fl[i] = INF,vis[i] = 0;
d[S] = 0; b[++ tal] = S; vis[S] = 1; pre[T] = -1; fl[S] = INF;
while(hed <= tal) {
int t = b[hed ++];
vis[t] = 0;
for(int i = hd[t];i;i = ne[i]) {
int y = vv[i];
if(w[i] > 0 && d[y] > d[t] + co[i]) {
fl[y] = min(fl[t],w[i]);
d[y] = d[t] + co[i];
pre[y] = t; pe[y] = i;
if(!vis[y]) vis[y] = 1,b[++ tal] = y;
}
}
}
return pre[T] >= 0;
}
void EK(LL &maxflow,LL &mincost) {
maxflow = 0; mincost = 0;
while(bfs_EK()) {
maxflow += fl[T];
mincost += fl[T] * d[T];
int p = T;
while(p != S) {
w[pe[p]] -= fl[T];
w[ni[pe[p]]] += fl[T];
p = pre[p];
}
}
return ;
}
// 以上为 EK 板子
struct it{
int nm,id;
}q[1005];
bool cmp(it a,it b) {return a.nm < b.nm;}
int a[1005],ar[1005],NM;
// 离散化,存到 ar[] 里
int lp[1005],rp[1005];
int p1[1005],p2[1005]; // pre1,pre2
int s1[1005],s2[1005]; // suf1,suf2
int bl1[1005],bl2[1005],sq,is1[1005],is2[1005]; // bl1,bl2 存该块的代表点,is1,is2 存已经放进去的 suf
void upd(int &bl) { // 块的 “版本更新”
int pr = bl; bl = ++ cn;
if(pr) addedge(pr,bl,INF,0); return ;
}
void ins(int *bl,int *is,int ad,int id) { // 插入
upd(bl[ad/sq]); addedge(id,bl[ad/sq],INF,0); is[ad] = id;
}
void link(int *bl,int *is,int l,int r,int id) { // 连边,"id" 就是放进来的 pre
if(l > r) return ;
int ll = l/sq,rr = r/sq;
if(ll == rr) {
for(int i = l;i <= r;i ++)
if(is[i]) addedge(is[i],id,INF,0);
return ;
}
for(int i = l;i/sq == ll;i ++)
if(is[i]) addedge(is[i],id,INF,0);
for(int i = r;i/sq == rr;i --)
if(is[i]) addedge(is[i],id,INF,0);
for(int i = ll+1;i < rr;i ++)
if(bl[i]) addedge(bl[i],id,INF,0);
return ;
}
// 分块
int main() {
n = read();
LL Wi = read();
ce = cn = 0;
int st = ++ cn;S = ++ cn;T = ++ cn;
// 因为反正要从 t 向 s 连条边构成循环,又不拆,干脆合并成一个点 st 了
for(int i = 1;i <= n;i ++) {
a[i] = read();
lp[i] = ++ cn; rp[i]= ++ cn;
addedge(S,rp[i],1,0);
addedge(lp[i],T,1,0);
addedge(st,lp[i],1,Wi);
addedge(rp[i],st,1,0);
p1[i] = ++ cn; p2[i] = ++ cn;
s1[i] = ++ cn; s2[i] = ++ cn;
addedge(p1[i],lp[i],1,a[i]);
addedge(p2[i],lp[i],1,-a[i]);
addedge(rp[i],s1[i],1,a[i]);
addedge(rp[i],s2[i],1,-a[i]);
q[i].nm = a[i]; q[i].id = i;
}
// 输入,以及初始每个哨站的五条边
sort(q + 1,q + 1 + n,cmp);
NM = 0;
for(int i = 1;i <= n;i ++) {
if(i == 1 || q[i].nm > q[i-1].nm) NM ++;
ar[q[i].id] = NM;
}
// 离散化
sq = sqrt((DB)NM);
for(int i = 1;i <= n;i ++) {
link(bl2,is2,1,ar[i]-1,p1[i]);
link(bl1,is1,ar[i],NM,p2[i]);
ins(bl1,is1,ar[i],s1[i]);
ins(bl2,is2,ar[i],s2[i]);
}
// 分块建边
LL as1,as2;
EK(as1,as2);
printf("%lld\n",as2);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号