随笔分类 - DL
deep learning
摘要:Diffusion Model理解 整体理解 从右向左是正向过程,\(q(x_t|x_{t-1})\) 是加噪声的过程,可以直接获知,\(q(x_{t-1}|x_t)\) 是我们想要做的建楼操作,需要通过训练模型\(p_\theta(x_{t-1}|x_t)\) 来估计 Weng, Lilian.
阅读全文
摘要:[toc] 本文目的是认识sklearn库的一些基本概念,了解sklearn提供的常用功能。 # 官方网站 * Getting Start:https://scikit-learn.org/stable/getting_started.html * sklearn主页:https://scikit-
阅读全文
摘要:目录源码拷贝虚拟环境VSCode带命令行参数运行py文件txt2imgimg2img问题记录 此方式在服务器(Ubuntu)上安装Stable Diffusion,使用miniconda虚拟环境。在Windows10系统上使用VScode远程开发方法进行调试和运行。 注意:使用VSCode连接服务器
阅读全文
摘要: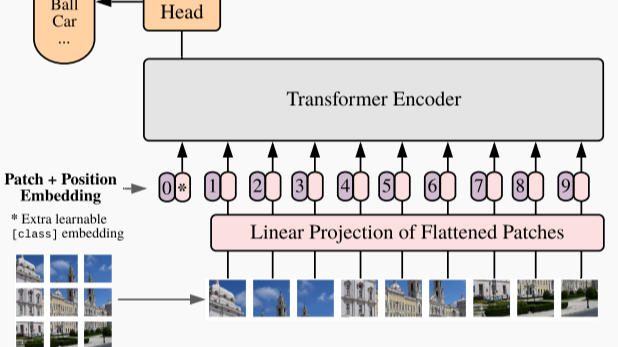 **Vision Transformer** 本文关注ViT论文`4.5 Inspecting Vision Transformer`可视化的原理及实现,此外还对ViT pytorch源码实现进行理解 [toc] # Introduction [论文地址](arXiv:2010.11929) ##
阅读全文
**Vision Transformer** 本文关注ViT论文`4.5 Inspecting Vision Transformer`可视化的原理及实现,此外还对ViT pytorch源码实现进行理解 [toc] # Introduction [论文地址](arXiv:2010.11929) ##
阅读全文
**Vision Transformer** 本文关注ViT论文`4.5 Inspecting Vision Transformer`可视化的原理及实现,此外还对ViT pytorch源码实现进行理解 [toc] # Introduction [论文地址](arXiv:2010.11929) ##
阅读全文
摘要:arXiv:1706.03762 # 1. 问题提出 全连接神经网络(FCN),可以很好的处理输入为1个向量(特征向量)的情况,但是如果输入是一组向量,FCN处理起来不太方便 以词性标记的问题为例 对于处于同一个句子中的相同的2个单词`saw`,词性不同,前者为动词(V),后者为名词(N) 如果尝试
阅读全文
摘要:Recurrent Neural Network(RNN) # 1.问题提出 想要对一个句子中的单词,对其语义进行标记,如下两个句子,相同单词`Taipei`,在第1句中的语义是目的地(dest),在第2个句子中的语义是出发地(place of departure) 对于句子输入问题,可以将单词转变
阅读全文
摘要:# 1. 概述 图像生成任务:给定一段文字,模型根据文字描述产生图片 ## 1.1 图像生成方式 * 一次生成一个pixel 像Transformer接龙那样,一次生成一个pixel,然后作为下一个pixel的输入,这样依次生成一张图像的所有pixel * 一次生成整张图片的所有pixel 每一个p
阅读全文
摘要:# 1.概念 ## 1.1 数据增强 Data Augmentation,训练过程中经常使用数据增强技术 > 大型数据集是成功应用深度神经网络的先决条件。 图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而**扩大了训练集的规模**。 此外,应用图像增广的原因是,**随机改
阅读全文
摘要:vscode配置远端服务器深度学习项目 # 1.安装vscode 官网地址:https://code.visualstudio.com/ 下载安装程序,运行安装即可 # 2.连接服务器 ## 2.1 安装相关插件 需要安装 `Remote - SSH` 和 `Remote Development`
阅读全文
摘要:1.问题提出 想要对一个句子中的单词,对其语义进行标记,如下两个句子,相同单词Taipei,在第1句中的语义是目的地(dest),在第2个句子中的语义是出发地(place of departure) 对于句子输入问题,可以将单词转变为一个向量,再进行输入 尝试使用神经网络处理这个问题,但对于相同的输
阅读全文
摘要:错误率与精度 常用于分类问题 错误率 精度 查准率、查全率与F~β~ 混淆矩阵 以二分类为例,T:True,预测正确;F:False,预测错误;P:Positive,正样本;N:Negative,负样本 TP True Positive,正确预测样本为正,实际就是正样本 FP False Posit
阅读全文
摘要:HW2 任务描述 音位分类预测(Phoneme classification),我们有音频->音位这样的训练数据,想要训练一个模型,学习这样的对应关系,然后给定音频,预测其音位 音位 音位(phoneme),是人类某一种语言中能够区别意义的最小语音单位,是音位学分析的基础概念。每种语言都有一套自己的
阅读全文
摘要:Learning Rate 关于lr的问题 lr太小 模型收敛的很慢,时间开销大 lr太大 每次更新参数步子迈的很大,容易越过最优解 我们追求的是红色的情况 动态调整lr 基本原则:先大再小 在训练开始时,此时我们距离最优解还较远,lr可以设置稍大些,以较快的速度接近最优解。在训练的后期,此时我们已
阅读全文
摘要:HW1:Regression 任务描述 新冠检测预测:根据前4天的特征和核酸检测结果,预测第5天的核酸检测结果为阳性的可能性 数据 两个文件covid.train.csv和covid.test.csv train 2699x118,2699个样本,每个样本的118维特征包括 1:id,样本编号 37
阅读全文
摘要:numpy & pandas 介绍 & 安装 numpy 和 pandas 用于数据分析/处理 numpy基于C语言,pandas基于numpy,相比于python的字典/或列表,可以较快实现矩阵计算 numpy numpy的属性 ndim 矩阵的维度 shape 矩阵的形状(行-列) size 矩
阅读全文
摘要:什么是pytorch python机器学习框架,Facebook提出,主要有一下两个特点 使用GPU加速高维矩阵的运算 torch.cuda.is_available() x = x.to('cuda') 可以很方便的实现梯度的计算 requires_grad=True指定需要对变量x计算梯度 z是
阅读全文
摘要:数据集区分 参考:11 模型选择 + 过拟合和欠拟合【动手学深度学习v2】_哔哩哔哩_bilibili 训练数据集 相当于平时作业题/练习题,用来训练模型(梯度下降更新权重、偏置最小化代价函数) 验证数据集 相当于模拟考试,用来调参(超参数:learning rate、batch size) 测试数
阅读全文
摘要:损失函数 参考: “损失函数”是如何设计出来的?直观理解“最小二乘法”和“极大似然估计法”_哔哩哔哩_bilibili “交叉熵”如何做损失函数?打包理解“信息量”、“比特”、“熵”、“KL散度”、“交叉熵”_哔哩哔哩_bilibili 最小二乘法 所谓最小即梯度下降要找到使得损失函数最小的参数W和
阅读全文
摘要:正则化技术 # 1.过拟合 正则化技术用来防止过拟合。 所谓过拟合即训练过程中,训练集上的误差持续减少,而与此同时测试集上的误差增大的现象。 目标是追求模型对于没有见过的数据的预测效果(即泛化能力),而不是追求完全拟合训练数据 防止过拟合的方法 * 获取更多的数据 * 选择更合适的网络模型 * 早停
阅读全文
摘要:参考: 【 深度学习李宏毅 】 Batch Normalization (中文)bilibili 7.5. 批量规范化 — 动手学深度学习 2.0.0 documentation (d2l.ai) 3.6 Batch Norm 为什么奏效?- 吴恩达_bilibili 《Batch Normaliz
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号