手把手教你使用Python抓取QQ音乐数据(第四弹)
【一、项目目标】
通过手把手教你使用Python抓取QQ音乐数据(第一弹)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名、专辑名、播放链接。
通过手把手教你使用Python抓取QQ音乐数据(第二弹)我们实现了获取 QQ 音乐指定歌曲的歌词和指定歌曲首页热评。
通过手把手教你使用Python抓取QQ音乐数据(第三弹)我们实现了获取更多评论并生成词云图。
此次我们将将三个项目封装在一起,通过菜单控制爬取不同数据。
【二、需要的库】
主要涉及的库有:requests、openpyxl、html、json、wordcloud、jieba
如需更换词云图背景图片还需要numpy库和PIL库(pipinstall pillow)
如需生成.exe需要pyinstaller -F
【三、项目实现】
1.首先确定菜单,要实现哪些功能:
①获取指定歌手的歌曲信息(歌名、专辑、链接)
②获取指定歌曲歌词
③获取指定歌曲评论
④生成词云图
⑤退出系统
代码如下:
class QQ():
def menu(self):
print('欢迎使用QQ音乐爬虫系统,以下是功能菜单,请选择。\n')
while True:
try:
print('功能菜单\n1.获取指定歌手的歌曲信息\n2.获取指定歌曲歌词\n3.获取指定歌曲评论\n4.生成词云图\n5.退出系统\n')
choice = int(input('请输入数字选择对应的功能:'))
if choice == 1:
self.get_info()
elif choice == 2:
self.get_id()
self.get_lyric()
elif choice == 3:
self.get_id()
self.get_comment()
elif choice == 4:
self.wordcloud()
elif choice == 5:
print('感谢使用!')
break
else:
print('输入错误,请重新输入。\n')
except:
print('输入错误,请重新输入。\n')
第一行创建类,第二行定义菜单函数,这里用了类的实例化,里面所有函数的第一个参数都是self,我认为实例化更方便传参数;
whiletrue使菜单无限循环;
Try...except...使循环不会因报错而退出;
其他代码为设置输入不同数字对应打开不同函数。
2.封装项目(一)为get_info()
代码如下:
def get_info(self):
wb=openpyxl.Workbook()
/#创建工作薄
sheet=wb.active
/#获取工作薄的活动表
sheet.title='song'
/#工作表重命名
sheet['A1'] ='歌曲名' /#加表头,给A1单元格赋值
sheet['B1'] ='所属专辑' /#加表头,给B1单元格赋值
sheet['C1'] ='播放链接' /#加表头,给C1单元格赋值
url = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
name = input('请输入要查询的歌手姓名:')
page = int(input('请输入需要查询的歌曲页数:'))
for x in range(page):
params = {
'ct':'24',
'qqmusic_ver': '1298',
'new_json':'1',
'remoteplace':'sizer.yqq.song_next',
'searchid':'64405487069162918',
't':'0',
'aggr':'1',
'cr':'1',
'catZhida':'1',
'lossless':'0',
'flag_qc':'0',
'p':str(x+1),
'n':'20',
'w':name,
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0'
}
res = requests.get(url,params=params)
json = res.json()
list = json['data']['song']['list']
for music in list:
song_name = music['name']
/# 查找歌曲名,把歌曲名赋值给song_name
album = music['album']['name']
/# 查找专辑名,把专辑名赋给album
link = 'https://y.qq.com/n/yqq/song/' + str(music['mid']) + '.html\n\n'
/# 查找播放链接,把链接赋值给link
sheet.append([song_name,album,link])
/# 把name、album和link写成列表,用append函数多行写入Excel
wb.save(name+'个人单曲排行前'+str(page/*20)+'清单.xlsx')
/#最后保存并命名这个Excel文件
print('下载成功!\n')
3.封装项目(二)为get_id()和get_lyric
代码如下:
def get_id(self):
self.i = input('请输入歌曲名:')
url_1 = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
/# 这是请求歌曲评论的url
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
params = {'ct': '24', 'qqmusic_ver': '1298', 'new_json': '1', 'remoteplace': 'txt.yqq.song', 'searchid': '71600317520820180', 't': '0', 'aggr': '1', 'cr': '1', 'catZhida': '1', 'lossless': '0', 'flag_qc': '0', 'p': '1', 'n': '10', 'w': self.i, 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'utf-8', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0'}
res_music = requests.get(url_1,headers=headers,params=params)
json_music = res_music.json()
self.id = json_music['data']['song']['list'][0]['id']
/# print(self.id)
def get_lyric(self):
url_2 = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_yqq.fcg'
/# 这是请求歌曲评论的url
headers = {
'origin':'https://y.qq.com',
'referer':'https://y.qq.com/n/yqq/song/001qvvgF38HVc4.html',
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
params = {
'nobase64':'1',
'musicid':self.id,
'-':'jsonp1',
'g_tk':'5381',
'loginUin':'0',
'hostUin':'0',
'format':'json',
'inCharset':'utf8',
'outCharset':'utf-8',
'notice':'0',
'platform':'yqq.json',
'needNewCode':'0',
}
res_music = requests.get(url_2,headers=headers,params=params)
js_1 = res_music.json()
lyric = js_1['lyric']
lyric_html = html.unescape(lyric) /#用了转义字符html.unescape方法
/# print(lyric_html)
f1 = open(self.i+'歌词.txt','a',encoding='utf-8') /#存储到txt中
f1.writelines(lyric_html)
f1.close()
print('下载成功!\n')
这里特别说一下下载歌词的headers里必须加上’origin’和’referer’,要不爬下来数据。
4.封装项目(三)为get_comment()和wordcloud()
代码如下:
def get_comment(self):
page = input('请输入要下载的评论页数:')
url_3 = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
f2 = open(self.i+'评论.txt','a',encoding='utf-8') /#存储到txt中
for n in range(int(page)):
params = {'g_tk_new_20200303': '5381', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'GB2312', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0', 'cid': '205360772', 'reqtype': '2', 'biztype': '1', 'topid': self.id, 'cmd': '6', 'needmusiccrit': '0', 'pagenum':n, 'pagesize': '15', 'lasthotcommentid':'', 'domain': 'qq.com', 'ct': '24', 'cv': '10101010'}
res_music = requests.get(url_3,headers=headers,params=params)
js_2 = res_music.json()
comments = js_2['comment']['commentlist']
for i in comments:
comment = i['rootcommentcontent'] + '\n——————————————————————————————————\n'
f2.writelines(comment)
/# print(comment)
f2.close()
print('下载成功!\n')
def wordcloud(self):
self.name = input('请输入要生成词云图的文件名称:')
def cut(text):
wordlist_jieba=jieba.cut(text)
space_wordlist=" ".join(wordlist_jieba)
return space_wordlist
with open(self.name+".txt" ,encoding="utf-8")as file:
text=file.read()
text=cut(text)
mask_pic=numpy.array(Image.open("心.png"))
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
collocations=False,
max_words= 100,
min_font_size=10,
max_font_size=500,
mask=mask_pic).generate(text)
wordcloud.to_file(self.name+'云词图.png') /# 把词云保存下来
print('生成成功!\n')
5.最后类的实例化
qq = QQ()
qq.menu()
6.效果展示








- 打包成.exe
用pyinstaller -F打包,运行会报错、闪退。

看上图报错信息应该和词云图有关,注释掉词云图所需的库,def wordcloud()按下图修改可正常打包,但是就没有生成词云图的功能了:


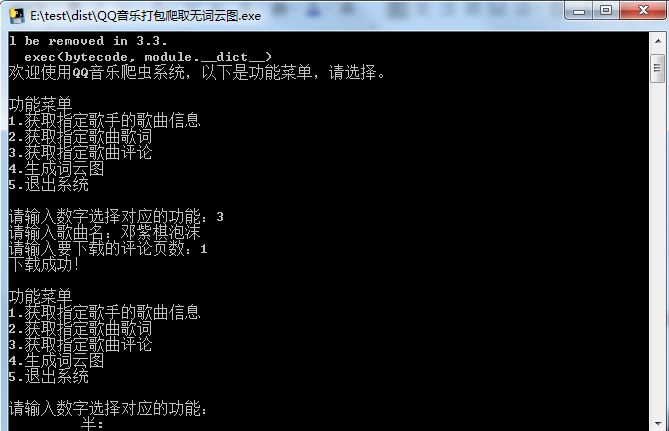
下载歌词或评论时,如有重名的歌曲,可在歌曲前面加上歌手姓名,如上图的“邓紫棋泡沫”。
【四、总结】
1.项目四对前三个项目进行了复习,在巩固了爬虫知识点的同时又复习了类的相关用法;
2.前三个项目可自行戳;文章进行学习:手把手教你使用Python抓取QQ音乐数据(第一弹)、手把手教你使用Python抓取QQ音乐数据(第二弹)、手把手教你使用Python抓取QQ音乐数据(第三弹)。
3.感谢观看,写百行以上的代码是不是轻轻松松呢。祝小伙伴们学业有成,工作顺利!
4.如果需要本文源码的话,请在公众号后台回复“QQ音乐”四个字进行获取,觉得不错,记得给个star噢。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号