手把手教你使用Python抓取QQ音乐数据(第三弹)
【一、项目目标】
通过手把手教你使用Python抓取QQ音乐数据(第一弹)我们实现了获取 QQ 音乐指定歌手单曲排行指定页数的歌曲的歌名、专辑名、播放链接。
通过手把手教你使用Python抓取QQ音乐数据(第二弹)我们实现了获取 QQ 音乐指定歌曲的歌词和指定歌曲首页热评。
此次我们在项目(二)的基础上获取更多评论并生成词云图,形成手把手教你使用Python抓取QQ音乐数据(第三弹)。
【二、需要的库】
主要涉及的库有:requests、json、wordcloud、jieba
如需更换词云图背景图片还需要numpy库和PIL库(pipinstall pillow)
【三、项目实现】
1.首先回顾一下,下面是项目(二)获取指定歌曲首页热评的代码;
def get_comment(i):
url_3 = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
/# 标记了请求从什么设备,什么浏览器上发出
}
params = {'g_tk_new_20200303': '5381', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'GB2312', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0', 'cid': '205360772', 'reqtype': '2', 'biztype': '1', 'topid': id, 'cmd': '8', 'needmusiccrit': '0', 'pagenum': '0', 'pagesize': '25', 'lasthotcommentid': '', 'domain': 'qq.com', 'ct': '24', 'cv': '10101010'}
res_music = requests.get(url_3,headers=headers,params=params)
/# 发起请求
js_2 = res_music.json()
comments = js_2['hot_comment']['commentlist']
f2 = open(i+'评论.txt','a',encoding='utf-8') /#存储到txt中
for i in comments:
comment = i['rootcommentcontent'] + '\n——————————————————————————————————\n'
f2.writelines(comment)
/# print(comment)
f2.close()
2.下面来考虑如何获取后面的评论,下图是项目(二)评论页面的parms参数;
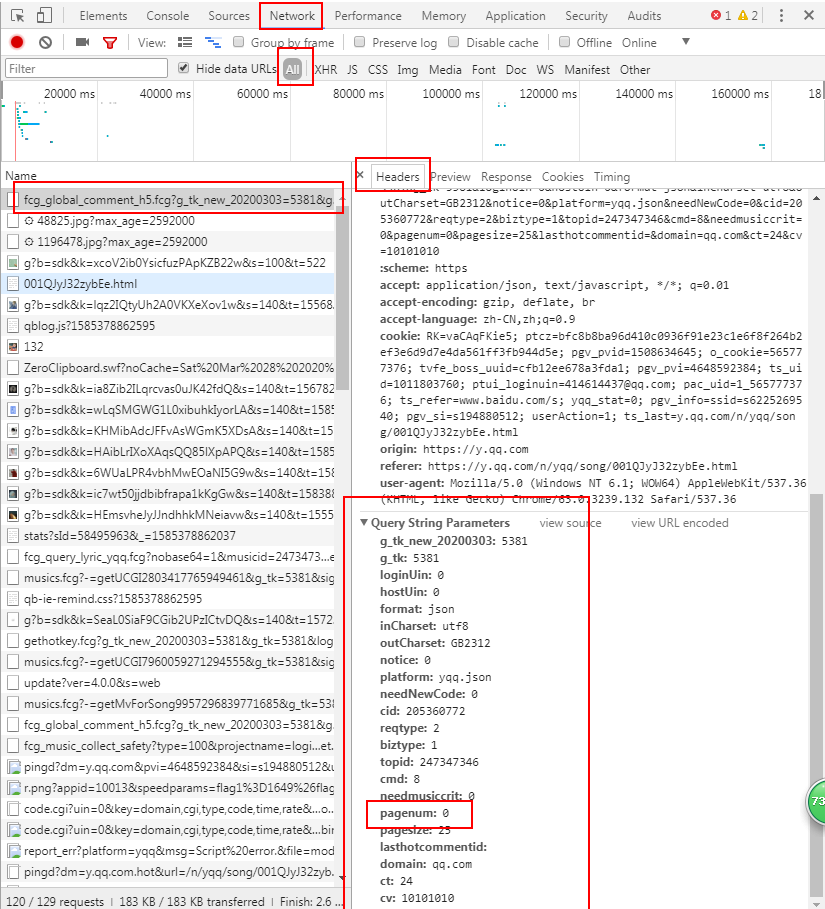
3.网页无法选择评论的页码,想看后面的评论智能一次一次的点击“点击加载更多”;我们可以点击一下看看parms有什么变化。
4.这里有个小技巧,先点击下图所示clear按钮,把network界面清空,再点击“点击加载更多”,就能直接找到第二页的数据。

5.点击加载更多后出现下图。
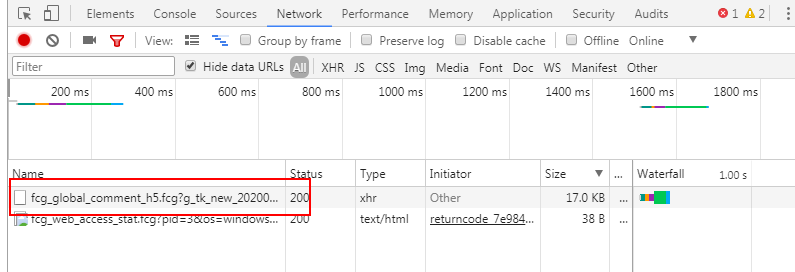
6.发现不止pagenum变了,cmd和pagesize也变了,到底那个参数的问题呢,那我们再看下第三页;

7.只有pagenum变了,那我们尝试一下把pagenum改成“0”,其他不变,能正常显示第一页数据吗?
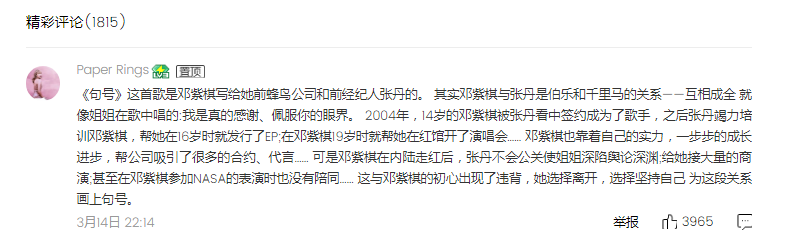
第一页第一条评论

第一页最后一条评论。
8.能正常显示,那就确定思路了:用第二页的parms,写一个for循环赋值给pagenum,参考项目(二)把评论抓取到txt。
9.代码实现:为了不给服务器造成太大压力,我们本次只爬取20页数据。
import requests,json
def get_id(i):
global id
url_1 = 'https://c.y.qq.com/soso/fcgi-bin/client_search_cp'
/# 这是请求歌曲评论的url
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
params = {'ct': '24', 'qqmusic_ver': '1298', 'new_json': '1', 'remoteplace': 'txt.yqq.song', 'searchid': '71600317520820180', 't': '0', 'aggr': '1', 'cr': '1', 'catZhida': '1', 'lossless': '0', 'flag_qc': '0', 'p': '1', 'n': '10', 'w': i, 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'utf-8', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0'}
res_music = requests.get(url_1,headers=headers,params=params)
json_music = res_music.json()
id = json_music['data']['song']['list'][0]['id']
return id
/# print(id)
def get_comment(i):
url_3 = 'https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
f2 = open(i+'评论.txt','a',encoding='utf-8') /#存储到txt中
for n in range(20):
params = {'g_tk_new_20200303': '5381', 'g_tk': '5381', 'loginUin': '0', 'hostUin': '0', 'format': 'json', 'inCharset': 'utf8', 'outCharset': 'GB2312', 'notice': '0', 'platform': 'yqq.json', 'needNewCode': '0', 'cid': '205360772', 'reqtype': '2', 'biztype': '1', 'topid': '247347346', 'cmd': '6', 'needmusiccrit': '0', 'pagenum':n, 'pagesize': '15', 'lasthotcommentid': 'song_247347346_3297354203_1576305589', 'domain': 'qq.com', 'ct': '24', 'cv': '10101010'}
res_music = requests.get(url_3,headers=headers,params=params)
js_2 = res_music.json()
comments = js_2['comment']['commentlist']
for i in comments:
comment = i['rootcommentcontent'] + '\n——————————————————————————————————\n'
f2.writelines(comment)
/# print(comment)
f2.close()
input('下载成功,按回车键退出!')
def main(i):
get_id(i)
get_comment(i)
main(i = input('请输入需要查询歌词的歌曲名称:'))
10.词云图代码
from wordcloud import WordCloud
import jieba
import numpy
import PIL.Image as Image /#以上两个库是为了更换词云图背景图片
def cut(text):
wordlist_jieba=jieba.cut(text)
space_wordlist=" ".join(wordlist_jieba)
return space_wordlist
with open("句号评论.txt" ,encoding="utf-8")as file:
text=file.read()
text=cut(text)
mask_pic=numpy.array(Image.open("心.png"))
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",
collocations=False,
max_words= 100,
min_font_size=10,
max_font_size=500,
mask=mask_pic).generate(text)
image=wordcloud.to_image()
/# image.show()
wordcloud.to_file('云词图.png') /# 把词云保存下来
11.成果展示
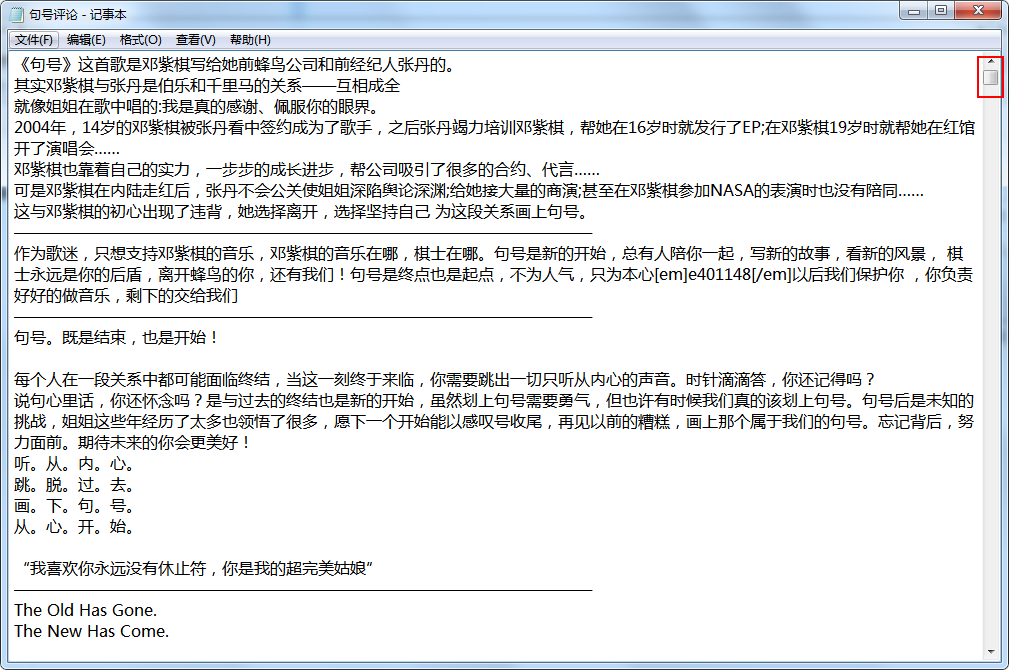
【四、总结】
1.项目三比项目二多的功能:一是通过寻找parms参数里每一页评论页码之间的关系,爬取更多的评论;二是学会生成词云图;(注意读取文件的路径)
2.WordCloud更多参数详见下图,可以研究出更多的玩法;
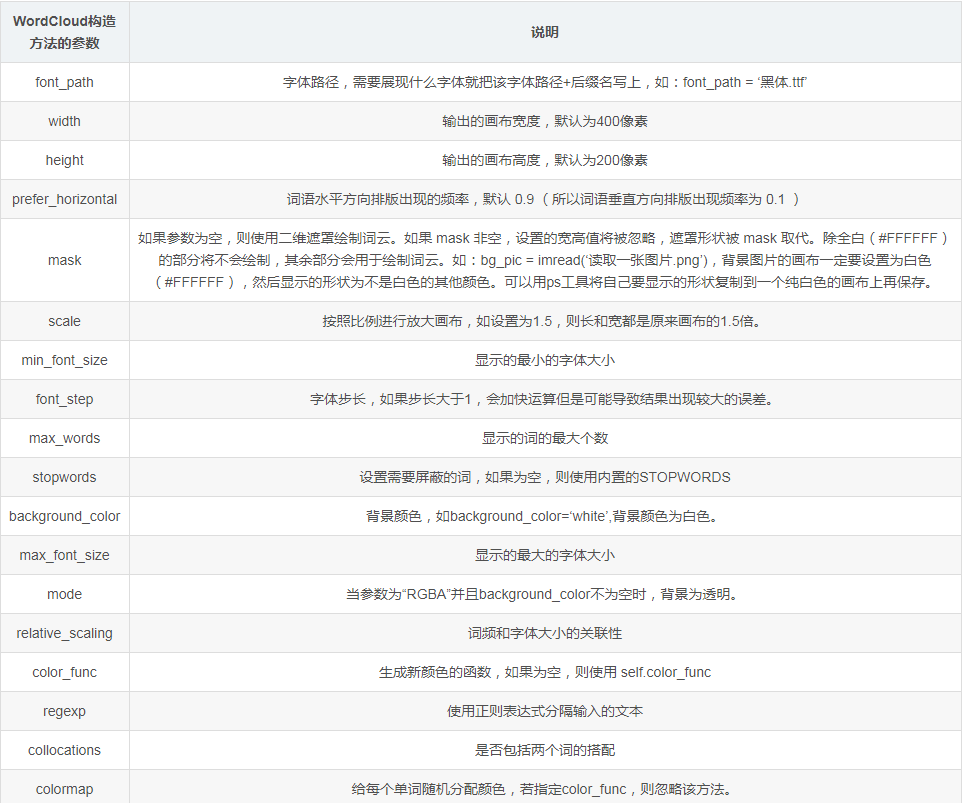
- 不只.txt可以作为词云图的数据源,csv、Excel也可以:
import xlrd
/#引入excel读取模块
datafile_path = '你的Excel文件.xlsx'
data = xlrd.open_workbook(datafile_path)
/#文件名以及路径
table = data.sheet_by_name('sheet')
/#/#通过名称获取Sheet1表格
nrows = table.nrows
/#获取该Sheet1中的有效行数
list = []
for i in range(nrows):
value = str(table.row_values(i)[1])
/# print(value)
list.append(value)
/# print(pingjia_list)
text = str(list).replace("'", '').replace(',', '').rstrip(']').lstrip('[')
/# print(text)
4.爬QQ音乐项目到此告一段落,如有需要的话可以通过Scrapy框架爬取更多的歌曲信息、歌词、评论。但是作为练手项目,重要的不是爬多少数据,而是学会如何爬取指定的数据。
5.第四弹小编将会把前面三个项目封装在一起,通过菜单控制爬取不同数据,敬请期待。
6.需要本文源码的话,请在公众号后台回复“QQ音乐”四个字进行获取。
看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】

想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号