|
|
| 这个作业属于哪个课程 |
计科国际班软工 |
| 这个作业要求在哪里 |
要求 |
| 这个作业的目标 |
论文查重程序 |
| 1.GitHub地址:(https://github.com/L-Cc26/3119009428) |
|
| 2.PSP表格 |
|
|
|
| ---- |
---- |
| PSP2.1 |
Personal Software Process Stages |
| Planning |
计划 |
| Estimate |
估计这个任务需要多少时间 |
| Development |
开发 |
| Analysis |
需求分析 (包括学习新技术) |
| Design Spec |
生成设计文档 |
| Design Review |
设计复审 |
| Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
| Design |
具体设计 |
| Coding |
具体编码 |
| Code Review |
代码复审 |
| Test |
测试(自我测试,修改代码,提交修改) |
| Reporting |
报告 |
| Test Repor |
测试报告 |
| Size Measurement |
计算工作量 |
| Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 |
| Sum up |
合计 |
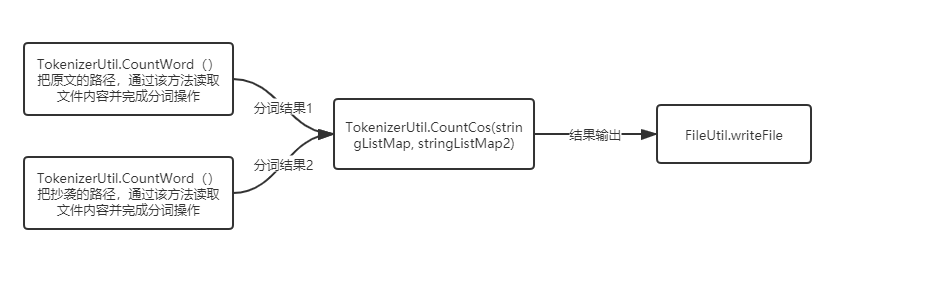
| 3.计算模块接口的设计与实现过程: |
|
| 流程图 |
|
![]() |
|
| 通过查找网上的资料,找到解决查重的关键算法,利用TF-IDF与余弦相似性的应用,主要说的是离用余弦相似性来比较两个句子的相似性, |
|
| 我们这里同样可以运用到文章上面,主要是用位置向量分析每个词全文的分布,从而分析两篇文章的相似度。用到的是hanlp分词。 |
|
| 然后遍历存放着词与词频信息的map,计算cos值。最后比对得出答案。 |
|
| 文件读写类,分词与计算类,异常类分别如下 |
|
![]() |
|
| 引用了里面的FileReader,然后对异常进行了封装 |
|
![]() |
|
| 引入了TokenizerEngine,并通过hankcs当作引擎来进行分词处理。 |
|
![]() |
|
| 4.部分代码展示与测试: |
|
| 测试分别从两个完全相同的文件和完全不同的文件,到5个测试用例去测试。 |
|
| 同时也测试了假如文件路径有问题和文件为空,也考虑到了各种异常的情况。 |
|
![]() |
|
![]() |
|
![]() |
|
| 覆盖率: |
|
![]() |
|
![]() |
|
| 总方法覆盖率为77%,line覆盖率达到了93% |
|
| 结果: |
|
| orig_0.8_add.txt 0.8695990639733713 |
|
| orig_0.8_del.txt 0.7498838191640381 |
|
| orig_0.8_dis_1.txt 0.9206491294709916 |
|
| orig_0.8_dis_10.txt 0.804067893296461 |
|
| orig_0.8_dis_15.txt 0.6575365154781483 |
|
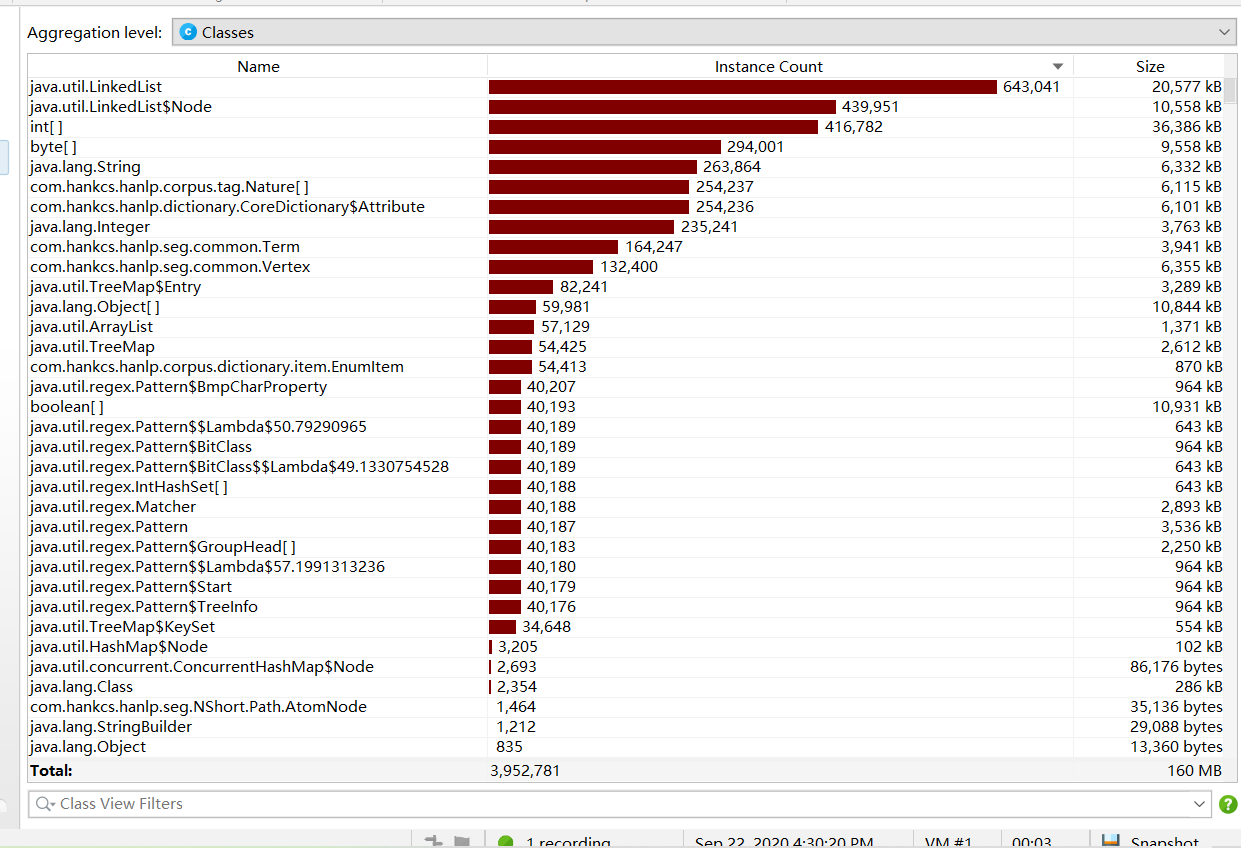
| 5.计算模块接口部分的性能 |
|
![]() |
|
![]() |
|
| 速度很快就完成了测试3s。 |
|
| 反思:可以优化的地方还有很多,比如简化输入路径,如输入名字即可找到文件,加快程序总运行速度。 |
|
还有一个问题,假如有两个句子,遍历只遍历到了第一个句子有的词。第二个句子有的词但第一个句子没有的词,并不会加入到计算中。
这样是采用位置向量的缺陷,以后可以改进。










 浙公网安备 33010602011771号
浙公网安备 33010602011771号